Welcome to Paddle-Inference’s documentation!¶
飞桨推理产品简介¶
作为飞桨生态重要的一部分,飞桨提供了多个推理产品,完整承接深度学习模型应用的最后一公里。
整体上分,推理产品主要包括如下子产品
| 名称 | 英文表示 | 适用场景 |
|---|---|---|
| 飞桨原生推理库 | Paddle Inference | 高性能服务器端、云端推理 |
| 飞桨服务化推理框架 | Paddle Serving | 自动服务、模型管理等高阶功能 |
| 飞桨轻量化推理引擎 | Paddle Lite | 移动端、物联网等 |
| 飞桨前端推理引擎 | Paddle.js | 浏览器中推理、小程序等 |
其在推理生态中各自的关系如下

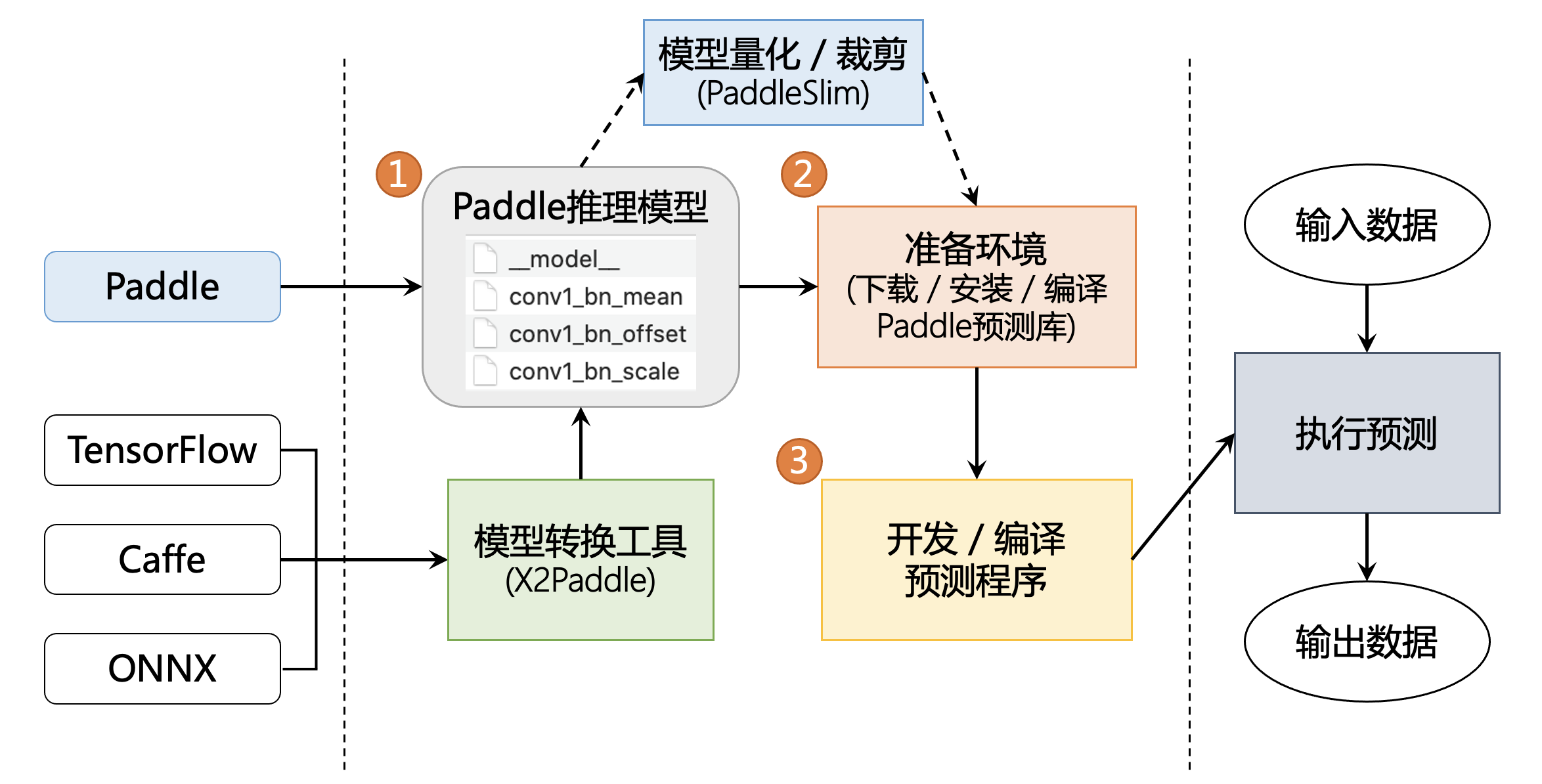
用户使用飞桨推理产品的工作流 如下
获取一个飞桨的推理模型,其中有两种方法
利用飞桨训练得到一个推理模型
用 X2Paddle 工具从第三方框架(比如 TensorFlow 或者 Caffe 等)产出的模型转化
(可选)对模型进行进一步优化, PaddleSlim 工具可以对模型进行压缩,量化,裁剪等工作,显著提升模型执行的速度性能,降低资源消耗
将模型部署到具体的推理产品上
Paddle Inference 简介¶
Paddle Inference 是飞桨的原生推理库, 作用于服务器端和云端,提供高性能的推理能力。
由于能力直接基于飞桨的训练算子,因此Paddle Inference 可以通用支持飞桨训练出的所有模型。
Paddle Inference 功能特性丰富,性能优异,针对不同平台不同的应用场景进行了深度的适配优化,做到高吞吐、低时延,保证了飞桨模型在服务器端即训即用,快速部署。
Paddle Inference的高性能实现¶
内存/显存复用提升服务吞吐量¶
在推理初始化阶段,对模型中的OP输出Tensor 进行依赖分析,将两两互不依赖的Tensor在内存/显存空间上进行复用,进而增大计算并行量,提升服务吞吐量。
细粒度OP横向纵向融合减少计算量¶
在推理初始化阶段,按照已有的融合模式将模型中的多个OP融合成一个OP,减少了模型的计算量的同时,也减少了 Kernel Launch的次数,从而能提升推理性能。目前Paddle Inference支持的融合模式多达几十个。
内置高性能的CPU/GPU Kernel¶
内置同Intel、Nvidia共同打造的高性能kernel,保证了模型推理高性能的执行。
子图集成TensorRT加快GPU推理速度¶
Paddle Inference采用子图的形式集成TensorRT,针对GPU推理场景,TensorRT可对一些子图进行优化,包括OP的横向和纵向融合,过滤冗余的OP,并为OP自动选择最优的kernel,加快推理速度。
子图集成Paddle Lite轻量化推理引擎¶
Paddle Lite 是飞桨深度学习框架的一款轻量级、低框架开销的推理引擎,除了在移动端应用外,还可以使用服务器进行 Paddle Lite 推理。Paddle Inference采用子图的形式集成 Paddle Lite,以方便用户在服务器推理原有方式上稍加改动,即可开启 Paddle Lite 的推理能力,得到更快的推理速度。并且,使用 Paddle Lite 可支持在百度昆仑等高性能AI芯片上执行推理计算。
支持加载PaddleSlim量化压缩后的模型¶
PaddleSlim是飞桨深度学习模型压缩工具,Paddle Inference可联动PaddleSlim,支持加载量化、裁剪和蒸馏后的模型并部署,由此减小模型存储空间、减少计算占用内存、加快模型推理速度。其中在模型量化方面,Paddle Inference在X86 CPU上做了深度优化,常见分类模型的单线程性能可提升近3倍,ERNIE模型的单线程性能可提升2.68倍。
概述¶
Paddle Inference为飞桨核心框架推理引擎。Paddle Inference功能特性丰富,性能优异,针对不同平台不同的应用场景进行了深度的适配优化,做到高吞吐、低时延,保证了飞桨模型在服务器端即训即用,快速部署。
特性¶
通用性。支持对Paddle训练出的所有模型进行预测。
内存/显存复用。在推理初始化阶段,对模型中的OP输出Tensor 进行依赖分析,将两两互不依赖的Tensor在内存/显存空间上进行复用,进而增大计算并行量,提升服务吞吐量。
细粒度OP融合。在推理初始化阶段,按照已有的融合模式将模型中的多个OP融合成一个OP,减少了模型的计算量的同时,也减少了 Kernel Launch的次数,从而能提升推理性能。目前Paddle Inference支持的融合模式多达几十个。
高性能CPU/GPU Kernel。内置同Intel、Nvidia共同打造的高性能kernel,保证了模型推理高性能的执行。
子图集成 TensorRT。Paddle Inference采用子图的形式集成TensorRT,针对GPU推理场景,TensorRT可对一些子图进行优化,包括OP的横向和纵向融合,过滤冗余的OP,并为OP自动选择最优的kernel,加快推理速度。
集成MKLDNN
支持加载PaddleSlim量化压缩后的模型。 PaddleSlim 是飞桨深度学习模型压缩工具,Paddle Inference可联动PaddleSlim,支持加载量化、裁剪和蒸馏后的模型并部署,由此减小模型存储空间、减少计算占用内存、加快模型推理速度。其中在模型量化方面,Paddle Inference在X86 CPU上做了深度优化 ,常见分类模型的单线程性能可提升近3倍,ERNIE模型的单线程性能可提升2.68倍。
预测流程¶
一. 准备模型¶
Paddle Inference 原生支持由 PaddlePaddle 深度学习框架训练产出的推理模型。目前 PaddlePaddle 用于推理的模型是通过 save_inference_model 这个API保存下来的。
如果您手中的模型是由诸如 Caffe、Tensorflow、PyTorch 等框架产出的,那么您可以使用 X2Paddle 工具将模型转换为 PadddlePaddle 格式。
二. 准备环境¶
1) Python 环境¶
请参照 官方主页-快速安装 页面进行自行安装或编译,当前支持 pip/conda 安装,docker镜像 以及源码编译等多种方式来准备 Paddle Inference 开发环境。
2) C++ 环境¶
Paddle Inference 提供了 Ubuntu/Windows/MacOS 平台的官方Release预测库下载,如果您使用的是以上平台,我们优先推荐您通过以下链接直接下载,或者您也可以参照文档进行源码编译。
三. 开发预测程序¶
Paddle Inference采用 Predictor 进行预测。Predictor 是一个高性能预测引擎,该引擎通过对计算图的分析,完成对计算图的一系列的优化(如OP的融合、内存/显存的优化、 MKLDNN,TensorRT 等底层加速库的支持等),能够大大提升预测性能。
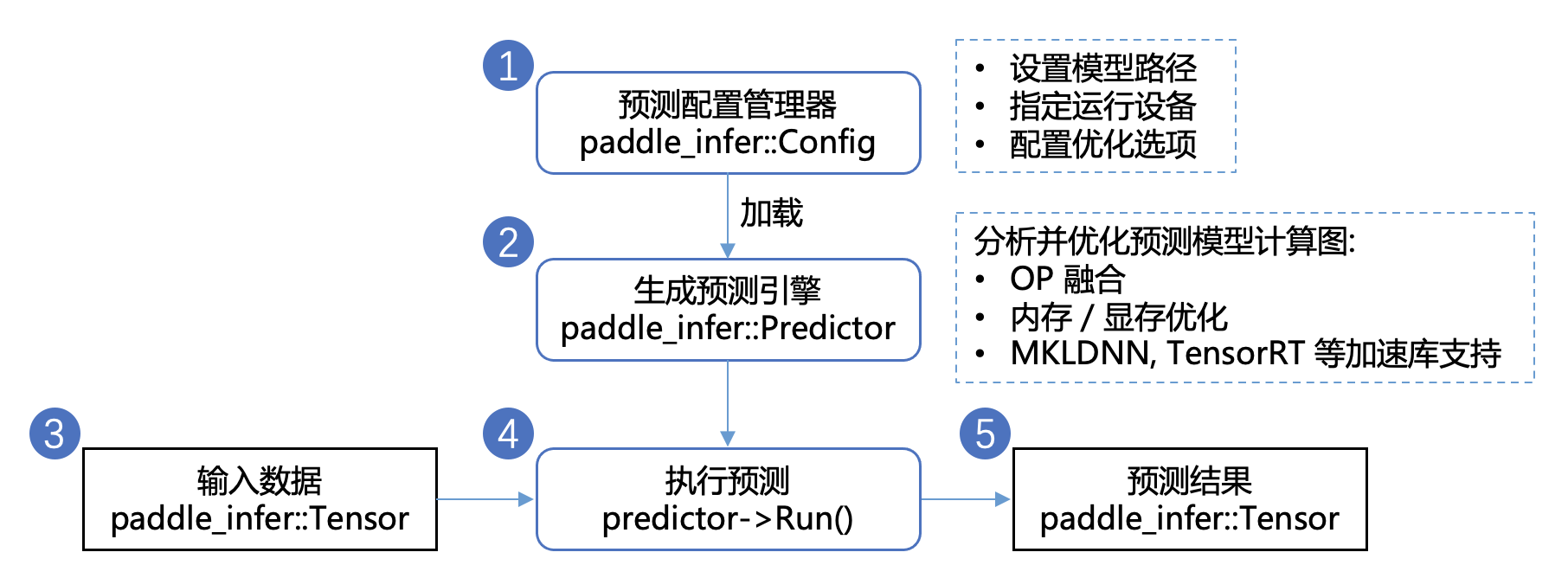
开发预测程序只需要简单的5个步骤 (这里以C++ API为例):
配置推理选项
paddle_infer::Config,包括设置模型路径、运行设备、开启/关闭计算图优化、使用MKLDNN/TensorRT进行部署的加速等。创建推理引擎
paddle_infer::Predictor,通过调用CreatePaddlePredictor(Config)接口,一行代码即可完成引擎初始化,其中Config为第1步中生成的配置推理选项。准备输入数据,需要以下几个步骤
先通过
auto input_names = predictor->GetInputNames()获取模型所有输入 Tensor 的名称再通过
auto tensor = predictor->GetInputTensor(input_names[i])获取输入 Tensor 的指针最后通过
tensor->copy_from_cpu(data),将 data 中的数据拷贝到 tensor 中
执行预测,只需要运行
predictor->Run()一行代码,即可完成预测执行获得预测结果,需要以下几个步骤
先通过
auto out_names = predictor->GetOutputNames()获取模型所有输出 Tensor 的名称再通过
auto tensor = predictor->GetOutputTensor(out_names[i])获取输出 Tensor的 指针最后通过
tensor->copy_to_cpu(data),将 tensor 中的数据 copy 到 data 指针上
Paddle Inference 提供了C, C++, Python, Golang 和 Java 五种API的使用示例和开发说明文档,您可以参考示例中的说明快速了解使用方法,并集成到您自己的项目中去。
预测示例 (C++)¶
本章节包含2部分内容:(1) 运行 C++ 示例程序;(2) C++ 预测程序开发说明。
运行 C++ 示例程序¶
1. 下载预编译 C++ 预测库¶
Paddle Inference 提供了 Ubuntu/Windows/MacOS 平台的官方Release预测库下载,如果您使用的是以上平台,我们优先推荐您通过以下链接直接下载,或者您也可以参照文档进行源码编译。
下载完成并解压之后,目录下的 paddle_inference_install_dir 即为 C++ 预测库,目录结构如下:
paddle_inference/paddle_inference_install_dir/
├── CMakeCache.txt
├── paddle
│ ├── include C++ 预测库头文件目录
│ │ ├── crypto
│ │ ├── internal
│ │ ├── paddle_analysis_config.h
│ │ ├── paddle_api.h
│ │ ├── paddle_infer_declare.h
│ │ ├── paddle_inference_api.h C++ 预测库头文件
│ │ ├── paddle_mkldnn_quantizer_config.h
│ │ └── paddle_pass_builder.h
│ └── lib
│ ├── libpaddle_fluid.a C++ 静态预测库文件
│ └── libpaddle_fluid.so C++ 动态态预测库文件
├── third_party
│ ├── install 第三方链接库和头文件
│ │ ├── cryptopp
│ │ ├── gflags
│ │ ├── glog
│ │ ├── mkldnn
│ │ ├── mklml
│ │ ├── protobuf
│ │ └── xxhash
│ └── threadpool
│ └── ThreadPool.h
└── version.txt
其中 version.txt 文件中记录了该预测库的版本信息,包括Git Commit ID、使用OpenBlas或MKL数学库、CUDA/CUDNN版本号,如:
GIT COMMIT ID: 1bf4836580951b6fd50495339a7a75b77bf539f6
WITH_MKL: ON
WITH_MKLDNN: ON
WITH_GPU: ON
CUDA version: 9.0
CUDNN version: v7.6
CXX compiler version: 4.8.5
WITH_TENSORRT: ON
TensorRT version: v6
2. 准备预测部署模型¶
下载 ResNet50 模型后解压,得到 Paddle Combined 形式的模型,位于文件夹 ResNet50 下。如需查看模型结构,可将 model 文件重命名为 __model__,然后通过模型可视化工具 Netron 打开。
wget https://paddle-inference-dist.bj.bcebos.com/inference_demo/python/resnet50/ResNet50.tar.gz
tar zxf ResNet50.tar.gz
# 获得模型目录即文件如下
ResNet50/
├── model
└── params
3. 获取预测示例代码并编译¶
本章节 C++ 预测示例代码位于 Paddle-Inference-Demo/c++/resnet50。目录包含以下文件:
-rw-r--r-- 1 root root 2.6K Dec 11 07:26 resnet50_test.cc 预测 C++ 源码程序
-rw-r--r-- 1 root root 7.4K Dec 11 07:26 CMakeLists.txt CMAKE 文件
-rwxr-xr-x 1 root root 650 Dec 11 07:26 run_impl.sh 编译脚本
-rw-r--r-- 1 root root 2.2K Dec 11 07:26 README.md README 说明
编译运行预测样例之前,需要根据运行环境配置编译脚本 run_impl.sh。
# 根据预编译库中的version.txt信息判断是否将以下三个标记打开
WITH_MKL=ON
WITH_GPU=ON
USE_TENSORRT=OFF
# 配置预测库的根目录,即为本章节第1步中下载/编译的 C++ 预测库
LIB_DIR=${YOUR_LIB_DIR}/paddle_inference_install_dir
# 如果上述的 WITH_GPU 或 USE_TENSORRT 设为ON,请设置对应的 CUDA, CUDNN, TENSORRT的路径,例如
CUDNN_LIB=/usr/lib/x86_64-linux-gnu
CUDA_LIB=/usr/local/cuda-10.2/lib64
# 编译,会在目录下产生build目录,并生成 build/resnet50_test 可执行文件
bash run_impl.sh
4. 执行预测程序¶
注意:执行预测之前,需要现将动态库文件 libpaddle_fluid_c.so 所在路径加入 LD_LIBRARY_PATH,否则会出现无法找到库文件的错误。
# 设置 LD_LIBRARY_PATH
LIB_DIR=${YOUR_LIB_DIR}/paddle_inference_install_dir
export LD_LIBRARY_PATH=${LIB_DIR}/paddle/lib:$LD_LIBRARY_PATH
# 参数输入为本章节第2步中下载的 ResNet50 模型
./build/resnet50_test --model_file=./ResNet50/model --params_file=./ResNet50/params
成功执行之后,得到的预测输出结果如下:
# 程序输出结果如下
WARNING: Logging before InitGoogleLogging() is written to STDERR
E1211 08:29:39.840502 18792 paddle_pass_builder.cc:139] GPU not support MKLDNN yet
E1211 08:29:39.840647 18792 paddle_pass_builder.cc:139] GPU not support MKLDNN yet
E1211 08:29:40.997318 18792 paddle_pass_builder.cc:139] GPU not support MKLDNN yet
I1211 08:29:40.997367 18792 analysis_predictor.cc:139] Profiler is deactivated, and no profiling report will be generated.
I1211 08:29:41.016829 18792 analysis_predictor.cc:496] MKLDNN is enabled
--- Running analysis [ir_graph_build_pass]
--- Running analysis [ir_graph_clean_pass]
--- Running analysis [ir_analysis_pass]
--- Running IR pass [is_test_pass]
--- Running IR pass [simplify_with_basic_ops_pass]
--- Running IR pass [conv_affine_channel_fuse_pass]
--- Running IR pass [conv_eltwiseadd_affine_channel_fuse_pass]
--- Running IR pass [conv_bn_fuse_pass]
I1211 08:29:41.536377 18792 graph_pattern_detector.cc:101] --- detected 53 subgraphs
--- Running IR pass [conv_eltwiseadd_bn_fuse_pass]
--- Running IR pass [embedding_eltwise_layernorm_fuse_pass]
--- Running IR pass [multihead_matmul_fuse_pass_v2]
--- Running IR pass [fc_fuse_pass]
I1211 08:29:41.577596 18792 graph_pattern_detector.cc:101] --- detected 1 subgraphs
--- Running IR pass [fc_elementwise_layernorm_fuse_pass]
--- Running IR pass [conv_elementwise_add_act_fuse_pass]
I1211 08:29:41.599529 18792 graph_pattern_detector.cc:101] --- detected 33 subgraphs
--- Running IR pass [conv_elementwise_add2_act_fuse_pass]
I1211 08:29:41.610285 18792 graph_pattern_detector.cc:101] --- detected 16 subgraphs
--- Running IR pass [conv_elementwise_add_fuse_pass]
I1211 08:29:41.613446 18792 graph_pattern_detector.cc:101] --- detected 4 subgraphs
--- Running IR pass [transpose_flatten_concat_fuse_pass]
--- Running IR pass [runtime_context_cache_pass]
--- Running analysis [ir_params_sync_among_devices_pass]
I1211 08:29:41.620128 18792 ir_params_sync_among_devices_pass.cc:45] Sync params from CPU to GPU
--- Running analysis [adjust_cudnn_workspace_size_pass]
--- Running analysis [inference_op_replace_pass]
--- Running analysis [ir_graph_to_program_pass]
I1211 08:29:41.688971 18792 analysis_predictor.cc:541] ======= optimize end =======
I1211 08:29:41.689072 18792 naive_executor.cc:102] --- skip [feed], feed -> image
I1211 08:29:41.689968 18792 naive_executor.cc:102] --- skip [save_infer_model/scale_0.tmp_0], fetch -> fetch
W1211 08:29:41.690475 18792 device_context.cc:338] Please NOTE: device: 0, CUDA Capability: 70, Driver API Version: 11.0, Runtime API Version: 9.0
W1211 08:29:41.690726 18792 device_context.cc:346] device: 0, cuDNN Version: 7.6.
WARNING: Logging before InitGoogleLogging() is written to STDERR
I1211 08:29:43.666896 18792 resnet50_test.cc:76] 0.000293902
I1211 08:29:43.667001 18792 resnet50_test.cc:76] 0.000453056
I1211 08:29:43.667009 18792 resnet50_test.cc:76] 0.000202802
I1211 08:29:43.667017 18792 resnet50_test.cc:76] 0.000109128
I1211 08:29:43.667255 18792 resnet50_test.cc:76] 0.000138924
...
C++ 预测程序开发说明¶
使用 Paddle Inference 开发 C++ 预测程序仅需以下五个步骤:
(1) 引用头文件
#include "paddle/include/paddle_inference_api.h"
(2) 创建配置对象,并根据需求配置,详细可参考 C++ API 文档 - Config
// 创建默认配置对象
paddle_infer::Config config;
// 设置预测模型路径,即为本小节第2步中下载的模型
config.SetModel(FLAGS_model_file, FLAGS_params_file);
// 启用 GPU 和 MKLDNN 预测
config.EnableUseGpu(100, 0);
config.EnableMKLDNN();
// 开启 内存/显存 复用
config.EnableMemoryOptim();
(3) 根据Config创建预测对象,详细可参考 C++ API 文档 - Predictor
auto predictor = paddle_infer::CreatePredictor(config);
(4) 设置模型输入 Tensor,详细可参考 C++ API 文档 - Tensor
// 获取输入 Tensor
auto input_names = predictor->GetInputNames();
auto input_tensor = predictor->GetInputHandle(input_names[0]);
// 设置输入 Tensor 的维度信息
std::vector<int> INPUT_SHAPE = {1, 3, 224, 224};
input_tensor->Reshape(INPUT_SHAPE);
// 准备输入数据
int input_size = 1 * 3 * 224 * 224;
std::vector<float> input_data(input_size, 1);
// 设置输入 Tensor 数据
input_tensor->CopyFromCpu(input_data.data());
(5) 执行预测,详细可参考 C++ API 文档 - Predictor
// 执行预测
predictor->Run();
(5) 获得预测结果,详细可参考 C++ API 文档 - Tensor
// 获取 Output Tensor
auto output_names = predictor->GetOutputNames();
auto output_tensor = predictor->GetInputHandle(output_names[0]);
// 获取 Output Tensor 的维度信息
std::vector<int> output_shape = output_tensor->shape();
int output_size = std::accumulate(output_shape.begin(), output_shape.end(), 1,
std::multiplies<int>());
// 获取 Output Tensor 的数据
std::vector<float> output_data;
output_data.resize(output_size);
output_tensor->CopyToCpu(output_data.data());
预测示例 (Python)¶
本章节包含2部分内容:(1) 运行 Python 示例程序;(2) Python 预测程序开发说明。
运行 Python 示例程序¶
1. 安装 Python 预测库¶
请参照 官方主页-快速安装 页面进行自行安装或编译,当前支持 pip/conda 安装,docker镜像 以及源码编译等多种方式来准备 Paddle Inference 开发环境。
2. 准备预测部署模型¶
下载 resnet50 模型后解压,得到 Paddle Combined 形式的模型,位于文件夹 model 下。如需查看模型结构,可将 model 文件重命名为 __model__,然后通过模型可视化工具 Netron 打开。
wget http://paddle-inference-dist.bj.bcebos.com/resnet50_model.tar.gz
tar zxf resnet50_model.tar.gz
# 获得模型目录即文件如下
model/
├── model
└── params
3. 准备预测部署程序¶
将以下代码保存为 python_demo.py 文件:
import argparse
import numpy as np
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
def main():
args = parse_args()
# 创建 config
config = paddle_infer.Config(args.model_file, args.params_file)
# 根据 config 创建 predictor
predictor = paddle_infer.create_predictor(config)
# 获取输入的名称
input_names = predictor.get_input_names()
input_handle = predictor.get_input_handle(input_names[0])
# 设置输入
fake_input = np.random.randn(args.batch_size, 3, 318, 318).astype("float32")
input_handle.reshape([args.batch_size, 3, 318, 318])
input_handle.copy_from_cpu(fake_input)
# 运行predictor
predictor.run()
# 获取输出
output_names = predictor.get_output_names()
output_handle = predictor.get_output_handle(output_names[0])
output_data = output_handle.copy_to_cpu() # numpy.ndarray类型
print("Output data size is {}".format(output_data.size))
print("Output data shape is {}".format(output_data.shape))
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument("--model_file", type=str, help="model filename")
parser.add_argument("--params_file", type=str, help="parameter filename")
parser.add_argument("--batch_size", type=int, default=1, help="batch size")
return parser.parse_args()
if __name__ == "__main__":
main()
4. 执行预测程序¶
# 参数输入为本章节第2步中下载的 ResNet50 模型
python python_demo.py --model_file ./model/model --params_file ./model/params --batch_size 2
成功执行之后,得到的预测输出结果如下:
# 程序输出结果如下
grep: warning: GREP_OPTIONS is deprecated; please use an alias or script
I1211 11:12:40.869632 20942 analysis_predictor.cc:139] Profiler is deactivated, and no profiling report will be generated.
--- Running analysis [ir_graph_build_pass]
--- Running analysis [ir_graph_clean_pass]
--- Running analysis [ir_analysis_pass]
--- Running IR pass [simplify_with_basic_ops_pass]
--- Running IR pass [attention_lstm_fuse_pass]
--- Running IR pass [seqconv_eltadd_relu_fuse_pass]
--- Running IR pass [seqpool_cvm_concat_fuse_pass]
--- Running IR pass [mul_lstm_fuse_pass]
--- Running IR pass [fc_gru_fuse_pass]
--- Running IR pass [mul_gru_fuse_pass]
--- Running IR pass [seq_concat_fc_fuse_pass]
--- Running IR pass [fc_fuse_pass]
I1211 11:12:41.327713 20942 graph_pattern_detector.cc:100] --- detected 1 subgraphs
--- Running IR pass [repeated_fc_relu_fuse_pass]
--- Running IR pass [squared_mat_sub_fuse_pass]
--- Running IR pass [conv_bn_fuse_pass]
--- Running IR pass [conv_eltwiseadd_bn_fuse_pass]
I1211 11:12:41.550542 20942 graph_pattern_detector.cc:100] --- detected 53 subgraphs
--- Running IR pass [conv_transpose_bn_fuse_pass]
--- Running IR pass [conv_transpose_eltwiseadd_bn_fuse_pass]
--- Running IR pass [is_test_pass]
--- Running IR pass [runtime_context_cache_pass]
--- Running analysis [ir_params_sync_among_devices_pass]
--- Running analysis [adjust_cudnn_workspace_size_pass]
--- Running analysis [inference_op_replace_pass]
--- Running analysis [ir_graph_to_program_pass]
I1211 11:12:41.594254 20942 analysis_predictor.cc:537] ======= optimize end =======
I1211 11:12:41.594414 20942 naive_executor.cc:102] --- skip [feed], feed -> data
I1211 11:12:41.595824 20942 naive_executor.cc:102] --- skip [AddmmBackward190.fc.output.1.tmp_1], fetch -> fetch
Output data size is 1024
Output data shape is (2, 512)
Python 预测程序开发说明¶
使用 Paddle Inference 开发 Python 预测程序仅需以下五个步骤:
(1) 引用 paddle inference 预测库
import paddle.inference as paddle_infer
(2) 创建配置对象,并根据需求配置,详细可参考 Python API 文档 - Config
# 创建 config,并设置预测模型路径
config = paddle_infer.Config(args.model_file, args.params_file)
(3) 根据Config创建预测对象,详细可参考 Python API 文档 - Predictor
predictor = paddle_infer.create_predictor(config)
(4) 设置模型输入 Tensor,详细可参考 Python API 文档 - Tensor
# 获取输入的名称
input_names = predictor.get_input_names()
input_handle = predictor.get_input_handle(input_names[0])
# 设置输入
fake_input = np.random.randn(args.batch_size, 3, 318, 318).astype("float32")
input_handle.reshape([args.batch_size, 3, 318, 318])
input_handle.copy_from_cpu(fake_input)
(5) 执行预测,详细可参考 Python API 文档 - Predictor
predictor.run()
(5) 获得预测结果,详细可参考 Python API 文档 - Tensor
output_names = predictor.get_output_names()
output_handle = predictor.get_output_handle(output_names[0])
output_data = output_handle.copy_to_cpu() # numpy.ndarray类型
预测示例 (C)¶
本章节包含2部分内容:(1) 运行 C 示例程序;(2) C 预测程序开发说明。
运行 C 示例程序¶
1. 源码编译 C 预测库¶
Paddle Inference 的 C 预测库需要以源码编译的方式进行获取,请参照以下两个文档进行源码编译
编译完成后,在编译目录下的 paddle_inference_c_install_dir 即为 C 预测库,目录结构如下:
paddle_inference_c_install_dir
├── paddle
│ ├── include
│ │ └── paddle_c_api.h C 预测库头文件
│ └── lib
│ ├── libpaddle_fluid_c.a C 静态预测库文件
│ └── libpaddle_fluid_c.so C 动态预测库文件
├── third_party
│ └── install 第三方链接库和头文件
│ ├── cryptopp
│ ├── gflags
│ ├── glog
│ ├── mkldnn
│ ├── mklml
│ ├── protobuf
│ └── xxhash
└── version.txt 版本信息与编译选项信息
其中 version.txt 文件中记录了该预测库的版本信息,包括Git Commit ID、使用OpenBlas或MKL数学库、CUDA/CUDNN版本号,如:
GIT COMMIT ID: 1bf4836580951b6fd50495339a7a75b77bf539f6
WITH_MKL: ON
WITH_MKLDNN: ON
WITH_GPU: ON
CUDA version: 9.0
CUDNN version: v7.6
CXX compiler version: 4.8.5
WITH_TENSORRT: ON
TensorRT version: v6
2. 准备预测部署模型¶
下载 resnet50 模型后解压,得到 Paddle Combined 形式的模型,位于文件夹 model 下。如需查看模型结构,可将 model 文件重命名为 __model__,然后通过模型可视化工具 Netron 打开。
wget http://paddle-inference-dist.bj.bcebos.com/resnet50_model.tar.gz
tar zxf resnet50_model.tar.gz
# 获得模型目录即文件如下
model/
├── model
└── params
3. 准备预测部署程序¶
将以下代码保存为 c_demo.c 文件:
#include <stdbool.h>
#include "paddle_c_api.h"
#include <memory.h>
#include <malloc.h>
int main() {
// 配置 PD_AnalysisConfig
PD_AnalysisConfig* config = PD_NewAnalysisConfig();
// 设置预测模型路径,即为本小节第2步中下载的模型
const char* model_path = "./model/model";
const char* params_path = "./model/params";
PD_SetModel(config, model_path, params_path);
// 创建输入 Tensor
PD_Tensor* input_tensor = PD_NewPaddleTensor();
// 创建输入 Buffer
PD_PaddleBuf* input_buffer = PD_NewPaddleBuf();
printf("PaddleBuf empty: %s\n", PD_PaddleBufEmpty(input_buffer) ? "true" : "false");
int batch = 1;
int channel = 3;
int height = 318;
int width = 318;
int input_shape[4] = {batch, channel, height, width};
int input_size = batch * channel * height * width;
float* input_data = malloc(sizeof(float) * input_size);
int i = 0;
for (i = 0; i < input_size ; i++){
input_data[i] = 1.0f;
}
PD_PaddleBufReset(input_buffer, (void*)(input_data), sizeof(float) * input_size);
// 设置输入 Tensor 信息
char* input_name = "data"; // 可通过 Netron 工具查看输入 Tensor 名字、形状、数据等
PD_SetPaddleTensorName(input_tensor, input_name);
PD_SetPaddleTensorDType(input_tensor, PD_FLOAT32);
PD_SetPaddleTensorShape(input_tensor, input_shape, 4);
PD_SetPaddleTensorData(input_tensor, input_buffer);
// 设置输出 Tensor 和 数量
PD_Tensor* output_tensor = PD_NewPaddleTensor();
int output_size;
// 执行预测
PD_PredictorRun(config, input_tensor, 1, &output_tensor, &output_size, 1);
// 获取预测输出 Tensor 信息
printf("Output Tensor Size: %d\n", output_size);
printf("Output Tensor Name: %s\n", PD_GetPaddleTensorName(output_tensor));
printf("Output Tensor Dtype: %d\n", PD_GetPaddleTensorDType(output_tensor));
// 获取预测输出 Tensor 数据
PD_PaddleBuf* output_buffer = PD_GetPaddleTensorData(output_tensor);
float* result = (float*)(PD_PaddleBufData(output_buffer));
int result_length = PD_PaddleBufLength(output_buffer) / sizeof(float);
printf("Output Data Length: %d\n", result_length);
// 删除输入 Tensor 和 Buffer
PD_DeletePaddleTensor(input_tensor);
PD_DeletePaddleBuf(input_buffer);
return 0;
}
4. 编译预测部署程序¶
将 paddle_inference_c_install_dir/paddle 目录下的头文件 paddle_c_api.h 和动态库文件 libpaddle_fluid_c.so 拷贝到与预测源码同一目录,然后使用 GCC 进行编译:
# GCC 编译命令
gcc c_demo.c libpaddle_fluid_c.so -o c_demo_prog
# 编译完成之后生成 c_demo_prog 可执行文件,编译目录内容如下
c_demo_dir/
│
├── c_demo.c 预测 C 源码程序,内容如本小节第3步所示
├── c_demo_prog 编译后的预测可执行程序
│
├── paddle_c_api.h C 预测库头文件
├── libpaddle_fluid_c.so C 动态预测库文件
│
├── resnet50_model.tar.gz 本小节第2步中下载的预测模型
└── model 本小节第2步中下载的预测模型解压后的模型文件
├── model
└── params
5. 执行预测程序¶
注意:需要现将动态库文件 libpaddle_fluid_c.so 所在路径加入 LD_LIBRARY_PATH,否则会出现无法找到库文件的错误。
# 执行预测程序
export LD_LIBRARY_PATH=`pwd`:$LD_LIBRARY_PATH
./c_demo_prog
成功执行之后,得到的预测输出结果如下:
# 程序输出结果如下
WARNING: Logging before InitGoogleLogging() is written to STDERR
I1211 05:57:48.939208 16443 pd_config.cc:43] ./model/model
I1211 05:57:48.939507 16443 pd_config.cc:48] ./model/model
PaddleBuf empty: true
W1211 05:57:48.941076 16443 analysis_predictor.cc:1052] Deprecated. Please use CreatePredictor instead.
I1211 05:57:48.941124 16443 analysis_predictor.cc:139] Profiler is deactivated, and no profiling report will be generated.
--- Running analysis [ir_graph_build_pass]
--- Running analysis [ir_graph_clean_pass]
--- Running analysis [ir_analysis_pass]
--- Running IR pass [simplify_with_basic_ops_pass]
--- Running IR pass [attention_lstm_fuse_pass]
--- Running IR pass [seqconv_eltadd_relu_fuse_pass]
--- Running IR pass [seqpool_cvm_concat_fuse_pass]
--- Running IR pass [mul_lstm_fuse_pass]
--- Running IR pass [fc_gru_fuse_pass]
--- Running IR pass [mul_gru_fuse_pass]
--- Running IR pass [seq_concat_fc_fuse_pass]
--- Running IR pass [fc_fuse_pass]
I1211 05:57:49.481595 16443 graph_pattern_detector.cc:101] --- detected 1 subgraphs
--- Running IR pass [repeated_fc_relu_fuse_pass]
--- Running IR pass [squared_mat_sub_fuse_pass]
--- Running IR pass [conv_bn_fuse_pass]
--- Running IR pass [conv_eltwiseadd_bn_fuse_pass]
I1211 05:57:49.698067 16443 graph_pattern_detector.cc:101] --- detected 53 subgraphs
--- Running IR pass [conv_transpose_bn_fuse_pass]
--- Running IR pass [conv_transpose_eltwiseadd_bn_fuse_pass]
--- Running IR pass [is_test_pass]
--- Running IR pass [runtime_context_cache_pass]
--- Running analysis [ir_params_sync_among_devices_pass]
--- Running analysis [adjust_cudnn_workspace_size_pass]
--- Running analysis [inference_op_replace_pass]
--- Running analysis [ir_graph_to_program_pass]
I1211 05:57:49.741832 16443 analysis_predictor.cc:541] ======= optimize end =======
Output Tensor Size: 1
Output Tensor Name: AddmmBackward190.fc.output.1.tmp_1
Output Tensor Dtype: 0
Output Data Length: 512
C 预测程序开发说明¶
使用 Paddle Inference 开发 C 预测程序仅需以下六个步骤:
(1) 引用头文件
#include "paddle_c_api.h"
(2) 创建配置对象,并指定预测模型路径,详细可参考 C API 文档 - AnalysisConfig
// 配置 PD_AnalysisConfig
PD_AnalysisConfig* config = PD_NewAnalysisConfig();
// 设置预测模型路径,即为本小节第2步中下载的模型
const char* model_path = "./model/model";
const char* params_path = "./model/params";
PD_SetModel(config, model_path, params_path);
(3) 设置模型输入和输出 Tensor,详细可参考 C API 文档 - PaddleTensor
// 创建输入 Tensor
PD_Tensor* input_tensor = PD_NewPaddleTensor();
// 创建输入 Buffer
PD_PaddleBuf* input_buffer = PD_NewPaddleBuf();
printf("PaddleBuf empty: %s\n", PD_PaddleBufEmpty(input_buffer) ? "true" : "false");
int batch = 1;
int channel = 3;
int height = 318;
int width = 318;
int input_shape[4] = {batch, channel, height, width};
int input_size = batch * channel * height * width;
float* data = malloc(sizeof(float) * input_size);
int i = 0;
for (i = 0; i < input_size ; i++){
data[i] = 1.0f;
}
PD_PaddleBufReset(input_buffer, (void*)(data), sizeof(float) * input_size);
// 设置输入 Tensor 信息
char* input_name = "data"; // 可通过 Netron 工具查看输入 Tensor 名字、形状、数据等
PD_SetPaddleTensorName(input_tensor, input_name);
PD_SetPaddleTensorDType(input_tensor, PD_FLOAT32);
PD_SetPaddleTensorShape(input_tensor, input_shape, 4);
PD_SetPaddleTensorData(input_tensor, input_buffer);
// 设置输出 Tensor 和 数量
PD_Tensor* output_tensor = PD_NewPaddleTensor();
int output_size;
(4) 执行预测引擎,,详细可参考 C API 文档 - Predictor
// 执行预测
PD_PredictorRun(config, input_tensor, 1, &output_tensor, &output_size, 1);
(5) 获得预测结果,详细可参考 C API 文档 - PaddleTensor
// 获取预测输出 Tensor 信息
printf("Output Tensor Size: %d\n", output_size);
printf("Output Tensor Name: %s\n", PD_GetPaddleTensorName(output_tensor));
printf("Output Tensor Dtype: %d\n", PD_GetPaddleTensorDType(output_tensor));
// 获取预测输出 Tensor 数据
PD_PaddleBuf* output_buffer = PD_GetPaddleTensorData(output_tensor);
float* result = (float*)(PD_PaddleBufData(output_buffer));
int result_length = PD_PaddleBufLength(output_buffer) / sizeof(float);
printf("Output Data Length: %d\n", result_length);
(6) 删除输入 Tensor,Buffer 和 Config
PD_DeletePaddleTensor(input_tensor);
PD_DeletePaddleBuf(input_buffer);
PD_DeleteAnalysisConfig(config);
预测示例 (GO)¶
本章节包含2部分内容:(1) 运行 GO 示例程序;(2) GO 预测程序开发说明。
运行 GO 示例程序¶
1. 源码编译 GO 预测库¶
Paddle Inference 的 GO 预测库即为 C 预测库,需要以源码编译的方式进行获取,请参照以下两个文档进行源码编译
编译完成后,在编译目录下的 paddle_inference_c_install_dir 即为 GO 预测库,目录结构为:
paddle_inference_c_install_dir
├── paddle
│ ├── include
│ │ └── paddle_c_api.h C/GO 预测库头文件
│ └── lib
│ ├── libpaddle_fluid_c.a C/GO 静态预测库文件
│ └── libpaddle_fluid_c.so C/GO 动态预测库文件
├── third_party
│ └── install 第三方链接库和头文件
│ ├── cryptopp
│ ├── gflags
│ ├── glog
│ ├── mkldnn
│ ├── mklml
│ ├── protobuf
│ └── xxhash
└── version.txt 版本信息与编译选项信息
其中 version.txt 文件中记录了该预测库的版本信息,包括Git Commit ID、使用OpenBlas或MKL数学库、CUDA/CUDNN版本号,如:
GIT COMMIT ID: 1bf4836580951b6fd50495339a7a75b77bf539f6
WITH_MKL: ON
WITH_MKLDNN: ON
WITH_GPU: ON
CUDA version: 9.0
CUDNN version: v7.6
CXX compiler version: 4.8.5
WITH_TENSORRT: ON
TensorRT version: v6
2. 准备预测部署模型¶
下载 mobilenetv1 模型后解压,得到 Paddle Combined 形式的模型和数据,位于文件夹 data 下。可将 __model__ 文件通过模型可视化工具 Netron 打开来查看模型结构。
wget https://paddle-inference-dist.cdn.bcebos.com/mobilenet-test-model-data.tar.gz
tar zxf mobilenet-test-model-data.tar.gz
# 获得 data 目录结构如下
data/
├── model
│ ├── __model__
│ └── __params__
├── data.txt
└── result.txt
3. 获取预测示例代码¶
本章节 GO 预测示例代码位于 Paddle/go,目录包含以下文件:
Paddle/go/
├── demo
│ ├── mobilenet_c.cc
│ ├── mobilenet_cxx.cc
│ └── mobilenet.go GO 的预测示例程序源码
├── paddle
│ ├── common.go
│ ├── config.go Config 的 GO references to C
│ ├── predictor.go Predictor 的 GO references to C
│ ├── tensor.go Tensor 的 GO references to C
└── README_cn.md GO Demo README 说明
4. 准备预测执行目录¶
执行预测程序之前需要完成以下几个步骤
将本章节 第1步 中的
paddle_inference_c_install_dir移到到Paddle/go目录下,并将paddle_inference_c_install_dir重命名为paddle_c本章节 第2步 中下载的模型和数据文件夹
data移动到Paddle/go目录下
执行完之后的目录结构如下:
Paddle/go/
├── demo
│ ├── mobilenet_c.cc
│ ├── mobilenet_cxx.cc
│ └── mobilenet.go
├── paddle
│ ├── config.go Config 的 GO references to C
│ ├── predictor.go Predictor 的 GO references to C
│ ├── tensor.go Tensor 的 GO references to C
│ └── common.go
├── paddle_c 本章节第1步中的 paddle_inference_c_install_dir
│ ├── paddle
│ │ ├── include
│ │ │ └── paddle_c_api.h C/GO 预测库头文件
│ │ └── lib
│ │ ├── libpaddle_fluid_c.a C/GO 静态预测库文件
│ │ └── libpaddle_fluid_c.so C/GO 动态预测库文件
│ └── third_party
├── data 本章节第2步中下载的模型和数据文件夹
│ ├── model
│ │ ├── __model__
│ │ └── __params__
│ ├── data.txt
│ └── result.txt
└── README_cn.md GO Demo README 说明
5. 执行预测程序¶
注意:需要现将动态库文件 libpaddle_fluid_c.so 所在路径加入 LD_LIBRARY_PATH,否则会出现无法找到库文件的错误。
# 执行预测程序
export LD_LIBRARY_PATH=`pwd`/paddle_c/paddle/lib:$LD_LIBRARY_PATH
go run ./demo/mobilenet.go
成功执行之后,得到的预测输出结果如下:
# 程序输出结果如下
WARNING: Logging before InitGOogleLogging() is written to STDERR
I1211 11:46:11.061076 21893 pd_config.cc:43] data/model/__model__
I1211 11:46:11.061228 21893 pd_config.cc:48] data/model/__model__
W1211 11:46:11.061488 21893 analysis_predictor.cc:1052] Deprecated. Please use CreatePredictor instead.
============== paddle inference ==============
input num: 1
input name: image
output num: 1
output name: image
============== run inference =================
============= parse output ===================
v: +3.000000e+000 +2.676507e-002 ...
137 6
137
GO 预测程序开发说明¶
使用 Paddle Inference 开发 GO 预测程序仅需以下六个步骤:
(1) 引用 Paddle 的 GO references to C 目录
import "/pathto/Paddle/go/paddle"
(2) 创建配置对象,并指定预测模型路径
// 配置 PD_AnalysisConfig
config := paddle.NewAnalysisConfig()
// 设置预测模型路径,即为本小节第2步中下载的模型
config.SetModel("data/model/__model__", "data/model/__params__")
(3) 根据Config创建预测对象
predictor := paddle.NewPredictor(config)
(4) 设置模型输入和输出 Tensor
// 创建输入 Tensor
input := predictor.GetInputTensors()[0]
output := predictor.GetOutputTensors()[0]
filename := "data/data.txt"
data := ReadData(filename)
input.SetValue(data[:1 * 3 * 300 * 300])
input.Reshape([]int32{1, 3, 300, 300})
(5) 执行预测引擎
predictor.SetZeroCopyInput(input)
predictor.ZeroCopyRun()
predictor.GetZeroCopyOutput(output)
(6) 获得预测结果
// 获取预测输出 Tensor 信息
output_val := output.Value()
value := reflect.ValueOf(output_val)
shape, dtype := paddle.ShapeAndTypeOf(value)
// 获取输出 float32 数据
v := value.Interface().([][]float32)
println("v: ", v[0][0], v[0][1], "...")
println(shape[0], shape[1])
println(output.Shape()[0])
预测示例 (R)¶
本章节包含2部分内容:(1) 运行 R 示例程序;(2) R 预测程序开发说明。
运行 R 示例程序¶
1. 安装 R 预测环境¶
方法1: Paddle Inference 的 R 语言预测依赖 Paddle Python环境,请先根据 官方主页-快速安装 页面进行自行安装或编译,当前支持 pip/conda 安装,docker镜像 以及源码编译等多种方式来准备 Paddle Inference Python 环境。之后需要安装 R 运行paddle预测所需要的库
Rscript -e 'install.packages("reticulate", repos="https://cran.rstudio.com")'
方法2: 将 Paddle/r/Dockerfile 下载到本地,使用以下命令构建 Docker 镜像,启动 Docker 容器:
# 构建 Docker 镜像
docker build -t paddle-rapi:latest .
# 启动 Docker 容器
docker run --rm -it paddle-rapi:latest bash
2. 准备预测部署模型¶
下载 resnet50 模型后解压,得到 Paddle Combined 形式的模型,位于文件夹 model 下。如需查看模型结构,可将 model 文件重命名为 __model__,然后通过模型可视化工具 Netron 打开。
wget http://paddle-inference-dist.bj.bcebos.com/resnet50_model.tar.gz
tar zxf resnet50_model.tar.gz
# 获得模型目录即文件如下
model/
├── model
└── params
3. 准备预测部署程序¶
将以下代码保存为 r_demo.r 文件,并添加可执行权限:
#!/usr/bin/env Rscript
library(reticulate) # call Python library
use_python("/opt/python3.7/bin/python")
np <- import("numpy")
paddle_infer <- import("paddle.inference")
predict_run_resnet50 <- function() {
# 创建 config
config <- paddle_infer$Config("model/model", "model/params")
# 根据 config 创建 predictor
predictor <- paddle_infer$create_predictor(config)
# 获取输入的名称
input_names <- predictor$get_input_names()
input_handle <- predictor$get_input_handle(input_names[1])
# 设置输入
input_data <- np$random$randn(as.integer(1 * 3 * 318 * 318))
input_data <- np_array(input_data, dtype="float32")$reshape(as.integer(c(1, 3, 318, 318)))
input_handle$reshape(as.integer(c(1, 3, 318, 318)))
input_handle$copy_from_cpu(input_data)
# 运行predictor
predictor$run()
# 获取输出
output_names <- predictor$get_output_names()
output_handle <- predictor$get_output_handle(output_names[1])
output_data <- output_handle$copy_to_cpu()
output_data <- np_array(output_data)$reshape(as.integer(-1))
print(paste0("Output data size is: ", output_data$size))
print(paste0("Output data shape is: ", output_data$shape))
}
if (!interactive()) {
predict_run_resnet50()
}
4. 执行预测程序¶
# 将本章节第2步中下载的模型文件夹移动到当前目录
./r_demo.r
成功执行之后,得到的预测输出结果如下:
# 程序输出结果如下
grep: warning: GREP_OPTIONS is deprecated; please use an alias or script
W1215 10:48:45.627841 52293 analysis_predictor.cc:134] Profiler is activated, which might affect the performance
--- Running analysis [ir_graph_build_pass]
--- Running analysis [ir_graph_clean_pass]
--- Running analysis [ir_analysis_pass]
--- Running IR pass [simplify_with_basic_ops_pass]
--- Running IR pass [attention_lstm_fuse_pass]
--- Running IR pass [seqconv_eltadd_relu_fuse_pass]
--- Running IR pass [seqpool_cvm_concat_fuse_pass]
--- Running IR pass [mul_lstm_fuse_pass]
--- Running IR pass [fc_gru_fuse_pass]
--- Running IR pass [mul_gru_fuse_pass]
--- Running IR pass [seq_concat_fc_fuse_pass]
--- Running IR pass [fc_fuse_pass]
I1215 10:48:46.117144 52293 graph_pattern_detector.cc:100] --- detected 1 subgraphs
--- Running IR pass [repeated_fc_relu_fuse_pass]
--- Running IR pass [squared_mat_sub_fuse_pass]
--- Running IR pass [conv_bn_fuse_pass]
--- Running IR pass [conv_eltwiseadd_bn_fuse_pass]
I1215 10:48:46.341869 52293 graph_pattern_detector.cc:100] --- detected 53 subgraphs
--- Running IR pass [conv_transpose_bn_fuse_pass]
--- Running IR pass [conv_transpose_eltwiseadd_bn_fuse_pass]
--- Running IR pass [is_test_pass]
--- Running IR pass [runtime_context_cache_pass]
--- Running analysis [ir_params_sync_among_devices_pass]
--- Running analysis [adjust_cudnn_workspace_size_pass]
--- Running analysis [inference_op_replace_pass]
--- Running analysis [ir_graph_to_program_pass]
I1215 10:48:46.388198 52293 analysis_predictor.cc:537] ======= optimize end =======
I1215 10:48:46.388363 52293 naive_executor.cc:102] --- skip [feed], feed -> data
I1215 10:48:46.389770 52293 naive_executor.cc:102] --- skip [AddmmBackward190.fc.output.1.tmp_1], fetch -> fetch
[1] "Output data size is: 512"
[1] "Output data shape is: (512,)"
R 预测程序开发说明¶
使用 Paddle Inference 开发 R 预测程序仅需以下五个步骤:
(1) 在 R 中引入 Paddle Python 预测库
library(reticulate) # 调用Paddle
use_python("/opt/python3.7/bin/python")
np <- import("numpy")
paddle_infer <- import("paddle.inference")
(2) 创建配置对象,并根据需求配置,详细可参考 Python API 文档 - Config
# 创建 config,并设置预测模型路径
config <- paddle_infer$Config("model/model", "model/params")
(3) 根据Config创建预测对象,详细可参考 Python API 文档 - Predictor
predictor <- paddle_infer$create_predictor(config)
(4) 设置模型输入 Tensor,详细可参考 Python API 文档 - Tensor
# 获取输入的名称
input_names <- predictor$get_input_names()
input_handle <- predictor$get_input_handle(input_names[1])
# 设置输入
input_data <- np$random$randn(as.integer(1 * 3 * 318 * 318))
input_data <- np_array(input_data, dtype="float32")$reshape(as.integer(c(1, 3, 318, 318)))
input_handle$reshape(as.integer(c(1, 3, 318, 318)))
input_handle$copy_from_cpu(input_data)
(5) 执行预测,详细可参考 Python API 文档 - Predictor
predictor$run()
(5) 获得预测结果,详细可参考 Python API 文档 - Tensor
output_names <- predictor$get_output_names()
output_handle <- predictor$get_output_handle(output_names[1])
output_data <- output_handle$copy_to_cpu()
output_data <- np_array(output_data)$reshape(as.integer(-1)) # numpy.ndarray类型
源码编译¶
什么时候需要源码编译?¶
深度学习的发展十分迅速,对科研或工程人员来说,可能会遇到一些需要自己开发op的场景,可以在python层面编写op,但如果对性能有严格要求的话则必须在C++层面开发op,对于这种情况,需要用户源码编译飞桨,使之生效。 此外对于绝大多数使用C++将模型部署上线的工程人员来说,您可以直接通过飞桨官网下载已编译好的预测库,快捷开启飞桨使用之旅。飞桨官网 提供了多个不同环境下编译好的预测库。如果用户环境与官网提供环境不一致(如cuda 、cudnn、tensorrt版本不一致等),或对飞桨源代码有修改需求,或希望进行定制化构建,可查阅本文档自行源码编译得到预测库。
编译原理¶
一:目标产物
飞桨框架的源码编译包括源代码的编译和链接,最终生成的目标产物包括:
含有 C++ 接口的头文件及其二进制库:用于C++环境,将文件放到指定路径即可开启飞桨使用之旅。
Python Wheel 形式的安装包:用于Python环境,此安装包需要参考 飞桨安装教程 进行安装操作。也就是说,前面讲的pip安装属于在线安装,这里属于本地安装。
二:基础概念
飞桨主要由C++语言编写,通过pybind工具提供了Python端的接口,飞桨的源码编译主要包括编译和链接两步。 * 编译过程由编译器完成,编译器以编译单元(后缀名为 .cc 或 .cpp 的文本文件)为单位,将 C++ 语言 ASCII 源代码翻译为二进制形式的目标文件。一个工程通常由若干源码文件组织得到,所以编译完成后,将生成一组目标文件。 * 链接过程使分离编译成为可能,由链接器完成。链接器按一定规则将分离的目标文件组合成一个能映射到内存的二进制程序文件,并解析引用。由于这个二进制文件通常包含源码中指定可被外部用户复用的函数接口,所以也被称作函数库。根据链接规则不同,链接可分为静态和动态链接。静态链接对目标文件进行归档;动态链接使用地址无关技术,将链接放到程序加载时进行。 配合包含声明体的头文件(后缀名为 .h 或 .hpp),用户可以复用程序库中的代码开发应用。静态链接构建的应用程序可独立运行,而动态链接程序在加载运行时需到指定路径下搜寻其依赖的二进制库。
三:编译方式
飞桨框架的设计原则之一是满足不同平台的可用性。然而,不同操作系统惯用的编译和链接器是不一样的,使用它们的命令也不一致。比如,Linux 一般使用 GNU 编译器套件(GCC),Windows 则使用 Microsoft Visual C++(MSVC)。为了统一编译脚本,飞桨使用了支持跨平台构建的 CMake,它可以输出上述编译器所需的各种 Makefile 或者 Project 文件。 为方便编译,框架对常用的CMake命令进行了封装,如仿照 Bazel工具封装了 cc_binary 和 cc_library ,分别用于可执行文件和库文件的产出等,对CMake感兴趣的同学可在 cmake/generic.cmake 中查看具体的实现逻辑。Paddle的CMake中集成了生成python wheel包的逻辑,对如何生成wheel包感兴趣的同学可参考 相关文档 。
编译步骤¶
飞桨分为 CPU 版本和 GPU 版本。如果您的计算机没有 Nvidia GPU,请选择 CPU 版本构建安装。如果您的计算机含有 Nvidia GPU( 1.0 且预装有 CUDA / CuDNN,也可选择 GPU 版本构建安装。
推荐配置及依赖项
1、稳定的 Github 连接,主频 1 GHz 以上的多核处理器,9 GB 以上磁盘空间。 2、GCC 版本 4.8 或者 8.2;或者 Visual Studio 2015 Update 3。 3、Python 版本 2.7 或 3.5 以上,pip 版本 9.0 及以上;CMake v3.10 及以上;Git 版本 2.17 及以上。请将可执行文件放入系统环境变量中以方便运行。 4、GPU 版本额外需要 Nvidia CUDA 9 / 10,CuDNN v7 及以上版本。根据需要还可能依赖 TensorRT。
基于 Ubuntu 18.04¶
一:环境准备
除了本节开头提到的依赖,在 Ubuntu 上进行飞桨的源码编译,您还需要准备 GCC8 编译器等工具,可使用下列命令安装:
sudo apt-get install gcc g++ make cmake git vim unrar python3 python3-dev python3-pip swig wget patchelf libopencv-dev
pip3 install numpy protobuf wheel setuptools
若需启用 cuda 加速,需准备 cuda、cudnn。上述工具的安装请参考 nvidia 官网,以 cuda10.1,cudnn7.6 为例配置 cuda 环境。
# cuda
sh cuda_10.1.168_418.67_linux.run
export PATH=/usr/local/cuda-10.1/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-10.1/${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
# cudnn
tar -xzvf cudnn-10.1-linux-x64-v7.6.4.38.tgz
sudo cp -a cuda/include/cudnn.h /usr/local/cuda/include/
sudo cp -a cuda/lib64/libcudnn* /usr/local/cuda/lib64/
编译飞桨过程中可能会打开很多文件,Ubuntu 18.04 默认设置最多同时打开的文件数是1024(参见 ulimit -a),需要更改这个设定值。
在 /etc/security/limits.conf 文件中添加两行。
* hard noopen 102400
* soft noopen 102400
重启计算机,重启后执行以下指令,请将${user}切换成当前用户名。
su ${user}
ulimit -n 102400
若在 TensorRT 依赖编译过程中出现头文件虚析构函数报错,请在 NvInfer.h 文件中为 class IPluginFactory 和 class IGpuAllocator 分别添加虚析构函数:
virtual ~IPluginFactory() {};
virtual ~IGpuAllocator() {};
二:编译命令
使用 Git 将飞桨代码克隆到本地,并进入目录,切换到稳定版本(git tag显示的标签名,如 release/2.0)。 飞桨使用 develop 分支进行最新特性的开发,使用 release 分支发布稳定版本。在 GitHub 的 Releases 选项卡中,可以看到飞桨版本的发布记录。
git clone https://github.com/PaddlePaddle/Paddle.git
cd Paddle
git checkout release/2.0
下面以 GPU 版本为例说明编译命令。其他环境可以参考“CMake编译选项表”修改对应的cmake选项。比如,若编译 CPU 版本,请将 WITH_GPU 设置为 OFF。
# 创建并进入 build 目录
mkdir build_cuda && cd build_cuda
# 执行cmake指令
cmake .. -DPY_VERSION=3 \
-DWITH_TESTING=OFF \
-DWITH_MKL=ON \
-DWITH_GPU=ON \
-DON_INFER=ON \
..
使用make编译
make -j4
编译成功后可在dist目录找到生成的.whl包
pip3 install python/dist/paddlepaddle-2.0.0-cp38-cp38-linux_x86_64.whl
预测库编译
make inference_lib_dist -j4
cmake编译环境表
以下介绍的编译方法都是通用步骤,根据环境对应修改cmake选项即可。
选项 |
说明 |
默认值 |
|---|---|---|
WITH_GPU |
是否支持GPU |
ON |
WITH_AVX |
是否编译含有AVX指令集的飞桨二进制文件 |
ON |
WITH_PYTHON |
是否内嵌PYTHON解释器并编译Wheel安装包 |
ON |
WITH_TESTING |
是否开启单元测试 |
OFF |
WITH_MKL |
是否使用MKL数学库,如果为否,将使用OpenBLAS |
ON |
WITH_SYSTEM_BLAS |
是否使用系统自带的BLAS |
OFF |
WITH_DISTRIBUTE |
是否编译带有分布式的版本 |
OFF |
WITH_BRPC_RDMA |
是否使用BRPC,RDMA作为RPC协议 |
OFF |
ON_INFER |
是否打开预测优化 |
OFF |
CUDA_ARCH_NAME |
是否只针对当前CUDA架构编译 |
All:编译所有可支持的CUDA架构;Auto:自动识别当前环境的架构编译 |
TENSORRT_ROOT |
TensorRT_lib的路径,该路径指定后会编译TRT子图功能eg:/paddle/nvidia/TensorRT/ |
/usr |
三:NVIDIA Jetson嵌入式硬件预测库源码编译
NVIDIA Jetson是NVIDIA推出的嵌入式AI平台,Paddle Inference支持在 NVIDIA Jetson平台上编译预测库。具体步骤如下:
1、准备环境:
# 开启硬件性能模式
sudo nvpmodel -m 0 && sudo jetson_clocks
# 增加 DDR 可用空间,Xavier 默认内存为 16 GB,所以内存足够,如在 Nano 上尝试,请执行如下操作。
sudo fallocate -l 5G /var/swapfile
sudo chmod 600 /var/swapfile
sudo mkswap /var/swapfile
sudo swapon /var/swapfile
sudo bash -c 'echo "/var/swapfile swap swap defaults 0 0" >> /etc/fstab'
2、编译预测库:
cd Paddle
mkdir build
cd build
cmake .. \
-DWITH_CONTRIB=OFF \
-DWITH_MKL=OFF \
-DWITH_MKLDNN=OFF \
-DWITH_TESTING=OFF \
-DCMAKE_BUILD_TYPE=Release \
-DON_INFER=ON \
-DWITH_PYTHON=OFF \
-DWITH_XBYAK=OFF \
-DWITH_NV_JETSON=ON
make -j4
# 生成预测lib
make inference_lib_dist -j4
3、参照 官网样例 进行测试。
基于 Windows 10¶
一:环境准备
除了本节开头提到的依赖,在 Windows 10 上编译飞桨,您还需要准备 Visual Studio 2015 Update 3。飞桨正在对更高版本的编译支持做完善支持。
在命令提示符输入下列命令,安装必需的 Python 组件。
pip3 install numpy protobuf wheel
二:编译命令
使用 Git 将飞桨代码克隆到本地,并进入目录,切换到稳定版本(git tag显示的标签名,如 release/2.0)。 飞桨使用 develop 分支进行最新特性的开发,使用 release 分支发布稳定版本。在 GitHub 的 Releases 选项卡中,可以看到飞桨版本的发布记录。
git clone https://github.com/PaddlePaddle/Paddle.git
cd Paddle
git checkout release/2.0
创建一个构建目录,并在其中执行 CMake,生成解决方案文件 Solution File,以编译 CPU 版本为例说明编译命令,其他环境可以参考“CMake编译选项表”修改对应的cmake选项。
mkdir build
cd build
cmake .. -G "Visual Studio 14 2015 Win64" -A x64 -DWITH_GPU=OFF -DWITH_TESTING=OFF -DON_INFER=ON
-DCMAKE_BUILD_TYPE=Release -DPY_VERSION=3
使用 Visual Studio 打开解决方案文件,在窗口顶端的构建配置菜单中选择 Release x64,单击生成解决方案,等待构建完毕即可。
cmake编译环境表
选项 |
说明 |
默认值 |
|---|---|---|
WITH_GPU |
是否支持GPU |
ON |
WITH_AVX |
是否编译含有AVX指令集的飞桨二进制文件 |
ON |
WITH_PYTHON |
是否内嵌PYTHON解释器并编译Wheel安装包 |
ON |
WITH_TESTING |
是否开启单元测试 |
OFF |
WITH_MKL |
是否使用MKL数学库,如果为否,将使用OpenBLAS |
ON |
WITH_SYSTEM_BLAS |
是否使用系统自带的BLAS |
OFF |
WITH_DISTRIBUTE |
是否编译带有分布式的版本 |
OFF |
WITH_BRPC_RDMA |
是否使用BRPC,RDMA作为RPC协议 |
OFF |
ON_INFER |
是否打开预测优化 |
OFF |
CUDA_ARCH_NAME |
是否只针对当前CUDA架构编译 |
All:编译所有可支持的CUDA架构;Auto:自动识别当前环境的架构编译 |
TENSORRT_ROOT |
TensorRT_lib的路径,该路径指定后会编译TRT子图功能eg:/paddle/nvidia/TensorRT/ |
/usr |
结果验证
一:python whl包
编译完毕后,会在 python/dist 目录下生成一个 Python Wheel 安装包,安装测试的命令为:
pip3 install paddlepaddle-2.0.0-cp38-cp38-win_amd64.whl
安装完成后,可以使用 python3 进入python解释器,输入以下指令,出现 `Your Paddle Fluid is installed successfully! ` ,说明安装成功。
import paddle.fluid as fluid
fluid.install_check.run_check()
二:c++ lib
预测库编译后,所有产出均位于build目录下的fluid_inference_install_dir目录内,目录结构如下。version.txt 中记录了该预测库的版本信息,包括Git Commit ID、使用OpenBlas或MKL数学库、CUDA/CUDNN版本号。
build/fluid_inference_install_dir
├── CMakeCache.txt
├── paddle
│ ├── include
│ │ ├── paddle_anakin_config.h
│ │ ├── paddle_analysis_config.h
│ │ ├── paddle_api.h
│ │ ├── paddle_inference_api.h
│ │ ├── paddle_mkldnn_quantizer_config.h
│ │ └── paddle_pass_builder.h
│ └── lib
│ ├── libpaddle_fluid.a (Linux)
│ ├── libpaddle_fluid.so (Linux)
│ └── libpaddle_fluid.lib (Windows)
├── third_party
│ ├── boost
│ │ └── boost
│ ├── eigen3
│ │ ├── Eigen
│ │ └── unsupported
│ └── install
│ ├── gflags
│ ├── glog
│ ├── mkldnn
│ ├── mklml
│ ├── protobuf
│ ├── xxhash
│ └── zlib
└── version.txt
Include目录下包括了使用飞桨预测库需要的头文件,lib目录下包括了生成的静态库和动态库,third_party目录下包括了预测库依赖的其它库文件。
您可以编写应用代码,与预测库联合编译并测试结果。请参考 C++ 预测库 API 使用 一节。
基于 MacOSX 10.14¶
一:环境准备
在编译 Paddle 前,需要在 MacOSX 预装 Apple Clang 11.0 和 Python 3.8,以及 python-pip。请使用下列命令安装 Paddle 编译必需的 Python 组件包。
pip3 install numpy protobuf wheel setuptools
二:编译命令
使用 Git 将飞桨代码克隆到本地,并进入目录,切换到稳定版本(git tag显示的标签名,如 release/2.0)。 飞桨使用 develop 分支进行最新特性的开发,使用 release 分支发布稳定版本。在 GitHub 的 Releases 选项卡中,可以看到飞桨版本的发布记录。
git clone https://github.com/PaddlePaddle/Paddle.git
cd Paddle
git checkout release/2.0
下面以 CPU-MKL 版本为例说明编译命令。
# 创建并进入 build 目录
mkdir build && cd build
# 执行cmake指令
cmake .. -DPY_VERSION=3 \
-DWITH_TESTING=OFF \
-DWITH_MKL=ON \
-DON_INFER=ON \
..
使用make编译
make -j4
编译成功后可在dist目录找到生成的.whl包
pip3 install python/dist/paddlepaddle-2.0.0-cp38-cp38-macosx_10_14_x86_64.whl
预测库编译
make inference_lib_dist -j4
cmake编译环境表
以下介绍的编译方法都是通用步骤,根据环境对应修改cmake选项即可。
选项 |
说明 |
默认值 |
|---|---|---|
WITH_GPU |
是否支持GPU |
ON |
WITH_AVX |
是否编译含有AVX指令集的飞桨二进制文件 |
ON |
WITH_PYTHON |
是否内嵌PYTHON解释器并编译Wheel安装包 |
ON |
WITH_TESTING |
是否开启单元测试 |
OFF |
WITH_MKL |
是否使用MKL数学库,如果为否,将使用OpenBLAS |
ON |
WITH_SYSTEM_BLAS |
是否使用系统自带的BLAS |
OFF |
WITH_DISTRIBUTE |
是否编译带有分布式的版本 |
OFF |
WITH_BRPC_RDMA |
是否使用BRPC,RDMA作为RPC协议 |
OFF |
ON_INFER |
是否打开预测优化 |
OFF |
CUDA_ARCH_NAME |
是否只针对当前CUDA架构编译 |
All:编译所有可支持的CUDA架构;Auto:自动识别当前环境的架构编译 |
TENSORRT_ROOT |
TensorRT_lib的路径,该路径指定后会编译TRT子图功能eg:/paddle/nvidia/TensorRT/ |
/usr |
飞腾/鲲鹏下从源码编译¶
环境准备¶
处理器:FT2000+/Kunpeng 920 2426SK
操作系统:麒麟v10/UOS
Python 版本 2.7.15+/3.5.1+/3.6/3.7/3.8 (64 bit)
pip 或 pip3 版本 9.0.1+ (64 bit)
飞腾FT2000+和鲲鹏920处理器均为ARMV8架构,在该架构上编译Paddle的方式一致,本文以FT2000+为例,介绍Paddle的源码编译。
安装步骤¶
目前在FT2000+处理器加国产化操作系统(麒麟UOS)上安装Paddle,只支持源码编译的方式,接下来详细介绍各个步骤。
源码编译¶
Paddle依赖cmake进行编译构建,需要cmake版本>=3.10,如果操作系统提供的源包括了合适版本的cmake,直接安装即可,否则需要源码安装
``` wget https://github.com/Kitware/CMake/releases/download/v3.16.8/cmake-3.16.8.tar.gz tar -xzf cmake-3.16.8.tar.gz && cd cmake-3.16.8 ./bootstrap && make && sudo make install ```
Paddle内部使用patchelf来修改动态库的rpath,如果操作系统提供的源包括了patchelf,直接安装即可,否则需要源码安装,请参考patchelf官方文档,后续会考虑在ARM上移出该依赖。
``` ./bootstrap.sh ./configure make make check sudo make install ```
根据requirments.txt安装Python依赖库,在飞腾加国产化操作系统环境中,pip安装可能失败或不能正常工作,主要依赖通过源或源码安装的方式安装依赖库,建议使用系统提供源的方式安装依赖库。
将Paddle的源代码克隆到当下目录下的Paddle文件夹中,并进入Paddle目录
git clone https://github.com/PaddlePaddle/Paddle.git
cd Paddle
切换到较稳定release分支下进行编译:
git checkout [分支名]
例如:
git checkout release/2.0-rc1
并且请创建并进入一个叫build的目录下:
mkdir build && cd build
链接过程中打开文件数较多,可能超过系统默认限制导致编译出错,设置进程允许打开的最大文件数:
ulimit -n 4096
执行cmake:
具体编译选项含义请参见编译选项表
For Python2:
cmake .. -DPY_VERSION=2 -DPYTHON_EXECUTABLE=`which python2` -DWITH_ARM=ON -DWITH_TESTING=OFF -DCMAKE_BUILD_TYPE=Release -DON_INFER=ON -DWITH_XBYAK=OFF
For Python3:
cmake .. -DPY_VERSION=3 -DPYTHON_EXECUTABLE=`which python3` -DWITH_ARM=ON -DWITH_TESTING=OFF -DCMAKE_BUILD_TYPE=Release -DON_INFER=ON -DWITH_XBYAK=OFF
使用以下命令来编译,注意,因为处理器为ARM架构,如果不加
TARGET=ARMV8则会在编译的时候报错。make TARGET=ARMV8 -j$(nproc)
编译成功后进入
Paddle/build/python/dist目录下找到生成的.whl包。在当前机器或目标机器安装编译好的
.whl包:pip install -U(whl包的名字)`或`pip3 install -U(whl包的名字)
恭喜,至此您已完成PaddlePaddle在FT环境下的编译安装。
验证安装¶
安装完成后您可以使用 python 或 python3 进入python解释器,输入import paddle.fluid as fluid ,再输入
fluid.install_check.run_check()
如果出现Your Paddle Fluid is installed succesfully!,说明您已成功安装。
在mobilenetv1和resnet50模型上测试
wget -O profile.tar https://paddle-cetc15.bj.bcebos.com/profile.tar?authorization=bce-auth-v1/4409a3f3dd76482ab77af112631f01e4/2020-10-09T10:11:53Z/-1/host/786789f3445f498c6a1fd4d9cd3897ac7233700df0c6ae2fd78079eba89bf3fb
tar xf profile.tar && cd profile
python resnet.py --model_file ResNet50_inference/model --params_file ResNet50_inference/params
# 正确输出应为:[0.0002414 0.00022418 0.00053661 0.00028639 0.00072682 0.000213
# 0.00638718 0.00128127 0.00013535 0.0007676 ]
python mobilenetv1.py --model_file mobilenetv1/model --params_file mobilenetv1/params
# 正确输出应为:[0.00123949 0.00100392 0.00109539 0.00112206 0.00101901 0.00088412
# 0.00121536 0.00107679 0.00106071 0.00099605]
python ernie.py --model_dir ernieL3H128_model/
# 正确输出应为:[0.49879393 0.5012061 ]
备注¶
已在ARM架构下测试过resnet50, mobilenetv1, ernie, ELMo等模型,基本保证了预测使用算子的正确性,如果您在使用过程中遇到计算结果错误,编译失败等问题,请到issue中留言,我们会及时解决。
预测文档见doc,使用示例见Paddle-Inference-Demo
申威下从源码编译¶
环境准备¶
处理器:SW6A
操作系统:普华, iSoft Linux 5
Python 版本 2.7.15+/3.5.1+/3.6/3.7/3.8 (64 bit)
pip 或 pip3 版本 9.0.1+ (64 bit)
申威机器为SW架构,目前生态支持的软件比较有限,本文以比较trick的方式在申威机器上源码编译Paddle,未来会随着申威软件的完善不断更新。
安装步骤¶
本文在申威处理器下安装Paddle,接下来详细介绍各个步骤。
源码编译¶
将Paddle的源代码克隆到当下目录下的Paddle文件夹中,并进入Paddle目录
git clone https://github.com/PaddlePaddle/Paddle.git cd Paddle
切换到较稳定release分支下进行编译:
git checkout [分支/标签名]
例如:
git checkout release/2.0-rc1
Paddle依赖cmake进行编译构建,需要cmake版本>=3.10,检查操作系统源提供cmake的版本,使用源的方式直接安装cmake,
apt install cmake, 检查cmake版本,cmake --version, 如果cmake >= 3.10则不需要额外的操作,否则请修改Paddle主目录的CMakeLists.txt,cmake_minimum_required(VERSION 3.10)修改为cmake_minimum_required(VERSION 3.0).由于申威暂不支持openblas,所以在此使用blas + cblas的方式,在此需要源码编译blas和cblas。
pushd /opt wget http://www.netlib.org/blas/blas-3.8.0.tgz wget http://www.netlib.org/blas/blast-forum/cblas.tgz tar xzf blas-3.8.0.tgz tar xzf cblas.tgz pushd BLAS-3.8.0 make popd pushd CBLAS # 修改Makefile.in中BLLIB为BLAS-3.8.0的编译产物blas_LINUX.a make pushd lib export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$PWD ln -s cblas_LINUX.a libcblas.a cp ../../BLAS-3.8.0/blas_LINUX.a . ln -s blas_LINUX.a libblas.a popd popd popd
根据requirments.txt安装Python依赖库,注意在申威系统中一般无法直接使用pip或源码编译安装python依赖包,建议使用源的方式安装,如果遇到部分依赖包无法安装的情况,请联系操作系统服务商提供支持。此外也可以通过pip安装的时候加–no-deps的方式来避免依赖包的安装,但该种方式可能导致包由于缺少依赖不可用。
请创建并进入一个叫build的目录下:
mkdir build && cd build
链接过程中打开文件数较多,可能超过系统默认限制导致编译出错,设置进程允许打开的最大文件数:
ulimit -n 4096
执行cmake:
具体编译选项含义请参见编译选项表
``` CBLAS_ROOT=/opt/CBLAS # For Python2: cmake .. -DPY_VERSION=2 -DPYTHON_EXECUTABLE=`which python2` -DWITH_MKL=OFF -DWITH_TESTING=OFF -DCMAKE_BUILD_TYPE=Release -DON_INFER=ON -DWITH_PYTHON=ON -DREFERENCE_CBLAS_ROOT=${CBLAS_ROOT} -DWITH_CRYPTO=OFF -DWITH_XBYAK=OFF -DWITH_SW=ON -DCMAKE_CXX_FLAGS="-Wno-error -w" # For Python3: cmake .. -DPY_VERSION=3 -DPYTHON_EXECUTABLE=`which python3` -DWITH_MKL=OFF -DWITH_TESTING=OFF -DCMAKE_BUILD_TYPE=Release -DON_INFER=ON -DWITH_PYTHON=ON -DREFERENCE_CBLAS_ROOT=${CBLAS_ROOT} -DWITH_CRYPTO=OFF -DWITH_XBYAK=OFF -DWITH_SW=ON -DCMAKE_CXX_FLAGS="-Wno-error -w" ```编译。
make -j$(nproc)
编译成功后进入
Paddle/build/python/dist目录下找到生成的.whl包。在当前机器或目标机器安装编译好的
.whl包:python2 -m pip install -U(whl包的名字)`或`python3 -m pip install -U(whl包的名字)
恭喜,至此您已完成PaddlePaddle在FT环境下的编译安装。
验证安装¶
安装完成后您可以使用 python 或 python3 进入python解释器,输入import paddle.fluid as fluid ,再输入
fluid.install_check.run_check()
如果出现Your Paddle Fluid is installed succesfully!,说明您已成功安装。
在mobilenetv1和resnet50模型上测试
wget -O profile.tar https://paddle-cetc15.bj.bcebos.com/profile.tar?authorization=bce-auth-v1/4409a3f3dd76482ab77af112631f01e4/2020-10-09T10:11:53Z/-1/host/786789f3445f498c6a1fd4d9cd3897ac7233700df0c6ae2fd78079eba89bf3fb
tar xf profile.tar && cd profile
python resnet.py --model_file ResNet50_inference/model --params_file ResNet50_inference/params
# 正确输出应为:[0.0002414 0.00022418 0.00053661 0.00028639 0.00072682 0.000213
# 0.00638718 0.00128127 0.00013535 0.0007676 ]
python mobilenetv1.py --model_file mobilenetv1/model --params_file mobilenetv1/params
# 正确输出应为:[0.00123949 0.00100392 0.00109539 0.00112206 0.00101901 0.00088412
# 0.00121536 0.00107679 0.00106071 0.00099605]
python ernie.py --model_dir ernieL3H128_model/
# 正确输出应为:[0.49879393 0.5012061 ]
如何卸载¶
请使用以下命令卸载PaddlePaddle:
python3 -m pip uninstall paddlepaddle` 或 `python3 -m pip uninstall paddlepaddle
备注¶
已在申威下测试过resnet50, mobilenetv1, ernie, ELMo等模型,基本保证了预测使用算子的正确性,但可能会遇到浮点异常的问题,该问题我们后续会和申威一起解决,如果您在使用过程中遇到计算结果错误,编译失败等问题,请到issue中留言,我们会及时解决。
预测文档见doc,使用示例见Paddle-Inference-Demo
兆芯下从源码编译¶
环境准备¶
处理器:ZHAOXIN KaiSheng KH-37800D
操作系统:centos7
Python 版本 2.7.15+/3.5.1+/3.6/3.7/3.8 (64 bit)
pip 或 pip3 版本 9.0.1+ (64 bit)
兆芯为x86架构,编译方法与Linux下从源码编译cpu版一致。
安装步骤¶
本文在ZHAOXIN处理器下安装Paddle,接下来详细介绍各个步骤。
源码编译¶
Paddle依赖cmake进行编译构建,需要cmake版本>=3.10,如果操作系统提供的源包括了合适版本的cmake,直接安装即可,否则需要源码安装
``` wget https://github.com/Kitware/CMake/releases/download/v3.16.8/cmake-3.16.8.tar.gz tar -xzf cmake-3.16.8.tar.gz && cd cmake-3.16.8 ./bootstrap && make && sudo make install ```
Paddle内部使用patchelf来修改动态库的rpath,如果操作系统提供的源包括了patchelf,直接安装即可,否则需要源码安装,请参考patchelf官方文档。
``` ./bootstrap.sh ./configure make make check sudo make install ```
将Paddle的源代码克隆到当下目录下的Paddle文件夹中,并进入Paddle目录
git clone https://github.com/PaddlePaddle/Paddle.git cd Paddle
切换到较稳定release分支下进行编译:
git checkout [分支/标签名]
例如:
git checkout release/2.0-rc1
根据requirments.txt安装Python依赖库。
pip install -r python/requirments.txt
请创建并进入一个叫build的目录下:
mkdir build && cd build
链接过程中打开文件数较多,可能超过系统默认限制导致编译出错,设置进程允许打开的最大文件数:
ulimit -n 4096
执行cmake:
具体编译选项含义请参见编译选项表
``` # For Python2: cmake .. -DPY_VERSION=2 -DPYTHON_EXECUTABLE=`which python2` -DWITH_MKL=ON -DWITH_TESTING=OFF -DCMAKE_BUILD_TYPE=Release -DON_INFER=ON -DWITH_PYTHON=ON # For Python3: cmake .. -DPY_VERSION=3 -DPYTHON_EXECUTABLE=`which python3` -DWITH_MKL=ON -DWITH_TESTING=OFF -DCMAKE_BUILD_TYPE=Release -DON_INFER=ON -DWITH_PYTHON=ON ```
编译。
make -j$(nproc)
编译成功后进入
Paddle/build/python/dist目录下找到生成的.whl包。在当前机器或目标机器安装编译好的
.whl包:python2 -m pip install -U(whl包的名字)`或`python3 -m pip install -U(whl包的名字)
恭喜,至此您已完成PaddlePaddle在FT环境下的编译安装。
验证安装¶
安装完成后您可以使用 python 或 python3 进入python解释器,输入import paddle.fluid as fluid ,再输入
fluid.install_check.run_check()
如果出现Your Paddle Fluid is installed succesfully!,说明您已成功安装。
在mobilenetv1和resnet50模型上测试
wget -O profile.tar https://paddle-cetc15.bj.bcebos.com/profile.tar?authorization=bce-auth-v1/4409a3f3dd76482ab77af112631f01e4/2020-10-09T10:11:53Z/-1/host/786789f3445f498c6a1fd4d9cd3897ac7233700df0c6ae2fd78079eba89bf3fb
tar xf profile.tar && cd profile
python resnet.py --model_file ResNet50_inference/model --params_file ResNet50_inference/params
# 正确输出应为:[0.0002414 0.00022418 0.00053661 0.00028639 0.00072682 0.000213
# 0.00638718 0.00128127 0.00013535 0.0007676 ]
python mobilenetv1.py --model_file mobilenetv1/model --params_file mobilenetv1/params
# 正确输出应为:[0.00123949 0.00100392 0.00109539 0.00112206 0.00101901 0.00088412
# 0.00121536 0.00107679 0.00106071 0.00099605]
python ernie.py --model_dir ernieL3H128_model/
# 正确输出应为:[0.49879393 0.5012061 ]
如何卸载¶
请使用以下命令卸载PaddlePaddle:
python3 -m pip uninstall paddlepaddle` 或 `python3 -m pip uninstall paddlepaddle
备注¶
已在ZHAOXIN下测试过resnet50, mobilenetv1, ernie, ELMo等模型,基本保证了预测使用算子的正确性,如果您在使用过程中遇到计算结果错误,编译失败等问题,请到issue中留言,我们会及时解决。
预测文档见doc,使用示例见Paddle-Inference-Demo
下载安装Linux预测库¶
| 版本说明 | 预测库(1.8.5版本) | 预测库(2.0.0-rc0版本) | 预测库(develop版本) |
|---|---|---|---|
| manylinux_cpu_avx_mkl_gcc482 | fluid_inference.tgz | paddle_inference.tgz | paddle_inference.tgz |
| manylinux_cpu_avx_openblas_gcc482 | fluid_inference.tgz | paddle_inference.tgz | |
| manylinux_cpu_noavx_openblas_gcc482 | fluid_inference.tgz | paddle_inference.tgz | |
| manylinux_cuda9.0_cudnn7_avx_mkl_gcc482 | fluid_inference.tgz | paddle_inference.tgz | paddle_inference.tgz |
| manylinux_cuda10.0_cudnn7_avx_mkl_gcc482 | fluid_inference.tgz | paddle_inference.tgz | paddle_inference.tgz |
| manylinux_cuda10.1_cudnn7.6_avx_mkl_trt6_gcc482 | fluid_inference.tgz | ||
| manylinux_cuda10.1_cudnn7.6_avx_mkl_trt6_gcc82 | paddle_inference.tgz | ||
| manylinux_cuda10.2_cudnn8.0_avx_mkl_trt7_gcc82 | paddle_inference.tgz | ||
| nv_jetson_cuda10_cudnn7.5_trt5(jetpack4.2) | fluid_inference.tgz | ||
| nv_jetson_cuda10_cudnn7.6_trt6(jetpack4.3) | paddle_inference.tgz |
下载安装Windows预测库¶
| 版本说明 | 预测库(1.8.4版本) | 预测库(2.0.0-beta0版本) | 编译器 | 构建工具 | cuDNN | CUDA |
|---|---|---|---|---|---|---|
| cpu_avx_mkl | fluid_inference.zip | fluid_inference.zip | MSVC 2015 update 3 | CMake v3.16.0 | ||
| cpu_avx_openblas | fluid_inference.zip | MSVC 2015 update 3 | CMake v3.16.0 | |||
| cuda9.0_cudnn7_avx_mkl | fluid_inference.zip | MSVC 2015 update 3 | CMake v3.16.0 | 7.3.1 | 9.0 | |
| cuda9.0_cudnn7_avx_openblas | fluid_inference.zip | MSVC 2015 update 3 | CMake v3.16.0 | 7.3.1 | 9.0 | |
| cuda10.0_cudnn7_avx_mkl | fluid_inference.zip | fluid_inference.zip | MSVC 2015 update 3 | CMake v3.16.0 | 7.4.1 | 10.0 |
环境硬件配置:
| 操作系统 | win10 家庭版本 |
|---|---|
| CPU | I7-8700K |
| 内存 | 16G |
| 硬盘 | 1T hdd + 256G ssd |
| 显卡 | GTX1080 8G |
使用Paddle-TensorRT库预测¶
NVIDIA TensorRT 是一个高性能的深度学习预测库,可为深度学习推理应用程序提供低延迟和高吞吐量。PaddlePaddle 采用子图的形式对TensorRT进行了集成,即我们可以使用该模块来提升Paddle模型的预测性能。在这篇文章中,我们会介绍如何使用Paddle-TRT子图加速预测。
如果您需要安装[TensorRT](https://developer.nvidia.com/nvidia-tensorrt-6x-download),请参考[trt文档](https://docs.nvidia.com/deeplearning/tensorrt/archives/tensorrt-601/tensorrt-install-guide/index.html).
概述¶
当模型加载后,神经网络可以表示为由变量和运算节点组成的计算图。如果我们打开TRT子图模式,在图分析阶段,Paddle会对模型图进行分析同时发现图中可以使用TensorRT优化的子图,并使用TensorRT节点替换它们。在模型的推断期间,如果遇到TensorRT节点,Paddle会调用TensorRT库对该节点进行优化,其他的节点调用Paddle的原生实现。TensorRT除了有常见的OP融合以及显存/内存优化外,还针对性的对OP进行了优化加速实现,降低预测延迟,提升推理吞吐。
目前Paddle-TRT支持静态shape模式以及/动态shape模式。在静态shape模式下支持图像分类,分割,检测模型,同时也支持Fp16, Int8的预测加速。在动态shape模式下,除了对动态shape的图像模型(FCN, Faster rcnn)支持外,同时也对NLP的Bert/Ernie模型也进行了支持。
Paddle-TRT的现有能力:
1)静态shape:
支持模型:
分类模型 |
检测模型 |
分割模型 |
|---|---|---|
Mobilenetv1 |
yolov3 |
ICNET |
Resnet50 |
SSD |
UNet |
Vgg16 |
Mask-rcnn |
FCN |
Resnext |
Faster-rcnn |
|
AlexNet |
Cascade-rcnn |
|
Se-ResNext |
Retinanet |
|
GoogLeNet |
Mobilenet-SSD |
|
DPN |
Fp16:
Calib Int8:
优化信息序列化:
加载PaddleSlim Int8模型:
2)动态shape:
支持模型:
图像 |
NLP |
|---|---|
FCN |
Bert |
Faster_RCNN |
Ernie |
Fp16:
Calib Int8:
优化信息序列化:
加载PaddleSlim Int8模型:
Note:
从源码编译时,TensorRT预测库目前仅支持使用GPU编译,且需要设置编译选项TENSORRT_ROOT为TensorRT所在的路径。
Windows支持需要TensorRT 版本5.0以上。
使用Paddle-TRT的动态shape输入功能要求TRT的版本在6.0以上。
一:环境准备¶
使用Paddle-TRT功能,我们需要准备带TRT的Paddle运行环境,我们提供了以下几种方式:
1)linux下通过pip安装
# 该whl包依赖cuda10.1, cudnnv7.6, tensorrt6.0 的lib, 需自行下载安装并设置lib路径到LD_LIBRARY_PATH中
wget https://paddle-inference-dist.bj.bcebos.com/libs/paddlepaddle_gpu-1.8.0-cp27-cp27mu-linux_x86_64.whl
pip install -U paddlepaddle_gpu-1.8.0-cp27-cp27mu-linux_x86_64.whl
如果您想在Nvidia Jetson平台上使用,请点击此 链接 下载whl包,然后通过pip 安装。
2)使用docker镜像
# 拉取镜像,该镜像预装Paddle 1.8 Python环境,并包含c++的预编译库,lib存放在主目录~/ 下。
docker pull hub.baidubce.com/paddlepaddle/paddle:1.8.0-gpu-cuda10.0-cudnn7-trt6
export CUDA_SO="$(\ls /usr/lib64/libcuda* | xargs -I{} echo '-v {}:{}') $(\ls /usr/lib64/libnvidia* | xargs -I{} echo '-v {}:{}')"
export DEVICES=$(\ls /dev/nvidia* | xargs -I{} echo '--device {}:{}')
export NVIDIA_SMI="-v /usr/bin/nvidia-smi:/usr/bin/nvidia-smi"
docker run $CUDA_SO $DEVICES $NVIDIA_SMI --name trt_open --privileged --security-opt seccomp=unconfined --net=host -v $PWD:/paddle -it hub.baidubce.com/paddlepaddle/paddle:1.8.0-gpu-cuda10.0-cudnn7-trt6 /bin/bash
3)手动编译 编译的方式请参照 编译文档
Note1: cmake 期间请设置 TENSORRT_ROOT (即TRT lib的路径), WITH_PYTHON (是否产出python whl包, 设置为ON)选项。
Note2: 编译期间会出现TensorRT相关的错误。
需要手动在 NvInfer.h (trt5) 或 NvInferRuntime.h (trt6) 文件中为 class IPluginFactory 和 class IGpuAllocator 分别添加虚析构函数:
virtual ~IPluginFactory() {};
virtual ~IGpuAllocator() {};
需要将 NvInferRuntime.h (trt6)中的 protected: ~IOptimizationProfile() noexcept = default;
改为
virtual ~IOptimizationProfile() noexcept = default;
二:API使用介绍¶
在 使用流程 一节中,我们了解到Paddle Inference预测包含了以下几个方面:
配置推理选项
创建predictor
准备模型输入
模型推理
获取模型输出
使用Paddle-TRT 也是遵照这样的流程。我们先用一个简单的例子来介绍这一流程(我们假设您已经对Paddle Inference有一定的了解,如果您刚接触Paddle Inference,请访问 这里 对Paddle Inference有个初步认识。):
import numpy as np
from paddle.fluid.core import AnalysisConfig
from paddle.fluid.core import create_paddle_predictor
def create_predictor():
# config = AnalysisConfig("")
config = AnalysisConfig("./resnet50/model", "./resnet50/params")
config.switch_use_feed_fetch_ops(False)
config.enable_memory_optim()
config.enable_use_gpu(1000, 0)
# 打开TensorRT。此接口的详细介绍请见下文
config.enable_tensorrt_engine(workspace_size = 1<<30,
max_batch_size=1, min_subgraph_size=5,
precision_mode=AnalysisConfig.Precision.Float32,
use_static=False, use_calib_mode=False)
predictor = create_paddle_predictor(config)
return predictor
def run(predictor, img):
# 准备输入
input_names = predictor.get_input_names()
for i, name in enumerate(input_names):
input_tensor = predictor.get_input_tensor(name)
input_tensor.reshape(img[i].shape)
input_tensor.copy_from_cpu(img[i].copy())
# 预测
predictor.zero_copy_run()
results = []
# 获取输出
output_names = predictor.get_output_names()
for i, name in enumerate(output_names):
output_tensor = predictor.get_output_tensor(name)
output_data = output_tensor.copy_to_cpu()
results.append(output_data)
return results
if __name__ == '__main__':
pred = create_predictor()
img = np.ones((1, 3, 224, 224)).astype(np.float32)
result = run(pred, [img])
print ("class index: ", np.argmax(result[0][0]))
通过例子我们可以看出,我们通过 enable_tensorrt_engine 接口来打开TensorRT选项的。
config.enable_tensorrt_engine(
workspace_size = 1<<30,
max_batch_size=1, min_subgraph_size=5,
precision_mode=AnalysisConfig.Precision.Float32,
use_static=False, use_calib_mode=False)
接下来让我们看下该接口中各个参数的作用:
workspace_size,类型:int,默认值为1 << 30 (1G)。指定TensorRT使用的工作空间大小,TensorRT会在该大小限制下筛选最优的kernel执行预测运算。
max_batch_size,类型:int,默认值为1。需要提前设置最大的batch大小,运行时batch大小不得超过此限定值。
min_subgraph_size,类型:int,默认值为3。Paddle-TRT是以子图的形式运行,为了避免性能损失,当子图内部节点个数大于 min_subgraph_size 的时候,才会使用Paddle-TRT运行。
precision_mode,类型:AnalysisConfig.Precision, 默认值为 AnalysisConfig.Precision.Float32。指定使用TRT的精度,支持FP32(Float32),FP16(Half),Int8(Int8)。若需要使用Paddle-TRT int8离线量化校准,需设定precision为 AnalysisConfig.Precision.Int8 , 且设置 use_calib_mode 为True。
use_static,类型:bool, 默认值为False。如果指定为True,在初次运行程序的时候会将TRT的优化信息进行序列化到磁盘上,下次运行时直接加载优化的序列化信息而不需要重新生成。
use_calib_mode,类型:bool, 默认值为False。若要运行Paddle-TRT int8离线量化校准,需要将此选项设置为True。
Int8量化预测¶
神经网络的参数在一定程度上是冗余的,在很多任务上,我们可以在保证模型精度的前提下,将Float32的模型转换成Int8的模型,从而达到减小计算量降低运算耗时、降低计算内存、降低模型大小的目的。使用Int8量化预测的流程可以分为两步:1)产出量化模型;2)加载量化模型进行Int8预测。下面我们对使用Paddle-TRT进行Int8量化预测的完整流程进行详细介绍。
1. 产出量化模型
目前,我们支持通过两种方式产出量化模型:
使用TensorRT自带Int8离线量化校准功能。校准即基于训练好的FP32模型和少量校准数据(如500~1000张图片)生成校准表(Calibration table),预测时,加载FP32模型和此校准表即可使用Int8精度预测。生成校准表的方法如下:
指定TensorRT配置时,将 precision_mode 设置为 AnalysisConfig.Precision.Int8 并且设置 use_calib_mode 为 True。
config.enable_tensorrt_engine( workspace_size=1<<30, max_batch_size=1, min_subgraph_size=5, precision_mode=AnalysisConfig.Precision.Int8, use_static=False, use_calib_mode=True)准备500张左右的真实输入数据,在上述配置下,运行模型。(Paddle-TRT会统计模型中每个tensor值的范围信息,并将其记录到校准表中,运行结束后,会将校准表写入模型目录下的 _opt_cache 目录中)
如果想要了解使用TensorRT自带Int8离线量化校准功能生成校准表的完整代码,请参考 这里 的demo。
使用模型压缩工具库PaddleSlim产出量化模型。PaddleSlim支持离线量化和在线量化功能,其中,离线量化与TensorRT离线量化校准原理相似;在线量化又称量化训练(Quantization Aware Training, QAT),是基于较多数据(如>=5000张图片)对预训练模型进行重新训练,使用模拟量化的思想,在训练阶段更新权重,实现减小量化误差的方法。使用PaddleSlim产出量化模型可以参考文档:
离线量化的优点是无需重新训练,简单易用,但量化后精度可能受影响;量化训练的优点是模型精度受量化影响较小,但需要重新训练模型,使用门槛稍高。在实际使用中,我们推荐先使用TRT离线量化校准功能生成量化模型,若精度不能满足需求,再使用PaddleSlim产出量化模型。
2. 加载量化模型进行Int8预测
加载量化模型进行Int8预测,需要在指定TensorRT配置时,将 precision_mode 设置为 AnalysisConfig.Precision.Int8 。
若使用的量化模型为TRT离线量化校准产出的,需要将 use_calib_mode 设为 True :
config.enable_tensorrt_engine( workspace_size=1<<30, max_batch_size=1, min_subgraph_size=5, precision_mode=AnalysisConfig.Precision.Int8, use_static=False, use_calib_mode=True)完整demo请参考 这里 。
若使用的量化模型为PaddleSlim量化产出的,需要将 use_calib_mode 设为 False :
config.enable_tensorrt_engine( workspace_size=1<<30, max_batch_size=1, min_subgraph_size=5, precision_mode=AnalysisConfig.Precision.Int8, use_static=False, use_calib_mode=False)完整demo请参考 这里 。
运行Dynamic shape¶
从1.8 版本开始, Paddle对TRT子图进行了Dynamic shape的支持。 使用接口如下:
config.enable_tensorrt_engine(
workspace_size = 1<<30,
max_batch_size=1, min_subgraph_size=5,
precision_mode=AnalysisConfig.Precision.Float32,
use_static=False, use_calib_mode=False)
min_input_shape = {"image":[1,3, 10, 10]}
max_input_shape = {"image":[1,3, 224, 224]}
opt_input_shape = {"image":[1,3, 100, 100]}
config.set_trt_dynamic_shape_info(min_input_shape, max_input_shape, opt_input_shape)
从上述使用方式来看,在 config.enable_tensorrt_engine 接口的基础上,新加了一个config.set_trt_dynamic_shape_info 的接口。
该接口用来设置模型输入的最小,最大,以及最优的输入shape。 其中,最优的shape处于最小最大shape之间,在预测初始化期间,会根据opt shape对op选择最优的kernel。
调用了 config.set_trt_dynamic_shape_info 接口,预测器会运行TRT子图的动态输入模式,运行期间可以接受最小,最大shape间的任意的shape的输入数据。
四:Paddle-TRT子图运行原理¶
PaddlePaddle采用子图的形式对TensorRT进行集成,当模型加载后,神经网络可以表示为由变量和运算节点组成的计算图。Paddle TensorRT实现的功能是对整个图进行扫描,发现图中可以使用TensorRT优化的子图,并使用TensorRT节点替换它们。在模型的推断期间,如果遇到TensorRT节点,Paddle会调用TensorRT库对该节点进行优化,其他的节点调用Paddle的原生实现。TensorRT在推断期间能够进行Op的横向和纵向融合,过滤掉冗余的Op,并对特定平台下的特定的Op选择合适的kernel等进行优化,能够加快模型的预测速度。
下图使用一个简单的模型展示了这个过程:
原始网络
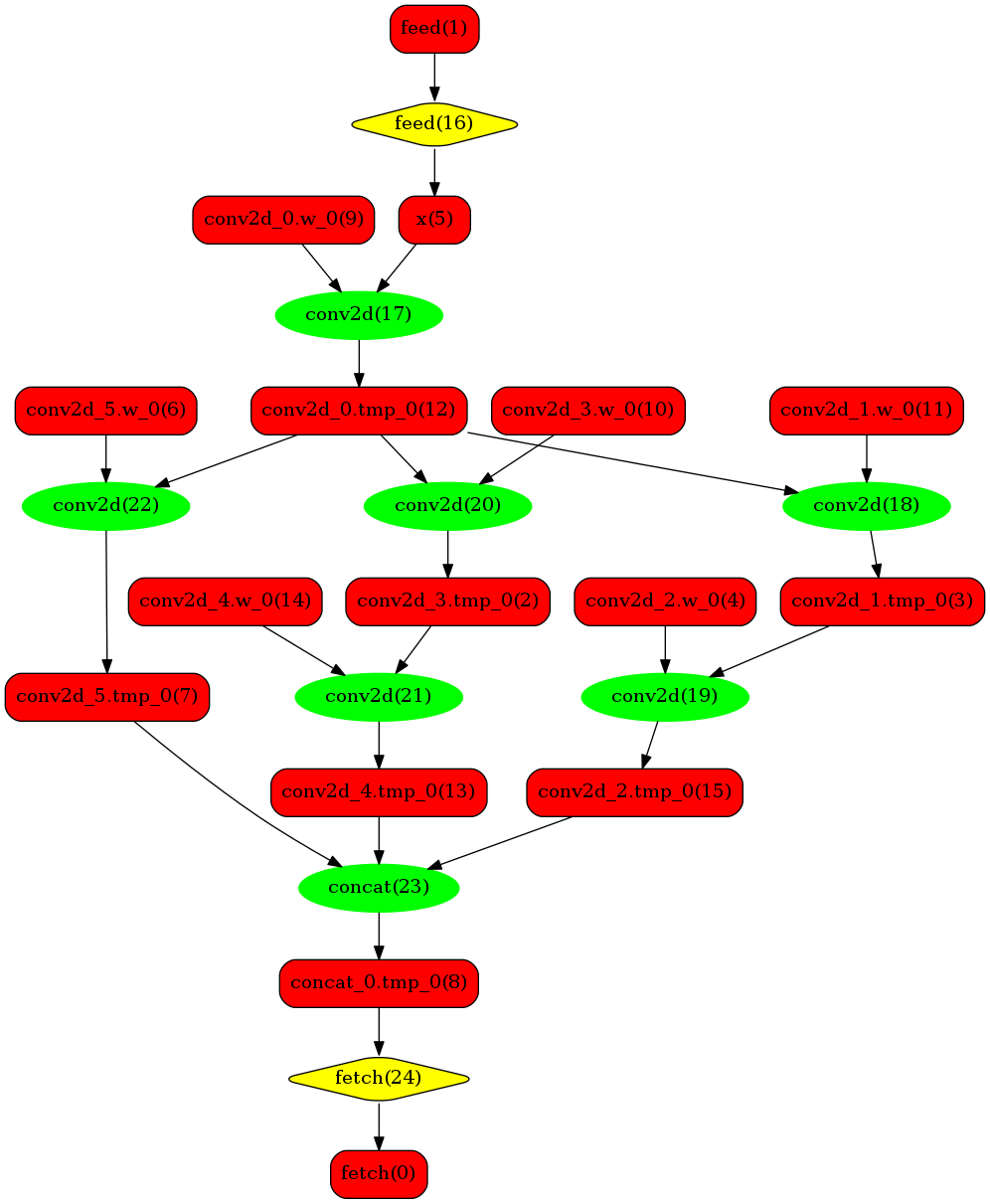
转换的网络
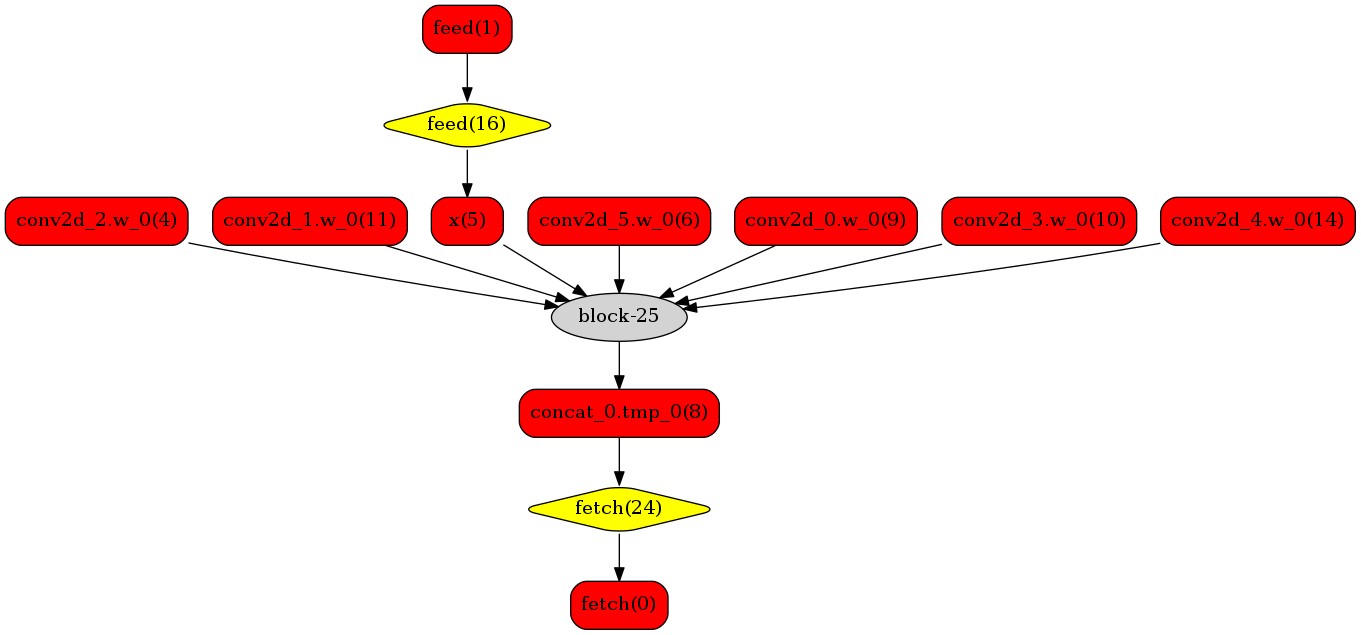
我们可以在原始模型网络中看到,绿色节点表示可以被TensorRT支持的节点,红色节点表示网络中的变量,黄色表示Paddle只能被Paddle原生实现执行的节点。那些在原始网络中的绿色节点被提取出来汇集成子图,并由一个TensorRT节点代替,成为转换后网络中的 block-25 节点。在网络运行过程中,如果遇到该节点,Paddle将调用TensorRT库来对其执行。
模型可视化¶
通过 Quick Start 一节中,我们了解到,预测模型包含了两个文件,一部分为模型结构文件,通常以 model 或 __model__ 文件存在;另一部分为参数文件,通常以params 文件或一堆分散的文件存在。
模型结构文件,顾名思义,存储了模型的拓扑结构,其中包括模型中各种OP的计算顺序以及OP的详细信息。很多时候,我们希望能够将这些模型的结构以及内部信息可视化,方便我们进行模型分析。接下来将会通过两种方式来讲述如何对Paddle 预测模型进行可视化。
一: 通过 VisualDL 可视化¶
1) 安装
VisualDL是飞桨可视化分析工具,以丰富的图表呈现训练参数变化趋势、模型结构、数据样本、高维数据分布等,帮助用户更清晰直观地理解深度学习模型训练过程及模型结构,实现高效的模型优化。 我们可以进入 GitHub主页 进行下载安装。
2)可视化
点击 下载测试模型。
支持两种启动方式:
前端拖拽上传模型文件:
无需添加任何参数,在命令行执行 visualdl 后启动界面上传文件即可:

后端透传模型文件:
在命令行加入参数 –model 并指定 模型文件 路径(非文件夹路径),即可启动:
visualdl --model ./log/model --port 8080

Graph功能详细使用,请见 Graph使用指南 。
二: 通过代码方式生成dot文件¶
1)pip 安装Paddle
2)生成dot文件
点击 下载测试模型。
#!/usr/bin/env python
import paddle.fluid as fluid
from paddle.fluid import core
from paddle.fluid.framework import IrGraph
def get_graph(program_path):
with open(program_path, 'rb') as f:
binary_str = f.read()
program = fluid.framework.Program.parse_from_string(binary_str)
return IrGraph(core.Graph(program.desc), for_test=True)
if __name__ == '__main__':
program_path = './lecture_model/__model__'
offline_graph = get_graph(program_path)
offline_graph.draw('.', 'test_model', [])
3)生成svg
Note:需要环境中安装graphviz
dot -Tsvg ./test_mode.dot -o test_model.svg
然后将test_model.svg以浏览器打开预览即可。

模型转换工具 X2Paddle¶
X2Paddle可以将caffe、tensorflow、onnx模型转换成Paddle支持的模型。
X2Paddle 支持将Caffe/TensorFlow模型转换为PaddlePaddle模型。目前X2Paddle支持的模型参考 x2paddle_model_zoo 。
多框架支持¶
模型 |
caffe |
tensorflow |
onnx |
|---|---|---|---|
mobilenetv1 |
Y |
Y |
F |
mobilenetv2 |
Y |
Y |
Y |
resnet18 |
Y |
Y |
F |
resnet50 |
Y |
Y |
Y |
mnasnet |
Y |
Y |
F |
efficientnet |
Y |
Y |
Y |
squeezenetv1.1 |
Y |
Y |
Y |
shufflenet |
Y |
Y |
F |
mobilenet_ssd |
Y |
Y |
F |
mobilenet_yolov3 |
F |
Y |
F |
inceptionv4 |
F |
F |
F |
mtcnn |
Y |
Y |
F |
facedetection |
Y |
F |
F |
unet |
Y |
Y |
F |
ocr_attention |
F |
F |
F |
vgg16 |
F |
F |
F |
安装¶
pip install x2paddle
安装最新版本,可使用如下安装方式
pip install git+https://github.com/PaddlePaddle/X2Paddle.git@develop
使用¶
Caffe¶
x2paddle --framework caffe \
--prototxt model.proto \
--weight model.caffemodel \
--save_dir paddle_model
TensorFlow¶
x2paddle --framework tensorflow \
--model model.pb \
--save_dir paddle_model
转换结果说明¶
在指定的 save_dir 下生成两个目录
inference_model : 模型结构和参数均序列化保存的模型格式
model_with_code : 保存了模型参数文件和模型的python代码
问题反馈
X2Paddle使用时存在问题时,欢迎您将问题或Bug报告以 Github Issues 的形式提交给我们,我们会实时跟进。
X86 Linux上预测部署示例¶
1 C++预测部署示例¶
C++示例代码在链接,下面从流程解析和编译运行示例两方面介绍。
1.1 流程解析¶
1.1.2 准备预测模型¶
使用Paddle训练结束后,得到预测模型,可以用于预测部署。
本示例准备了mobilenet_v1预测模型,可以从链接下载,或者wget下载。
wget https://paddle-inference-dist.cdn.bcebos.com/PaddleInference/mobilenetv1_fp32.tar.gz
1.1.3 包含头文件¶
使用Paddle预测库,只需要包含 paddle_inference_api.h 头文件。
#include "paddle/include/paddle_inference_api.h"
1.1.4 设置Config¶
根据预测部署的实际情况,设置Config,用于后续创建Predictor。
Config默认是使用CPU预测,可以设置开启MKLDNN加速、设置CPU的线程数、开启IR优化、开启内存优化。
paddle_infer::Config config;
if (FLAGS_model_dir == "") {
config.SetModel(FLAGS_model_file, FLAGS_params_file); // Load combined model
} else {
config.SetModel(FLAGS_model_dir); // Load no-combined model
}
config.EnableMKLDNN();
config.SetCpuMathLibraryNumThreads(FLAGS_threads);
config.SwitchIrOptim();
config.EnableMemoryOptim();
1.1.5 创建Predictor¶
std::shared_ptr<paddle_infer::Predictor> predictor = paddle_infer::CreatePredictor(config);
1.1.6 设置输入¶
从Predictor中获取输入的names和handle,然后设置输入数据。
auto input_names = predictor->GetInputNames();
auto input_t = predictor->GetInputHandle(input_names[0]);
std::vector<int> input_shape = {1, 3, 224, 224};
std::vector<float> input_data(1 * 3 * 224 * 224, 1);
input_t->Reshape(input_shape);
input_t->CopyFromCpu(input_data.data());
1.1.7 执行Predictor¶
predictor->Run();
1.1.8 获取输出¶
auto output_names = predictor->GetOutputNames();
auto output_t = predictor->GetOutputHandle(output_names[0]);
std::vector<int> output_shape = output_t->shape();
int out_num = std::accumulate(output_shape.begin(), output_shape.end(), 1,
std::multiplies<int>());
std::vector<float> out_data;
out_data.resize(out_num);
output_t->CopyToCpu(out_data.data());
1.2 编译运行示例¶
1.2.1 编译示例¶
文件model_test.cc 为预测的样例程序(程序中的输入为固定值,如果您有opencv或其他方式进行数据读取的需求,需要对程序进行一定的修改)。文件CMakeLists.txt 为编译构建文件。脚本run_impl.sh 包含了第三方库、预编译库的信息配置。
根据前面步骤下载Paddle预测库和mobilenetv1模型。
打开 run_impl.sh 文件,设置 LIB_DIR 为下载的预测库路径,比如 LIB_DIR=/work/Paddle/build/paddle_inference_install_dir。
运行 sh run_impl.sh, 会在当前目录下编译产生build目录。
1.2.2 运行示例¶
进入build目录,运行样例。
cd build
./model_test --model_dir=mobilenetv1_fp32_dir
运行结束后,程序会将模型结果打印到屏幕,说明运行成功。
2 Python预测部署示例¶
Python预测部署示例代码在链接,下面从流程解析和编译运行示例两方面介绍。
2.1 流程解析¶
2.1.2 准备预测模型¶
使用Paddle训练结束后,得到预测模型,可以用于预测部署。
本示例准备了mobilenet_v1预测模型,可以从链接下载,或者wget下载。
wget https://paddle-inference-dist.cdn.bcebos.com/PaddleInference/mobilenetv1_fp32.tar.gz
tar zxf mobilenetv1_fp32.tar.gz
2.1.3 Python导入¶
from paddle.inference import Config
from paddle.inference import create_predictor
2.1.4 设置Config¶
根据预测部署的实际情况,设置Config,用于后续创建Predictor。
Config默认是使用CPU预测,可以设置开启MKLDNN加速、设置CPU的线程数、开启IR优化、开启内存优化。
# args 是解析的输入参数
if args.model_dir == "":
config = Config(args.model_file, args.params_file)
else:
config = Config(args.model_dir)
config.enable_mkldnn()
config.set_cpu_math_library_num_threads(args.threads)
config.switch_ir_optim()
config.enable_memory_optim()
2.1.5 创建Predictor¶
predictor = create_predictor(config)
2.1.6 设置输入¶
从Predictor中获取输入的names和handle,然后设置输入数据。
img = cv2.imread(args.img_path)
img = preprocess(img)
input_names = predictor.get_input_names()
input_tensor = predictor.get_input_handle(input_names[0])
input_tensor.reshape(img.shape)
input_tensor.copy_from_cpu(img.copy())
2.1.7 执行Predictor¶
predictor.run();
2.1.8 获取输出¶
output_names = predictor.get_output_names()
output_tensor = predictor.get_output_handle(output_names[0])
output_data = output_tensor.copy_to_cpu()
2.2 编译运行示例¶
文件img_preprocess.py是对图像进行预处理。
文件model_test.py是示例程序。
参考前面步骤准备环境、下载预测模型。
下载预测图片。
wget https://paddle-inference-dist.bj.bcebos.com/inference_demo/python/resnet50/ILSVRC2012_val_00000247.jpeg
执行预测命令。
python model_test.py --model_dir mobilenetv1_fp32 --img_path ILSVRC2012_val_00000247.jpeg
运行结束后,程序会将模型结果打印到屏幕,说明运行成功。
X86 Windows上预测部署示例¶
1 C++预测部署示例¶
C++示例代码在链接,下面从流程解析和编译运行示例两方面介绍。
1.1 流程解析¶
1.1.2 准备预测模型¶
使用Paddle训练结束后,得到预测模型,可以用于预测部署。
本示例准备了mobilenet_v1预测模型,可以从链接下载,或者wget下载。
wget https://paddle-inference-dist.cdn.bcebos.com/PaddleInference/mobilenetv1_fp32.tar.gz
1.1.3 包含头文件¶
使用Paddle预测库,只需要包含 paddle_inference_api.h 头文件。
#include "paddle/include/paddle_inference_api.h"
1.1.4 设置Config¶
根据预测部署的实际情况,设置Config,用于后续创建Predictor。
Config默认是使用CPU预测,可以设置开启MKLDNN加速、设置CPU的线程数、开启IR优化、开启内存优化。
paddle_infer::Config config;
if (FLAGS_model_dir == "") {
config.SetModel(FLAGS_model_file, FLAGS_params_file); // Load combined model
} else {
config.SetModel(FLAGS_model_dir); // Load no-combined model
}
config.EnableMKLDNN();
config.SetCpuMathLibraryNumThreads(FLAGS_threads);
config.SwitchIrOptim();
config.EnableMemoryOptim();
1.1.5 创建Predictor¶
std::shared_ptr<paddle_infer::Predictor> predictor = paddle_infer::CreatePredictor(config);
1.1.6 设置输入¶
从Predictor中获取输入的names和handle,然后设置输入数据。
auto input_names = predictor->GetInputNames();
auto input_t = predictor->GetInputHandle(input_names[0]);
std::vector<int> input_shape = {1, 3, 224, 224};
std::vector<float> input_data(1 * 3 * 224 * 224, 1);
input_t->Reshape(input_shape);
input_t->CopyFromCpu(input_data.data());
1.1.7 执行Predictor¶
predictor->Run();
1.1.8 获取输出¶
auto output_names = predictor->GetOutputNames();
auto output_t = predictor->GetOutputHandle(output_names[0]);
std::vector<int> output_shape = output_t->shape();
int out_num = std::accumulate(output_shape.begin(), output_shape.end(), 1,
std::multiplies<int>());
std::vector<float> out_data;
out_data.resize(out_num);
output_t->CopyToCpu(out_data.data());
1.2 编译运行示例¶
1.2.1 编译示例¶
文件model_test.cc 为预测的样例程序(程序中的输入为固定值,如果您有opencv或其他方式进行数据读取的需求,需要对程序进行一定的修改)。文件CMakeLists.txt 为编译构建文件。
根据前面步骤下载Paddle预测库和mobilenetv1模型。
使用cmake-gui程序生成vs工程:
选择源代码路径,及编译产物路径,如图所示
 win_x86_cpu_cmake_1
win_x86_cpu_cmake_1
点击Configure,选择Visual Studio且选择x64版本如图所示,点击Finish,由于我们没有加入必要的CMake Options,会导致configure失败,请继续下一步。
 win_x86_cpu_cmake_2
win_x86_cpu_cmake_2
设置CMake Options,点击Add Entry,新增PADDLE_LIB,CMAKE_BUILD_TYPE,DEMO_NAME等选项。具体配置项如下图所示,其中PADDLE_LIB为您下载的预测库路径。
 win_x86_cpu_cmake_3
win_x86_cpu_cmake_3
点击Configure,log信息显示Configure done代表配置成功,接下来点击Generate生成vs工程,log信息显示Generate done,代表生成成功,最后点击Open Project打开Visual Studio.
设置为Release/x64,编译,编译产物在build/Release目录下。
 win_x86_cpu_vs_1
win_x86_cpu_vs_1
1.2.2 运行示例¶
首先设置model_test工程为启动首选项。
 win_x86_cpu_vs_2
win_x86_cpu_vs_2
配置输入flags,即设置您之前下载的模型路径。点击Debug选项卡的model_test Properities..
 win_x86_cpu_vs_3
win_x86_cpu_vs_3
点击Debug选项卡下的Start Without Debugging选项开始执行程序。
 win_x86_cpu_vs_4
win_x86_cpu_vs_4
2 Python预测部署示例¶
Python预测部署示例代码在链接,下面从流程解析和编译运行示例两方面介绍。
2.1 流程解析¶
2.1.2 准备预测模型¶
使用Paddle训练结束后,得到预测模型,可以用于预测部署。
本示例准备了mobilenet_v1预测模型,可以从链接下载,或者wget下载。
wget https://paddle-inference-dist.cdn.bcebos.com/PaddleInference/mobilenetv1_fp32.tar.gz
tar zxf mobilenetv1_fp32.tar.gz
2.1.3 Python导入¶
from paddle.inference import Config
from paddle.inference import create_predictor
2.1.4 设置Config¶
根据预测部署的实际情况,设置Config,用于后续创建Predictor。
Config默认是使用CPU预测,可以设置开启MKLDNN加速、设置CPU的线程数、开启IR优化、开启内存优化。
# args 是解析的输入参数
if args.model_dir == "":
config = Config(args.model_file, args.params_file)
else:
config = Config(args.model_dir)
config.enable_mkldnn()
config.set_cpu_math_library_num_threads(args.threads)
config.switch_ir_optim()
config.enable_memory_optim()
2.1.5 创建Predictor¶
predictor = create_predictor(config)
2.1.6 设置输入¶
从Predictor中获取输入的names和handle,然后设置输入数据。
img = cv2.imread(args.img_path)
img = preprocess(img)
input_names = predictor.get_input_names()
input_tensor = predictor.get_input_handle(input_names[0])
input_tensor.reshape(img.shape)
input_tensor.copy_from_cpu(img.copy())
2.1.7 执行Predictor¶
predictor.run();
2.1.8 获取输出¶
output_names = predictor.get_output_names()
output_tensor = predictor.get_output_handle(output_names[0])
output_data = output_tensor.copy_to_cpu()
2.2 编译运行示例¶
文件img_preprocess.py是对图像进行预处理。
文件model_test.py是示例程序。
参考前面步骤准备环境、下载预测模型。
下载预测图片。
wget https://paddle-inference-dist.bj.bcebos.com/inference_demo/python/resnet50/ILSVRC2012_val_00000247.jpeg
执行预测命令。
python model_test.py --model_dir mobilenetv1_fp32 --img_path ILSVRC2012_val_00000247.jpeg
运行结束后,程序会将模型结果打印到屏幕,说明运行成功。
使用昆仑预测¶
百度的昆仑芯⽚是⼀款⾼性能的AI SoC芯⽚,⽀持推理和训练。昆仑芯⽚采⽤百度的先进AI架构,⾮常适合常⽤的深度学习和机器学习算法的云端计算需求,并能适配诸如⾃然语⾔处理、⼤规模语⾳识别、⾃动驾驶、⼤规模推荐等多种终端场景的计算需求。
Paddle Inference集成了Paddle-Lite预测引擎在昆仑xpu上进行预测部署。
编译注意事项¶
请确保编译的时候设置了WITH_LITE=ON,且XPU_SDK_ROOT设置了正确的路径。
使用介绍¶
在使用Predictor时,我们通过配置Config中的接口,在XPU上运行。
config->EnableLiteEngine(
precision_mode=PrecisionType::kFloat32,
zero_copy=false,
passes_filter={},
ops_filter={},
)
precision_mode,类型:enum class PrecisionType {kFloat32 = 0, kHalf, kInt8,};, 默认值为PrecisionType::kFloat32。指定lite子图的运行精度。zero_copy,类型:bool,lite子图与Paddle之间的数据传递是否是零拷贝模式。passes_filter,类型:std::vector<std::string>,默认为空,扩展借口,暂不使用。ops_filer,类型:std::vector<std::string>,默认为空,显示指定哪些op不使用lite子图运行。
Python接口如下:
config.enable_lite_engine(
precision_mode=PrecisionType.Float32,
zero_copy=False,
passes_filter=[],
ops_filter=[]
)
Python demo¶
因目前Paddle-Inference目前未将xpu sdk打包到whl包内,所以需要用户下载xpu sdk,并加入到环境变量中,之后会考虑解决该问题。
下载xpu_tool_chain,解压后将shlib加入到LD_LIBRARY_PATH
tar xzf xpu_tool_chain.tgz
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$PWD/output/XTDK/shlib/:$PWD/output/XTDK/runtime/shlib/
下载resnet50模型,并解压,运行如下命令将会调用预测引擎
python resnet50_subgraph.py --model_file ./ResNet50/model --params_file ./ResNet50/params
resnet50_subgraph.py的内容是:
import argparse
import time
import numpy as np
from paddle.inference import Config, PrecisionType
from paddle.inference import create_predictor
def main():
args = parse_args()
config = set_config(args)
predictor = create_predictor(config)
input_names = predictor.get_input_names()
input_hanlde = predictor.get_input_handle(input_names[0])
fake_input = np.ones((args.batch_size, 3, 224, 224)).astype("float32")
input_hanlde.reshape([args.batch_size, 3, 224, 224])
input_hanlde.copy_from_cpu(fake_input)
for i in range(args.warmup):
predictor.run()
start_time = time.time()
for i in range(args.repeats):
predictor.run()
output_names = predictor.get_output_names()
output_handle = predictor.get_output_handle(output_names[0])
output_data = output_handle.copy_to_cpu()
end_time = time.time()
print(output_data[0, :10])
print('time is: {}'.format((end_time-start_time)/args.repeats * 1000))
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument("--model_dir", type=str, help="model dir")
parser.add_argument("--model_file", type=str, help="model filename")
parser.add_argument("--params_file", type=str, help="parameter filename")
parser.add_argument("--batch_size", type=int, default=1, help="batch size")
parser.add_argument("--warmup", type=int, default=0, help="warmup")
parser.add_argument("--repeats", type=int, default=1, help="repeats")
parser.add_argument("--math_thread_num", type=int, default=1, help="math_thread_num")
return parser.parse_args()
def set_config(args):
config = Config(args.model_file, args.params_file)
config.enable_lite_engine(PrecisionType.Float32, True)
# use lite xpu subgraph
config.enable_xpu(10 * 1024 * 1024)
# use lite cuda subgraph
# config.enable_use_gpu(100, 0)
config.set_cpu_math_library_num_threads(args.math_thread_num)
return config
if __name__ == "__main__":
main()
GPU上预测部署示例¶
1 C++预测部署示例¶
C++示例代码在链接,下面从流程解析和编译运行示例两方面介绍。
1.1 流程解析¶
1.1.2 准备预测模型¶
使用Paddle训练结束后,得到预测模型,可以用于预测部署。
本示例准备了mobilenet_v1预测模型,可以从链接下载,或者wget下载。
wget https://paddle-inference-dist.cdn.bcebos.com/PaddleInference/mobilenetv1_fp32.tar.gz
1.1.3 包含头文件¶
使用Paddle预测库,只需要包含 paddle_inference_api.h 头文件。
#include "paddle/include/paddle_inference_api.h"
1.1.4 设置Config¶
根据预测部署的实际情况,设置Config,用于后续创建Predictor。
Config默认是使用CPU预测,若要使用GPU预测,需要手动开启,设置运行的GPU卡号和分配的初始显存。可以设置开启TensorRT加速、开启IR优化、开启内存优化。使用Paddle-TensorRT相关说明和示例可以参考文档。
paddle_infer::Config config;
if (FLAGS_model_dir == "") {
config.SetModel(FLAGS_model_file, FLAGS_params_file); // Load combined model
} else {
config.SetModel(FLAGS_model_dir); // Load no-combined model
}
config.EnableUseGpu(500, 0);
config.SwitchIrOptim(true);
config.EnableMemoryOptim();
config.EnableTensorRtEngine(1 << 30, FLAGS_batch_size, 10, PrecisionType::kFloat32, false, false);
1.1.5 创建Predictor¶
std::shared_ptr<paddle_infer::Predictor> predictor = paddle_infer::CreatePredictor(config);
1.1.6 设置输入¶
从Predictor中获取输入的names和handle,然后设置输入数据。
auto input_names = predictor->GetInputNames();
auto input_t = predictor->GetInputHandle(input_names[0]);
std::vector<int> input_shape = {1, 3, 224, 224};
std::vector<float> input_data(1 * 3 * 224 * 224, 1);
input_t->Reshape(input_shape);
input_t->CopyFromCpu(input_data.data());
1.1.7 执行Predictor¶
predictor->Run();
1.1.8 获取输出¶
auto output_names = predictor->GetOutputNames();
auto output_t = predictor->GetOutputHandle(output_names[0]);
std::vector<int> output_shape = output_t->shape();
int out_num = std::accumulate(output_shape.begin(), output_shape.end(), 1,
std::multiplies<int>());
std::vector<float> out_data;
out_data.resize(out_num);
output_t->CopyToCpu(out_data.data());
1.2 编译运行示例¶
1.2.1 编译示例¶
文件model_test.cc 为预测的样例程序(程序中的输入为固定值,如果您有opencv或其他方式进行数据读取的需求,需要对程序进行一定的修改)。文件CMakeLists.txt 为编译构建文件。脚本run_impl.sh 包含了第三方库、预编译库的信息配置。
根据前面步骤下载Paddle预测库和mobilenetv1模型。
打开 run_impl.sh 文件,设置 LIB_DIR 为下载的预测库路径,比如 LIB_DIR=/work/Paddle/build/paddle_inference_install_dir。
运行 sh run_impl.sh, 会在当前目录下编译产生build目录。
1.2.2 运行示例¶
进入build目录,运行样例。
cd build
./model_test --model_dir=mobilenetv1_fp32_dir
运行结束后,程序会将模型结果打印到屏幕,说明运行成功。
2 Python预测部署示例¶
Python预测部署示例代码在链接,下面从流程解析和编译运行示例两方面介绍。
2.1 流程解析¶
2.1.2 准备预测模型¶
使用Paddle训练结束后,得到预测模型,可以用于预测部署。
本示例准备了mobilenet_v1预测模型,可以从链接下载,或者wget下载。
wget https://paddle-inference-dist.cdn.bcebos.com/PaddleInference/mobilenetv1_fp32.tar.gz
tar zxf mobilenetv1_fp32.tar.gz
2.1.3 Python导入¶
from paddle.inference import Config
from paddle.inference import create_predictor
2.1.4 设置Config¶
根据预测部署的实际情况,设置Config,用于后续创建Predictor。
Config默认是使用CPU预测,若要使用GPU预测,需要手动开启,设置运行的GPU卡号和分配的初始显存。可以设置开启TensorRT加速、开启IR优化、开启内存优化。使用Paddle-TensorRT相关说明和示例可以参考文档。
# args 是解析的输入参数
if args.model_dir == "":
config = Config(args.model_file, args.params_file)
else:
config = Config(args.model_dir)
config.enable_use_gpu(500, 0)
config.switch_ir_optim()
config.enable_memory_optim()
config.enable_tensorrt_engine(workspace_size=1 << 30, precision_mode=AnalysisConfig.Precision.Float32,max_batch_size=1, min_subgraph_size=5, use_static=False, use_calib_mode=False)
2.1.5 创建Predictor¶
predictor = create_predictor(config)
2.1.6 设置输入¶
从Predictor中获取输入的names和handle,然后设置输入数据。
img = cv2.imread(args.img_path)
img = preprocess(img)
input_names = predictor.get_input_names()
input_tensor = predictor.get_input_handle(input_names[0])
input_tensor.reshape(img.shape)
input_tensor.copy_from_cpu(img.copy())
2.1.7 执行Predictor¶
predictor.run();
2.1.8 获取输出¶
output_names = predictor.get_output_names()
output_tensor = predictor.get_output_handle(output_names[0])
output_data = output_tensor.copy_to_cpu()
2.2 编译运行示例¶
文件img_preprocess.py是对图像进行预处理。
文件model_test.py是示例程序。
参考前面步骤准备环境、下载预测模型。
下载预测图片。
wget https://paddle-inference-dist.bj.bcebos.com/inference_demo/python/resnet50/ILSVRC2012_val_00000247.jpeg
执行预测命令。
python model_test.py --model_dir mobilenetv1_fp32 --img_path ILSVRC2012_val_00000247.jpeg
运行结束后,程序会将模型结果打印到屏幕,说明运行成功。
NV Jetson上预测部署示例¶
1 C++预测部署示例¶
C++示例代码在链接,下面从流程解析和编译运行示例两方面介绍。
1.1 流程解析¶
1.1.2 准备预测模型¶
使用Paddle训练结束后,得到预测模型,可以用于预测部署。
本示例准备了mobilenet_v1预测模型,可以从链接下载,或者wget下载。
wget https://paddle-inference-dist.cdn.bcebos.com/PaddleInference/mobilenetv1_fp32.tar.gz
1.1.3 包含头文件¶
使用Paddle预测库,只需要包含 paddle_inference_api.h 头文件。
#include "paddle/include/paddle_inference_api.h"
1.1.4 设置Config¶
根据预测部署的实际情况,设置Config,用于后续创建Predictor。
Config默认是使用CPU预测,若要使用GPU预测,需要手动开启,设置运行的GPU卡号和分配的初始显存。可以设置开启TensorRT加速、开启IR优化、开启内存优化。使用Paddle-TensorRT相关说明和示例可以参考文档。
paddle_infer::Config config;
if (FLAGS_model_dir == "") {
config.SetModel(FLAGS_model_file, FLAGS_params_file); // Load combined model
} else {
config.SetModel(FLAGS_model_dir); // Load no-combined model
}
config.EnableUseGpu(500, 0);
config.SwitchIrOptim(true);
config.EnableMemoryOptim();
config.EnableTensorRtEngine(1 << 30, FLAGS_batch_size, 10, PrecisionType::kFloat32, false, false);
1.1.5 创建Predictor¶
std::shared_ptr<paddle_infer::Predictor> predictor = paddle_infer::CreatePredictor(config);
1.1.6 设置输入¶
从Predictor中获取输入的names和handle,然后设置输入数据。
auto input_names = predictor->GetInputNames();
auto input_t = predictor->GetInputHandle(input_names[0]);
std::vector<int> input_shape = {1, 3, 224, 224};
std::vector<float> input_data(1 * 3 * 224 * 224, 1);
input_t->Reshape(input_shape);
input_t->CopyFromCpu(input_data.data());
1.1.7 执行Predictor¶
predictor->Run();
1.1.8 获取输出¶
auto output_names = predictor->GetOutputNames();
auto output_t = predictor->GetOutputHandle(output_names[0]);
std::vector<int> output_shape = output_t->shape();
int out_num = std::accumulate(output_shape.begin(), output_shape.end(), 1,
std::multiplies<int>());
std::vector<float> out_data;
out_data.resize(out_num);
output_t->CopyToCpu(out_data.data());
1.2 编译运行示例¶
1.2.1 编译示例¶
文件model_test.cc 为预测的样例程序(程序中的输入为固定值,如果您有opencv或其他方式进行数据读取的需求,需要对程序进行一定的修改)。文件CMakeLists.txt 为编译构建文件。脚本run_impl.sh 包含了第三方库、预编译库的信息配置。
根据前面步骤下载Paddle预测库和mobilenetv1模型。
打开 run_impl.sh 文件,设置 LIB_DIR 为下载的预测库路径,比如 LIB_DIR=/work/Paddle/build/paddle_inference_install_dir。
运行 sh run_impl.sh, 会在当前目录下编译产生build目录。
1.2.2 运行示例¶
进入build目录,运行样例。
cd build
./model_test --model_dir=mobilenetv1_fp32_dir
运行结束后,程序会将模型结果打印到屏幕,说明运行成功。
2 Python预测部署示例¶
Python预测部署示例代码在链接,下面从流程解析和编译运行示例两方面介绍。
2.1 流程解析¶
2.1.2 准备预测模型¶
使用Paddle训练结束后,得到预测模型,可以用于预测部署。
本示例准备了mobilenet_v1预测模型,可以从链接下载,或者wget下载。
wget https://paddle-inference-dist.cdn.bcebos.com/PaddleInference/mobilenetv1_fp32.tar.gz
tar zxf mobilenetv1_fp32.tar.gz
2.1.3 Python导入¶
from paddle.inference import Config
from paddle.inference import create_predictor
2.1.4 设置Config¶
根据预测部署的实际情况,设置Config,用于后续创建Predictor。
Config默认是使用CPU预测,若要使用GPU预测,需要手动开启,设置运行的GPU卡号和分配的初始显存。可以设置开启TensorRT加速、开启IR优化、开启内存优化。使用Paddle-TensorRT相关说明和示例可以参考文档。
# args 是解析的输入参数
if args.model_dir == "":
config = Config(args.model_file, args.params_file)
else:
config = Config(args.model_dir)
config.enable_use_gpu(500, 0)
config.switch_ir_optim()
config.enable_memory_optim()
config.enable_tensorrt_engine(workspace_size=1 << 30, precision_mode=AnalysisConfig.Precision.Float32,max_batch_size=1, min_subgraph_size=5, use_static=False, use_calib_mode=False)
2.1.5 创建Predictor¶
predictor = create_predictor(config)
2.1.6 设置输入¶
从Predictor中获取输入的names和handle,然后设置输入数据。
img = cv2.imread(args.img_path)
img = preprocess(img)
input_names = predictor.get_input_names()
input_tensor = predictor.get_input_handle(input_names[0])
input_tensor.reshape(img.shape)
input_tensor.copy_from_cpu(img.copy())
2.1.7 执行Predictor¶
predictor.run();
2.1.8 获取输出¶
output_names = predictor.get_output_names()
output_tensor = predictor.get_output_handle(output_names[0])
output_data = output_tensor.copy_to_cpu()
2.2 编译运行示例¶
文件img_preprocess.py是对图像进行预处理。
文件model_test.py是示例程序。
参考前面步骤准备环境、下载预测模型。
下载预测图片。
wget https://paddle-inference-dist.bj.bcebos.com/inference_demo/python/resnet50/ILSVRC2012_val_00000247.jpeg
执行预测命令。
python model_test.py --model_dir mobilenetv1_fp32 --img_path ILSVRC2012_val_00000247.jpeg
运行结束后,程序会将模型结果打印到屏幕,说明运行成功。
Windows上GPU预测部署示例¶
1 C++预测部署示例¶
C++示例代码在链接,下面从流程解析和编译运行示例两方面介绍。
1.1 流程解析¶
1.1.2 准备预测模型¶
使用Paddle训练结束后,得到预测模型,可以用于预测部署。
本示例准备了mobilenet_v1预测模型,可以从链接下载,或者wget下载。
wget https://paddle-inference-dist.cdn.bcebos.com/PaddleInference/mobilenetv1_fp32.tar.gz
1.1.3 包含头文件¶
使用Paddle预测库,只需要包含 paddle_inference_api.h 头文件。
#include "paddle/include/paddle_inference_api.h"
1.1.4 设置Config¶
根据预测部署的实际情况,设置Config,用于后续创建Predictor。
Config默认是使用CPU预测,若要使用GPU预测,需要手动开启,设置运行的GPU卡号和分配的初始显存。可以设置开启IR优化、开启内存优化。
paddle_infer::Config config;
if (FLAGS_model_dir == "") {
config.SetModel(FLAGS_model_file, FLAGS_params_file); // Load combined model
} else {
config.SetModel(FLAGS_model_dir); // Load no-combined model
}
config.EnableUseGpu(500, 0);
config.SwitchIrOptim(true);
config.EnableMemoryOptim();
1.1.5 创建Predictor¶
std::shared_ptr<paddle_infer::Predictor> predictor = paddle_infer::CreatePredictor(config);
1.1.6 设置输入¶
从Predictor中获取输入的names和handle,然后设置输入数据。
auto input_names = predictor->GetInputNames();
auto input_t = predictor->GetInputHandle(input_names[0]);
std::vector<int> input_shape = {1, 3, 224, 224};
std::vector<float> input_data(1 * 3 * 224 * 224, 1);
input_t->Reshape(input_shape);
input_t->CopyFromCpu(input_data.data());
1.1.7 执行Predictor¶
predictor->Run();
1.1.8 获取输出¶
auto output_names = predictor->GetOutputNames();
auto output_t = predictor->GetOutputHandle(output_names[0]);
std::vector<int> output_shape = output_t->shape();
int out_num = std::accumulate(output_shape.begin(), output_shape.end(), 1,
std::multiplies<int>());
std::vector<float> out_data;
out_data.resize(out_num);
output_t->CopyToCpu(out_data.data());
1.2 编译运行示例¶
1.2.1 编译示例¶
文件model_test.cc 为预测的样例程序(程序中的输入为固定值,如果您有opencv或其他方式进行数据读取的需求,需要对程序进行一定的修改)。文件CMakeLists.txt 为编译构建文件。
根据前面步骤下载Paddle预测库和mobilenetv1模型。
使用cmake-gui程序生成vs工程:
选择源代码路径,及编译产物路径,如图所示
win_x86_cpu_cmake_1
点击Configure,选择Visual Studio且选择x64版本如图所示,点击Finish,由于我们没有加入必要的CMake Options,会导致configure失败,请继续下一步。
win_x86_cpu_cmake_2
设置CMake Options,点击Add Entry,新增PADDLE_LIB,CMAKE_BUILD_TYPE,DEMO_NAME等选项。具体配置项如下图所示,其中PADDLE_LIB为您下载的预测库路径。
win_x86_cpu_cmake_3
点击Configure,log信息显示Configure done代表配置成功,接下来点击Generate生成vs工程,log信息显示Generate done,代表生成成功,最后点击Open Project打开Visual Studio.
设置为Release/x64,编译,编译产物在build/Release目录下。
win_x86_cpu_vs_1
1.2.2 运行示例¶
首先设置model_test工程为启动首选项。
win_x86_cpu_vs_2
配置输入flags,即设置您之前下载的模型路径。点击Debug选项卡的model_test Properities..
win_x86_cpu_vs_3
点击Debug选项卡下的Start Without Debugging选项开始执行程序。
win_x86_cpu_vs_4
2 Python预测部署示例¶
Python预测部署示例代码在链接,下面从流程解析和编译运行示例两方面介绍。
2.1 流程解析¶
2.1.2 准备预测模型¶
使用Paddle训练结束后,得到预测模型,可以用于预测部署。
本示例准备了mobilenet_v1预测模型,可以从链接下载,或者wget下载。
wget https://paddle-inference-dist.cdn.bcebos.com/PaddleInference/mobilenetv1_fp32.tar.gz
tar zxf mobilenetv1_fp32.tar.gz
2.1.3 Python导入¶
from paddle.inference import Config
from paddle.inference import create_predictor
2.1.4 设置Config¶
根据预测部署的实际情况,设置Config,用于后续创建Predictor。
Config默认是使用CPU预测,若要使用GPU预测,需要手动开启,设置运行的GPU卡号和分配的初始显存。可以设置开启IR优化、开启内存优化。
# args 是解析的输入参数
if args.model_dir == "":
config = Config(args.model_file, args.params_file)
else:
config = Config(args.model_dir)
config.enable_use_gpu(500, 0)
config.switch_ir_optim()
config.enable_memory_optim()
2.1.5 创建Predictor¶
predictor = create_predictor(config)
2.1.6 设置输入¶
从Predictor中获取输入的names和handle,然后设置输入数据。
img = cv2.imread(args.img_path)
img = preprocess(img)
input_names = predictor.get_input_names()
input_tensor = predictor.get_input_handle(input_names[0])
input_tensor.reshape(img.shape)
input_tensor.copy_from_cpu(img.copy())
2.1.7 执行Predictor¶
predictor.run();
2.1.8 获取输出¶
output_names = predictor.get_output_names()
output_tensor = predictor.get_output_handle(output_names[0])
output_data = output_tensor.copy_to_cpu()
2.2 编译运行示例¶
文件img_preprocess.py是对图像进行预处理。
文件model_test.py是示例程序。
参考前面步骤准备环境、下载预测模型。
下载预测图片。
wget https://paddle-inference-dist.bj.bcebos.com/inference_demo/python/resnet50/ILSVRC2012_val_00000247.jpeg
执行预测命令。
python model_test.py --model_dir mobilenetv1_fp32 --img_path ILSVRC2012_val_00000247.jpeg
运行结束后,程序会将模型结果打印到屏幕,说明运行成功。
性能数据¶
测试条件¶
测试模型
Mobilenetv2
Resnet101
Yolov3
Faster-RCNN
Deeplabv3
Unet
Bert/Ernie
…
测试机器
P4
T4
cpu
…
测试说明
测试Paddle版本:release/2.0-rc1
warmup=10, repeats=1000,统计平均时间,单位ms。
数据¶
| model_name | batch_size | num_samples | device | ir_optim | enable_tensorrt | enable_mkldnn | trt_precision | cpu_math_library_num_threads | Average_latency | QPS |
|---|---|---|---|---|---|---|---|---|---|---|
| bert_emb_v1-paddle | 1 | 1000 | P4 | true | true | fp32 | 8.5914 | 116.396 | ||
| bert_emb_v1-paddle | 2 | 1000 | P4 | true | false | 15.3364 | 130.409 | |||
| bert_emb_v1-paddle | 1 | 1000 | P4 | true | false | 8.09328 | 123.559 | |||
| bert_emb_v1-paddle | 4 | 1000 | P4 | true | false | 27.0221 | 148.027 | |||
| bert_emb_v1-paddle | 2 | 1000 | P4 | true | true | fp32 | 14.9749 | 133.556 | ||
| deeplabv3p_xception_769_fp32-paddle | 4 | 1000 | P4 | true | false | 458.679 | 8.7207 | |||
| deeplabv3p_xception_769_fp32-paddle | 4 | 1000 | P4 | true | true | fp32 | 379.832 | 10.531 | ||
| deeplabv3p_xception_769_fp32-paddle | 1 | 1000 | P4 | true | true | fp32 | 96.0014 | 10.4165 | ||
| deeplabv3p_xception_769_fp32-paddle | 2 | 1000 | P4 | true | true | fp32 | 193.826 | 10.3185 | ||
| deeplabv3p_xception_769_fp32-paddle | 1 | 1000 | P4 | true | false | 114.996 | 8.69596 | |||
| deeplabv3p_xception_769_fp32-paddle | 2 | 1000 | P4 | true | false | 227.272 | 8.80004 | |||
| faster_rcnn_r50_1x-paddle | 2 | 1000 | P4 | true | true | fp32 | 162.795 | 12.2854 | ||
| faster_rcnn_r50_1x-paddle | 1 | 1000 | P4 | true | true | fp32 | 141.49 | 7.06762 | ||
| faster_rcnn_r50_1x-paddle | 4 | 1000 | P4 | true | false | 320.018 | 12.4993 | |||
| faster_rcnn_r50_1x-paddle | 2 | 1000 | P4 | true | false | 162.685 | 12.2937 | |||
| faster_rcnn_r50_1x-paddle | 1 | 1000 | P4 | true | false | 140.516 | 7.11662 | |||
| faster_rcnn_r50_1x-paddle | 4 | 1000 | P4 | true | true | fp32 | 318.193 | 12.571 | ||
| mobilenet_ssd-paddle | 1 | 1000 | P4 | true | false | 5.34364 | 187.138 | |||
| mobilenet_ssd-paddle | 4 | 1000 | P4 | true | false | 10.0709 | 397.185 | |||
| mobilenet_ssd-paddle | 2 | 1000 | P4 | true | false | 6.45996 | 309.6 | |||
| mobilenet_v2-paddle | 4 | 1000 | P4 | true | true | fp32 | 3.74114 | 1069.19 | ||
| mobilenet_v2-paddle | 1 | 1000 | P4 | true | true | fp32 | 1.77892 | 562.14 | ||
| mobilenet_v2-paddle | 2 | 1000 | P4 | true | true | fp32 | 2.44298 | 818.673 | ||
| mobilenet_v2-paddle | 4 | 1000 | P4 | true | false | 7.19198 | 556.175 | |||
| mobilenet_v2-paddle | 2 | 1000 | P4 | true | false | 4.53171 | 441.335 | |||
| mobilenet_v2-paddle | 1 | 1000 | P4 | true | false | 3.45571 | 289.376 | |||
| resnet101-paddle | 1 | 1000 | P4 | true | false | 13.1659 | 75.9538 | |||
| resnet101-paddle | 4 | 1000 | P4 | true | false | 21.1129 | 189.457 | |||
| resnet101-paddle | 2 | 1000 | P4 | true | true | fp32 | 11.7751 | 169.849 | ||
| resnet101-paddle | 1 | 1000 | P4 | true | true | fp32 | 7.79821 | 128.234 | ||
| resnet101-paddle | 4 | 1000 | P4 | true | true | fp32 | 18.3 | 218.58 | ||
| resnet101-paddle | 2 | 1000 | P4 | true | false | 15.4095 | 129.79 | |||
| unet-paddle | 4 | 1000 | P4 | true | true | fp32 | 155.15 | 25.7814 | ||
| unet-paddle | 1 | 1000 | P4 | true | true | fp32 | 36.8867 | 27.11 | ||
| unet-paddle | 2 | 1000 | P4 | true | true | fp32 | 75.5283 | 26.4801 | ||
| yolov3_darknet | 1 | 1000 | P4 | true | false | 84.2696 | 11.8667 | |||
| yolov3_darknet | 2 | 1000 | P4 | true | false | 139.273 | 14.3603 | |||
| yolov3_darknet | 4 | 1000 | P4 | true | false | 208.45 | 19.1893 | |||
| yolov3_darknet | 1 | 1000 | P4 | true | true | fp32 | 43.5201 | 22.9779 | ||
| yolov3_darknet | 2 | 1000 | P4 | true | true | fp32 | 86.456 | 23.1331 | ||
| yolov3_darknet | 4 | 1000 | P4 | true | true | fp32 | 170.954 | 23.3981 |
C++ API 文档¶
CreatePredictor 方法¶
API定义如下:
// 根据 Config 构建预测执行对象 Predictor
// 参数: config - 用于构建 Predictor 的配置信息
// 返回: std::shared_ptr<Predictor> - 预测对象的智能指针
std::shared_ptr<Predictor> CreatePredictor(const Config& config);
代码示例:
// 创建 Config
paddle_infer::Config config("../assets/models/mobilenet_v1");
// 根据 Config 创建 Predictor
auto predictor = paddle_infer::CreatePredictor(config);
GetVersion 方法¶
API定义如下:
// 获取 Paddle 版本信息
// 参数: NONE
// 返回: std::string - Paddle 版本信息
std::string GetVersion();
代码示例:
// 获取 Paddle 版本信息
std::string paddle_version = paddle_infer::GetVersion();
Config 类¶
Config 构造函数¶
Config 类为用于配置构建 Predictor 对象的配置信息,如模型路径、是否开启gpu等等。
构造函数定义如下:
// 创建 Config 对象,默认构造函数
Config();
// 创建 Config 对象,输入为其他 Config 对象
Config(const Config& other);
// 创建 Config 对象,输入为非 Combine 模型的文件夹路径
Config(const std::string& model_dir);
// 创建 Config 对象,输入分别为 Combine 模型的模型文件路径和参数文件路径
Config(const std::string& prog_file, const std::string& params_file);
代码示例 (1):默认构造函数,通过API加载预测模型 - 非Combined模型
// 字符串 model_dir 为非 Combine 模型文件夹路径
std::string model_dir = "../assets/models/mobilenet_v1";
// 创建默认 Config 对象
paddle_infer::Config config();
// 通过 API 设置模型文件夹路径
config.SetModel(model_dir);
// 根据 Config 对象创建预测器对象
auto predictor = paddle_infer::CreatePredictor(config);
代码示例 (2):通过构造函数加载预测模型 - 非Combined模型
// 字符串 model_dir 为非 Combine 模型文件夹路径
std::string model_dir = "../assets/models/mobilenet_v1";
// 根据非 Combine 模型的文件夹路径构造 Config 对象
paddle_infer::Config config(model_dir);
// 根据 Config 对象创建预测器对象
auto predictor = paddle_infer::CreatePredictor(config);
代码示例 (3):通过构造函数加载预测模型 - Combined模型
// 字符串 prog_file 为 Combine 模型文件所在路径
std::string prog_file = "../assets/models/mobilenet_v1/__model__";
// 字符串 params_file 为 Combine 模型参数文件所在路径
std::string params_file = "../assets/models/mobilenet_v1/__params__";
// 根据 Combine 模型的模型文件和参数文件构造 Config 对象
paddle_infer::Config config(prog_file, params_file);
// 根据 Config 对象创建预测器对象
auto predictor = paddle_infer::CreatePredictor(config);
设置预测模型¶
从文件中加载预测模型 - 非Combined模型¶
API定义如下:
// 设置模型文件路径,当需要从磁盘加载非 Combined 模型时使用
// 参数:model_dir - 模型文件夹路径
// 返回:None
void SetModel(const std::string& model_dir);
// 获取非combine模型的文件夹路径
// 参数:None
// 返回:string - 模型文件夹路径
const std::string& model_dir();
代码示例:
// 字符串 model_dir 为非 Combined 模型文件夹路径
std::string model_dir = "../assets/models/mobilenet_v1";
// 创建默认 Config 对象
paddle_infer::Config config();
// 通过 API 设置模型文件夹路径
config.SetModel(model_dir);
// 通过 API 获取 config 中的模型路径
std::cout << "Model Path is: " << config.model_dir() << std::endl;
// 根据Config对象创建预测器对象
auto predictor = paddle_infer::CreatePredictor(config);
从文件中加载预测模型 - Combined 模型¶
API定义如下:
// 设置模型文件路径,当需要从磁盘加载 Combined 模型时使用
// 参数:prog_file_path - 模型文件路径
// params_file_path - 参数文件路径
// 返回:None
void SetModel(const std::string& prog_file_path,
const std::string& params_file_path);
// 设置模型文件路径,当需要从磁盘加载 Combined 模型时使用。
// 参数:x - 模型文件路径
// 返回:None
void SetProgFile(const std::string& x);
// 设置参数文件路径,当需要从磁盘加载 Combined 模型时使用
// 参数:x - 参数文件路径
// 返回:None
void SetParamsFile(const std::string& x);
// 获取 Combined 模型的模型文件路径
// 参数:None
// 返回:string - 模型文件路径
const std::string& prog_file();
// 获取 Combined 模型的参数文件路径
// 参数:None
// 返回:string - 参数文件路径
const std::string& params_file();
代码示例:
// 字符串 prog_file 为 Combined 模型的模型文件所在路径
std::string prog_file = "../assets/models/mobilenet_v1/__model__";
// 字符串 params_file 为 Combined 模型的参数文件所在路径
std::string params_file = "../assets/models/mobilenet_v1/__params__";
// 创建默认 Config 对象
paddle_infer::Config config();
// 通过 API 设置模型文件夹路径,
config.SetModel(prog_file, params_file);
// 注意:SetModel API与以下2行代码等同
// config.SetProgFile(prog_file);
// config.SetParamsFile(params_file);
// 通过 API 获取 config 中的模型文件和参数文件路径
std::cout << "Model file path is: " << config.prog_file() << std::endl;
std::cout << "Model param path is: " << config.params_file() << std::endl;
// 根据 Config 对象创建预测器对象
auto predictor = paddle_infer::CreatePredictor(config);
从内存中加载预测模型¶
API定义如下:
// 从内存加载模型
// 参数:prog_buffer - 内存中模型结构数据
// prog_buffer_size - 内存中模型结构数据的大小
// params_buffer - 内存中模型参数数据
// params_buffer_size - 内存中模型参数数据的大小
// 返回:None
void SetModelBuffer(const char* prog_buffer, size_t prog_buffer_size,
const char* params_buffer, size_t params_buffer_size);
// 判断是否从内存中加载模型
// 参数:None
// 返回:bool - 是否从内存中加载模型
bool model_from_memory() const;
代码示例:
// 定义文件读取函数
std::string read_file(std::string filename) {
std::ifstream file(filename);
return std::string((std::istreambuf_iterator<char>(file)),
std::istreambuf_iterator<char>());
}
// 设置模型文件和参数文件所在路径
std::string prog_file = "../assets/models/mobilenet_v1/__model__";
std::string params_file = "../assets/models/mobilenet_v1/__params__";
// 加载模型文件到内存
std::string prog_str = read_file(prog_file);
std::string params_str = read_file(params_file);
// 创建默认 Config 对象
paddle_infer::Config config();
// 从内存中加载模型
config.SetModelBuffer(prog_str.c_str(), prog_str.size(),
params_str.c_str(), params_str.size());
// 通过 API 获取 config 中 model_from_memory 的值
std::cout << "Load model from memory is: " << config.model_from_memory() << std::endl;
// 根据 Confi 对象创建预测器对象
auto predictor = paddle_infer::CreatePredictor(config);
使用 CPU 进行预测¶
注意:
在 CPU 型号允许的情况下,进行预测库下载或编译试尽量使用带 AVX 和 MKL 的版本
可以尝试使用 Intel 的 MKLDNN 进行 CPU 预测加速,默认 CPU 不启用 MKLDNN
在 CPU 可用核心数足够时,可以通过设置
SetCpuMathLibraryNumThreads将线程数调高一些,默认线程数为 1
CPU 设置¶
API定义如下:
// 设置 CPU Blas 库计算线程数
// 参数:cpu_math_library_num_threads - blas库计算线程数
// 返回:None
void SetCpuMathLibraryNumThreads(int cpu_math_library_num_threads);
// 获取 CPU Blas 库计算线程数
// 参数:None
// 返回:int - cpu blas库计算线程数。
int cpu_math_library_num_threads() const;
代码示例:
// 创建默认 Config 对象
paddle_infer::Config config();
// 设置 CPU Blas 库线程数为 10
config.SetCpuMathLibraryNumThreads(10);
// 通过 API 获取 CPU 信息
int num_thread = config.cpu_math_library_num_threads();
std::cout << "CPU blas thread number is: " << num_thread << std::endl; // 10
MKLDNN 设置¶
注意:
启用 MKLDNN 的前提为已经使用 CPU 进行预测,否则启用 MKLDNN 无法生效
启用 MKLDNN BF16 要求 CPU 型号可以支持 AVX512,否则无法启用 MKLDNN BF16
SetMkldnnCacheCapacity请参考 MKLDNN cache设计文档
API定义如下:
// 启用 MKLDNN 进行预测加速
// 参数:None
// 返回:None
void EnableMKLDNN();
// 判断是否启用 MKLDNN
// 参数:None
// 返回:bool - 是否启用 MKLDNN
bool mkldnn_enabled() const;
// 设置 MKLDNN 针对不同输入 shape 的 cache 容量大小
// 参数:int - cache 容量大小
// 返回:None
void SetMkldnnCacheCapacity(int capacity);
// 指定使用 MKLDNN 加速的 OP 列表
// 参数:std::unordered_set<std::string> - 使用 MKLDNN 加速的 OP 列表
// 返回:None
void SetMKLDNNOp(std::unordered_set<std::string> op_list);
// 启用 MKLDNN BFLOAT16
// 参数:None
// 返回:None
void EnableMkldnnBfloat16();
// 判断是否启用 MKLDNN BFLOAT16
// 参数:None
// 返回:bool - 是否启用 MKLDNN BFLOAT16
bool mkldnn_bfloat16_enabled() const;
// 指定使用 MKLDNN BFLOAT16 加速的 OP 列表
// 参数:std::unordered_set<std::string> - 使用 MKLDNN BFLOAT16 加速的 OP 列表
// 返回:None
void SetBfloat16Op(std::unordered_set<std::string> op_list);
代码示例 (1):使用 MKLDNN 进行预测
// 创建 Config 对象
paddle_infer::Config config(FLAGS_infer_model + "/mobilenet");
// 启用 MKLDNN 进行预测
config.EnableMKLDNN();
// 通过 API 获取 MKLDNN 启用结果 - true
std::cout << "Enable MKLDNN is: " << config.mkldnn_enabled() << std::endl;
// 设置 MKLDNN 的 cache 容量大小
config.SetMkldnnCacheCapacity(1);
// 设置启用 MKLDNN 进行加速的 OP 列表
std::unordered_set<std::string> op_list = {"softmax", "elementwise_add", "relu"};
config.SetMKLDNNOp(op_list);
代码示例 (2):使用 MKLDNN BFLOAT16 进行预测
// 创建 Config 对象
paddle_infer::Config config(FLAGS_infer_model + "/mobilenet");
// 启用 MKLDNN 进行预测
config.EnableMKLDNN();
// 启用 MKLDNN BFLOAT16 进行预测
config.EnableMkldnnBfloat16();
// 设置启用 MKLDNN BFLOAT16 的 OP 列表
config.SetBfloat16Op({"conv2d"});
// 通过 API 获取 MKLDNN BFLOAT16 启用结果 - true
std::cout << "Enable MKLDNN BF16 is: " << config.mkldnn_bfloat16_enabled() << std::endl;
使用 GPU 进行预测¶
注意:
Config 默认使用 CPU 进行预测,需要通过
EnableUseGpu来启用 GPU 预测可以尝试启用 CUDNN 和 TensorRT 进行 GPU 预测加速
GPU 设置¶
API定义如下:
// 启用 GPU 进行预测
// 参数:memory_pool_init_size_mb - 初始化分配的gpu显存,以MB为单位
// device_id - 设备id
// 返回:None
void EnableUseGpu(uint64_t memory_pool_init_size_mb, int device_id = 0);
// 禁用 GPU 进行预测
// 参数:None
// 返回:None
void DisableGpu();
// 判断是否启用 GPU
// 参数:None
// 返回:bool - 是否启用 GPU
bool use_gpu() const;
// 获取 GPU 的device id
// 参数:None
// 返回:int - GPU 的device id
int gpu_device_id() const;
// 获取 GPU 的初始显存大小
// 参数:None
// 返回:int - GPU 的初始的显存大小
int memory_pool_init_size_mb() const;
// 初始化显存占总显存的百分比
// 参数:None
// 返回:float - 初始的显存占总显存的百分比
float fraction_of_gpu_memory_for_pool() const;
// 开启线程流,目前的行为是为每一个线程绑定一个流,在将来该行为可能改变
// 参数:None
// 返回:None
void EnableGpuMultiStream();
// 判断是否开启线程流
// 参数:None
// 返回:bool - 是否是否开启线程流
bool thread_local_stream_enabled() const;
GPU设置代码示例:
// 创建默认 Config 对象
paddle_infer::Config config;
// 启用 GPU 进行预测 - 初始化 GPU 显存 100M, Deivce_ID 为 0
config.EnableUseGpu(100, 0);
// 通过 API 获取 GPU 信息
std::cout << "Use GPU is: " << config.use_gpu() << std::endl; // true
std::cout << "Init mem size is: " << config.memory_pool_init_size_mb() << std::endl;
std::cout << "Init mem frac is: " << config.fraction_of_gpu_memory_for_pool() << std::endl;
std::cout << "GPU device id is: " << config.gpu_device_id() << std::endl;
// 禁用 GPU 进行预测
config.DisableGpu();
// 通过 API 获取 GPU 信息
std::cout << "Use GPU is: " << config.use_gpu() << std::endl; // false
开启多线程流代码示例:
// 自定义 Barrier 类,用于线程间同步
class Barrier {
public:
explicit Barrier(std::size_t count) : _count(count) {}
void Wait() {
std::unique_lock<std::mutex> lock(_mutex);
if (--_count) {
_cv.wait(lock, [this] { return _count == 0; });
} else {
_cv.notify_all();
}
}
private:
std::mutex _mutex;
std::condition_variable _cv;
std::size_t _count;
};
int test_main(const paddle_infer::Config& config, Barrier* barrier = nullptr) {
static std::mutex mutex;
// 创建 Predictor 对象
std::shared_ptr<paddle_infer::Predictor> predictor;
{
std::unique_lock<std::mutex> lock(mutex);
predictor = std::move(paddle_infer::CreatePredictor(config));
}
if (barrier) {
barrier->Wait();
}
// 准备输入数据
int input_num = shape_production(INPUT_SHAPE);
std::vector<float> input_data(input_num, 1);
auto input_names = predictor->GetInputNames();
auto input_tensor = predictor->GetInputHandle(input_names[0]);
input_tensor->Reshape(INPUT_SHAPE);
input_tensor->CopyFromCpu(input_data.data());
// 执行预测
predictor->Run();
// 获取预测输出
auto output_names = predictor->GetOutputNames();
auto output_tensor = predictor->GetInputHandle(output_names[0]);
std::vector<int> output_shape = output_tensor->shape();
std::cout << "Output shape is " << shape_to_string(output_shape) << std::endl;
}
int main(int argc, char **argv) {
const size_t thread_num = 5;
std::vector<std::thread> threads(thread_num);
Barrier barrier(thread_num);
// 创建 5 个线程,并为每个线程开启一个单独的GPU Stream
for (size_t i = 0; i < threads.size(); ++i) {
threads[i] = std::thread([&barrier, i]() {
paddle_infer::Config config;
config.EnableUseGpu(100, 0);
config.SetModel(FLAGS_infer_model);
config.EnableGpuMultiStream();
test_main(config, &barrier);
});
}
for (auto& th : threads) {
th.join();
}
}
CUDNN 设置¶
注意: 启用 CUDNN 的前提为已经启用 GPU,否则启用 CUDNN 无法生效。
API定义如下:
// 启用 CUDNN 进行预测加速
// 参数:None
// 返回:None
void EnableCUDNN();
// 判断是否启用 CUDNN
// 参数:None
// 返回:bool - 是否启用 CUDNN
bool cudnn_enabled() const;
代码示例:
// 创建默认 Config 对象
paddle_infer::Config config();
// 启用 GPU 进行预测
config.EnableUseGpu(100, 0);
// 启用 CUDNN 进行预测加速
config.EnableCUDNN();
// 通过 API 获取 CUDNN 启用结果
std::cout << "Enable CUDNN is: " << config.cudnn_enabled() << std::endl; // true
// 禁用 GPU 进行预测
config.DisableGpu();
// 启用 CUDNN 进行预测加速 - 因为 GPU 被禁用,因此 CUDNN 启用不生效
config.EnableCUDNN();
// 通过 API 获取 CUDNN 启用结果
std::cout << "Enable CUDNN is: " << config.cudnn_enabled() << std::endl; // false
TensorRT 设置¶
注意:
启用 TensorRT 的前提为已经启用 GPU,否则启用 TensorRT 无法生效
对存在LoD信息的模型,如Bert, Ernie等NLP模型,必须使用动态 Shape
启用 TensorRT OSS 可以支持更多 plugin,详细参考 TensorRT OSS
更多 TensorRT 详细信息,请参考 使用Paddle-TensorRT库预测。
API定义如下:
// 启用 TensorRT 进行预测加速
// 参数:workspace_size - 指定 TensorRT 使用的工作空间大小
// max_batch_size - 设置最大的 batch 大小,运行时 batch 大小不得超过此限定值
// min_subgraph_size - Paddle-TRT 是以子图的形式运行,为了避免性能损失,当子图内部节点个数
// 大于 min_subgraph_size 的时候,才会使用 Paddle-TRT 运行
// precision - 指定使用 TRT 的精度,支持 FP32(kFloat32),FP16(kHalf),Int8(kInt8)
// use_static - 若指定为 true,在初次运行程序的时候会将 TRT 的优化信息进行序列化到磁盘上,
// 下次运行时直接加载优化的序列化信息而不需要重新生成
// use_calib_mode - 若要运行 Paddle-TRT INT8 离线量化校准,需要将此选项设置为 true
// 返回:None
void EnableTensorRtEngine(int workspace_size = 1 << 20,
int max_batch_size = 1, int min_subgraph_size = 3,
Precision precision = Precision::kFloat32,
bool use_static = false,
bool use_calib_mode = true);
// 判断是否启用 TensorRT
// 参数:None
// 返回:bool - 是否启用 TensorRT
bool tensorrt_engine_enabled() const;
// 设置 TensorRT 的动态 Shape
// 参数:min_input_shape - TensorRT 子图支持动态 shape 的最小 shape
// max_input_shape - TensorRT 子图支持动态 shape 的最大 shape
// optim_input_shape - TensorRT 子图支持动态 shape 的最优 shape
// disable_trt_plugin_fp16 - 设置 TensorRT 的 plugin 不在 fp16 精度下运行
// 返回:None
void SetTRTDynamicShapeInfo(
std::map<std::string, std::vector<int>> min_input_shape,
std::map<std::string, std::vector<int>> max_input_shape,
std::map<std::string, std::vector<int>> optim_input_shape,
bool disable_trt_plugin_fp16 = false);
// 启用 TensorRT OSS 进行预测加速
// 参数:None
// 返回:None
void EnableTensorRtOSS();
// 判断是否启用 TensorRT OSS
// 参数:None
// 返回:bool - 是否启用 TensorRT OSS
bool tensorrt_oss_enabled();
代码示例 (1):使用 TensorRT FP32 / FP16 / INT8 进行预测
// 创建 Config 对象
paddle_infer::Config config(FLAGS_infer_model + "/mobilenet");
// 启用 GPU 进行预测
config.EnableUseGpu(100, 0);
// 启用 TensorRT 进行预测加速 - FP32
config.EnableTensorRtEngine(1 << 20, 1, 3,
paddle_infer::PrecisionType::kFloat32, false, false);
// 通过 API 获取 TensorRT 启用结果 - true
std::cout << "Enable TensorRT is: " << config.tensorrt_engine_enabled() << std::endl;
// 启用 TensorRT 进行预测加速 - FP16
config.EnableTensorRtEngine(1 << 20, 1, 3,
paddle_infer::PrecisionType::kHalf, false, false);
// 通过 API 获取 TensorRT 启用结果 - true
std::cout << "Enable TensorRT is: " << config.tensorrt_engine_enabled() << std::endl;
// 启用 TensorRT 进行预测加速 - Int8
config.EnableTensorRtEngine(1 << 20, 1, 3,
paddle_infer::PrecisionType::kInt8, false, true);
// 通过 API 获取 TensorRT 启用结果 - true
std::cout << "Enable TensorRT is: " << config.tensorrt_engine_enabled() << std::endl;
代码示例 (2):使用 TensorRT 动态 Shape 进行预测
// 创建 Config 对象
paddle_infer::Config config(FLAGS_infer_model + "/mobilenet");
// 启用 GPU 进行预测
config.EnableUseGpu(100, 0);
// 启用 TensorRT 进行预测加速 - Int8
config.EnableTensorRtEngine(1 << 30, 1, 1,
paddle_infer::PrecisionType::kInt8, false, true);
// 设置模型输入的动态 Shape 范围
std::map<std::string, std::vector<int>> min_input_shape = {{"image", {1, 1, 3, 3}}};
std::map<std::string, std::vector<int>> max_input_shape = {{"image", {1, 1, 10, 10}}};
std::map<std::string, std::vector<int>> opt_input_shape = {{"image", {1, 1, 3, 3}}};
// 设置 TensorRT 的动态 Shape
config.SetTRTDynamicShapeInfo(min_input_shape, max_input_shape, opt_input_shape);
代码示例 (3):使用 TensorRT OSS 进行预测
// 创建 Config 对象
paddle_infer::Config config(FLAGS_infer_model + "/mobilenet");
// 启用 GPU 进行预测
config.EnableUseGpu(100, 0);
// 启用 TensorRT 进行预测加速
config.EnableTensorRtEngine();
// 启用 TensorRT OSS 进行预测加速
config.EnableTensorRtOSS();
// 通过 API 获取 TensorRT OSS 启用结果 - true
std::cout << "Enable TensorRT is: " << config.tensorrt_oss_enabled() << std::endl;
使用 XPU 进行预测¶
API定义如下:
// 启用 XPU 进行预测
// 参数:l3_workspace_size - l3 cache 分配的显存大小
// 返回:None
void EnableXpu(int l3_workspace_size = 0xfffc00);
代码示例:
// 创建 Config 对象
paddle_infer::Config config(FLAGS_model_dir);
// 启用 XPU,并设置 l3 cache 大小为 100M
config.EnableXpu(100);
设置模型优化方法¶
IR 优化¶
注意: 关于自定义 IR 优化 Pass,请参考 PaddlePassBuilder 类
API定义如下:
// 启用 IR 优化
// 参数:x - 是否开启 IR 优化,默认打开
// 返回:None
void SwitchIrOptim(int x = true);
// 判断是否开启 IR 优化
// 参数:None
// 返回:bool - 是否开启 IR 优化
bool ir_optim() const;
// 设置是否在图分析阶段打印 IR,启用后会在每一个 PASS 后生成 dot 文件
// 参数:x - 是否打印 IR,默认关闭
// 返回:None
void SwitchIrDebug(int x = true);
// 返回 pass_builder,用来自定义图分析阶段选择的 IR
// 参数:None
// 返回:PassStrategy - pass_builder对象
PassStrategy* pass_builder() const;
代码示例:
// 创建 Config 对象
paddle_infer::Config config(FLAGS_model_dir);
// 开启 IR 优化
config.SwitchIrOptim();
// 开启 IR 打印
config.SwitchIrDebug();
// 得到 pass_builder 对象
auto pass_builder = config.pass_builder();
// 在 IR 优化阶段,去除 fc_fuse_pass
pass_builder->DeletePass("fc_fuse_pass");
// 通过 API 获取 IR 优化是否开启 - true
std::cout << "IR Optim is: " << config.ir_optim() << std::endl;
// 根据Config对象创建预测器对象
auto predictor = paddle_infer::CreatePredictor(config);
运行结果示例:
# SwitchIrOptim 开启 IR 优化后,运行中会有如下 LOG 输出
--- Running analysis [ir_graph_build_pass]
--- Running analysis [ir_graph_clean_pass]
--- Running analysis [ir_analysis_pass]
--- Running IR pass [simplify_with_basic_ops_pass]
--- Running IR pass [attention_lstm_fuse_pass]
--- Running IR pass [seqconv_eltadd_relu_fuse_pass]
...
--- Running analysis [inference_op_replace_pass]
--- Running analysis [ir_graph_to_program_pass]
# SwitchIrDebug 开启 IR 打印后,运行结束之后会在目录下生成如下 DOT 文件
-rw-r--r-- 1 root root 70K Nov 17 10:47 0_ir_simplify_with_basic_ops_pass.dot
-rw-r--r-- 1 root root 72K Nov 17 10:47 10_ir_fc_gru_fuse_pass.dot
-rw-r--r-- 1 root root 72K Nov 17 10:47 11_ir_graph_viz_pass.dot
...
-rw-r--r-- 1 root root 72K Nov 17 10:47 8_ir_mul_lstm_fuse_pass.dot
-rw-r--r-- 1 root root 72K Nov 17 10:47 9_ir_graph_viz_pass.dot
Lite 子图¶
// 启用 Lite 子图
// 参数:precision_mode - Lite 子图的运行精度,默认为 FP32
// zero_copy - 启用 zero_copy,lite 子图与 paddle inference 之间共享数据
// Passes_filter - 设置 lite 子图的 pass
// ops_filter - 设置不使用 lite 子图运行的 op
// 返回:None
void EnableLiteEngine(
AnalysisConfig::Precision precision_mode = Precision::kFloat32,
bool zero_copy = false,
const std::vector<std::string>& passes_filter = {},
const std::vector<std::string>& ops_filter = {});
// 判断是否启用 Lite 子图
// 参数:None
// 返回:bool - 是否启用 Lite 子图
bool lite_engine_enabled() const;
示例代码:
// 创建 Config 对象
paddle_infer::Config config(FLAGS_model_dir);
config.EnableUseGpu(100, 0);
config.EnableLiteEngine(paddle_infer::PrecisionType::kFloat32);
// 通过 API 获取 Lite 子图启用信息 - true
std::cout << "Lite Engine is: " << config.lite_engine_enabled() << std::endl;
启用内存优化¶
API定义如下:
// 开启内存/显存复用,具体降低内存效果取决于模型结构
// 参数:None
// 返回:None
void EnableMemoryOptim();
// 判断是否开启内存/显存复用
// 参数:None
// 返回:bool - 是否开启内/显存复用
bool enable_memory_optim() const;
代码示例:
// 创建 Config 对象
paddle_infer::Config config(FLAGS_infer_model + "/mobilenet");
// 开启 CPU 显存优化
config.EnableMemoryOptim();
// 通过 API 获取 CPU 是否已经开启显存优化 - true
std::cout << "CPU Mem Optim is: " << config.enable_memory_optim() << std::endl;
// 启用 GPU 进行预测
config.EnableUseGpu(100, 0);
// 开启 GPU 显存优化
config.EnableMemoryOptim();
// 通过 API 获取 GPU 是否已经开启显存优化 - true
std::cout << "GPU Mem Optim is: " << config.enable_memory_optim() << std::endl;
设置缓存路径¶
注意: 如果当前使用的为 TensorRT INT8 且设置从内存中加载模型,则必须通过 SetOptimCacheDir 来设置缓存路径。
API定义如下:
// 设置缓存路径
// 参数:opt_cache_dir - 缓存路径
// 返回:None
void SetOptimCacheDir(const std::string& opt_cache_dir);
代码示例:
// 创建 Config 对象
paddle_infer::Config config(FLAGS_infer_model + "/mobilenet");
// 设置缓存路径
config.SetOptimCacheDir(FLAGS_infer_model + "/OptimCacheDir");
FC Padding¶
API定义如下:
// 禁用 FC Padding
// 参数:None
// 返回:None
void DisableFCPadding();
// 判断是否启用 FC Padding
// 参数:None
// 返回:bool - 是否启用 FC Padding
bool use_fc_padding() const;
代码示例:
// 创建 Config 对象
paddle_infer::Config config(FLAGS_infer_model + "/mobilenet");
// 禁用 FC Padding
config.DisableFCPadding();
// 通过 API 获取是否禁用 FC Padding - false
std::cout << "Disable FC Padding is: " << config.use_fc_padding() << std::endl;
Profile 设置¶
API定义如下:
// 打开 Profile,运行结束后会打印所有 OP 的耗时占比。
// 参数:None
// 返回:None
void EnableProfile();
// 判断是否开启 Profile
// 参数:None
// 返回:bool - 是否开启 Profile
bool profile_enabled() const;
代码示例:
// 创建 Config 对象
paddle_infer::Config config(FLAGS_infer_model + "/mobilenet");
// 打开 Profile
config.EnableProfile();
// 判断是否开启 Profile - true
std::cout << "Profile is: " << config.profile_enabled() << std::endl;
执行预测之后输出的 Profile 的结果如下:
-------------------------> Profiling Report <-------------------------
Place: CPU
Time unit: ms
Sorted by total time in descending order in the same thread
------------------------- Overhead Summary -------------------------
Total time: 1085.33
Computation time Total: 1066.24 Ratio: 98.2411%
Framework overhead Total: 19.0902 Ratio: 1.75893%
------------------------- GpuMemCpy Summary -------------------------
GpuMemcpy Calls: 0 Total: 0 Ratio: 0%
------------------------- Event Summary -------------------------
Event Calls Total Min. Max. Ave. Ratio.
thread0::conv2d 210 319.734 0.815591 6.51648 1.52254 0.294595
thread0::load 137 284.596 0.114216 258.715 2.07735 0.26222
thread0::depthwise_conv2d 195 266.241 0.955945 2.47858 1.36534 0.245308
thread0::elementwise_add 210 122.969 0.133106 2.15806 0.585568 0.113301
thread0::relu 405 56.1807 0.021081 0.585079 0.138718 0.0517635
thread0::batch_norm 195 25.8073 0.044304 0.33896 0.132345 0.0237783
thread0::fc 15 7.13856 0.451674 0.714895 0.475904 0.0065773
thread0::pool2d 15 1.48296 0.09054 0.145702 0.0988637 0.00136636
thread0::softmax 15 0.941837 0.032175 0.460156 0.0627891 0.000867786
thread0::scale 15 0.240771 0.013394 0.030727 0.0160514 0.000221841
Log 设置¶
API定义如下:
// 去除 Paddle Inference 运行中的 LOG
// 参数:None
// 返回:None
void DisableGlogInfo();
// 判断是否禁用 LOG
// 参数:None
// 返回:bool - 是否禁用 LOG
bool glog_info_disabled() const;
代码示例:
// 创建 Config 对象
paddle_infer::Config config(FLAGS_infer_model + "/mobilenet");
// 去除 Paddle Inference 运行中的 LOG
config.DisableGlogInfo();
// 判断是否禁用 LOG - true
std::cout << "GLOG INFO is: " << config.glog_info_disabled() << std::endl;
仅供内部使用¶
API定义如下:
// 转化为 NativeConfig,不推荐使用
// 参数:None
// 返回:当前 Config 对应的 NativeConfig
NativeConfig ToNativeConfig() const;
// 设置是否使用Feed, Fetch OP,仅内部使用
// 当使用 ZeroCopyTensor 时,需设置为 false
// 参数:x - 是否使用Feed, Fetch OP,默认为 true
// 返回:None
void SwitchUseFeedFetchOps(int x = true);
// 判断是否使用Feed, Fetch OP
// 参数:None
// 返回:bool - 是否使用Feed, Fetch OP
bool use_feed_fetch_ops_enabled() const;
// 设置是否需要指定输入 Tensor 的 Name,仅对内部 ZeroCopyTensor 有效
// 参数:x - 是否指定输入 Tensor 的 Name,默认为 true
// 返回:None
void SwitchSpecifyInputNames(bool x = true);
// 判断是否需要指定输入 Tensor 的 Name,仅对内部 ZeroCopyTensor 有效
// 参数:None
// 返回:bool - 是否需要指定输入 Tensor 的 Name
bool specify_input_name() const;
// 设置 Config 为无效状态,仅内部使用,保证每一个 Config 仅用来初始化一次 Predictor
// 参数:None
// 返回:None
void SetInValid();
// 判断当前 Config 是否有效
// 参数:None
// 返回:bool - 当前 Config 是否有效
bool is_valid() const;
代码示例:
// 创建 Config 对象
paddle_infer::Config config(FLAGS_infer_model + "/mobilenet");
// 转化为 NativeConfig
auto native_config = analysis_config->ToNativeConfig();
// 禁用 Feed, Fetch OP
config.SwitchUseFeedFetchOps(false);
// 返回是否使用 Feed, Fetch OP - false
std::cout << "UseFeedFetchOps is: " << config.use_feed_fetch_ops_enabled() << std::endl;
// 设置需要指定输入 Tensor 的 Name
config.SwitchSpecifyInputNames(true);
// 返回是否需要指定输入 Tensor 的 Name - true
std::cout << "Specify Input Name is: " << config.specify_input_name() << std::endl;
// 设置 Config 为无效状态
config.SetInValid();
// 判断当前 Config 是否有效 - false
std::cout << "Config validation is: " << config.is_valid() << std::endl;
PaddlePassBuilder 类¶
注意: PaddlePassBuilder 对象通过 Config 的 pass_builder 方法进行获取。其中存在2个成员对象 AnalysisPasses 和 Passes,AnalysisPasses 独立于 Passes 之外,仅 AppendAnalysisPass 和 AnalysisPasses 两个 API 能对其进行修改和读取,其余 API 的操作对象都仅限于Passes。
类及方法定义如下:
// 设置 IR 图分析阶段的 passes
// 参数:passes - IR 图分析阶段的 passes 的字符串列表
// 返回:None
void SetPasses(std::initializer_list<std::string> passes);
// 在 Passes 末尾添加 pass
// 参数:pass_type - 需要添加的 pass 字符串
// 返回:None
void AppendPass(const std::string &pass_type);
// 在 Passes 中的第 idx 位置插入 pass
// 参数:idx - 插入的 index 位置
// pass_type - 需要插入的 pass 字符串
// 返回:None
void InsertPass(size_t idx, const std::string &pass_type);
// 删除第 idx 位置的pass
// 参数:idx - 删除的 index 位置
// 返回:None
void DeletePass(size_t idx);
// 删除字符串匹配为 pass_type 的 pass
// 参数:pass_type - 需要删除的 pass 字符串
// 返回:None
void DeletePass(const std::string &pass_type);
// 清空所有 IR 优化中的 Passes
// 参数:None
// 返回:None
void ClearPasses();
// 启用Debug, 会在每一个 PASS 优化后生成当前计算图 DOT
// 即在每一个 fuse pass 之后添加一个 graph_viz_pass 进行 pass 可视化
// 参数:None
// 返回:None
void TurnOnDebug();
// 获取 IR 图分析阶段的 Passes 中的可读信息
// 参数:None
// 返回:std::string - 所有 Passes 的可读信息
std::string DebugString();
// 获取 IR 图分析阶段的所有 Passes
// 参数:None
// 返回:std::vector<std::string> - 所有 Passes 字符串列表
const std::vector<std::string> &AllPasses();
// 添加 Analysis Pass
// 参数:pass - 需要添加的 Analysis Pass 字符串表示
// 返回:None
void AppendAnalysisPass(const std::string &pass);
// 获取 IR 图分析阶段的所有 Analysis Passes
// 参数:None
// 返回:std::vector<std::string> - 所有 Analysis Passes 字符串列表
std::vector<std::string> AnalysisPasses() const;
自定义 IR Pass 代码示例:
// 构造 Config 对象
paddle_infer::Config config(FLAGS_infer_model);
// 开启 IR 优化
config.SwitchIrOptim();
// 得到 pass_builder 对象
auto pass_builder = config.pass_builder();
// 获取 pass_builder 中的所有 Passes
const std::vector<std::string> all_passes = pass_builder->AllPasses();
// all_passes 中返回结果如下:
// simplify_with_basic_ops_pass
// attention_lstm_fuse_pass
// ...
// runtime_context_cache_pass
// 清空所有 Passes
pass_builder->ClearPasses();
// 设置 Passes
pass_builder->SetPasses({"attention_lstm_fuse_pass", "fc_gru_fuse_pass"});
// 在末尾处添加pass
pass_builder->AppendPass("fc_fuse_pass");
// 删除 Passes
pass_builder->DeletePass("fc_fuse_pass");
// 在 idx = 0 的位置添加 pass
pass_builder->InsertPass(0, "fc_fuse_pass");
// 删除 idx = 0 所在位置的 pass
pass_builder->DeletePass(0);
// 启用Debug, 会在每一个 PASS 优化后生成当前计算图 DOT
// 即在每一个 pass 之后添加一个 graph_viz_pass
pass_builder->TurnOnDebug();
// 获取 IR 图分析阶段的 Passes 中的可读信息
std::cout << pass_builder->DebugString() << std::endl;
// 运行以上代码得到的输出结果如下:
// - attention_lstm_fuse_pass
// - graph_viz_pass
// - fc_gru_fuse_pass
// - graph_viz_pass
对 Analysis Pass 进行操作和读取示例:
// 构造 Config 对象
paddle_infer::Config config(FLAGS_infer_model);
// 开启 IR 优化
config.SwitchIrOptim();
// 得到 pass_builder 对象
auto pass_builder = config.pass_builder();
// 添加 analysis pass
pass_builder->AppendAnalysisPass("ir_analysis_pass");
// 获取 pass_builder 中的所有 Analysis Passes
const std::vector<std::string> analysis_passes = pass_builder->AnalysisPasses();
// analysis_passes 中返回结果如下:
// ir_graph_build_pass
// ir_graph_clean_pass
// ...
// ir_graph_to_program_pass
Predictor 类¶
Paddle Inference的预测器,由 CreatePredictor 根据 Config 进行创建。用户可以根据Predictor提供的接口设置输入数据、执行模型预测、获取输出等。
获取输入输出¶
API 定义如下:
// 获取所有输入 Tensor 的名称
// 参数:None
// 返回:std::vector<std::string> - 所有输入 Tensor 的名称
std::vector<std::string> GetInputNames();
// 根据名称获取输入 Tensor 的句柄
// 参数:name - Tensor 的名称
// 返回:std::unique_ptr<Tensor> - 指向 Tensor 的指针
std::unique_ptr<Tensor> GetInputHandle(const std::string& name);
// 获取所有输出 Tensor 的名称
// 参数:None
// 返回:std::vector<std::string> - 所有输出 Tensor 的名称
std::vector<std::string> GetOutputNames();
// 根据名称获取输出 Tensor 的句柄
// 参数:name - Tensor 的名称
// 返回:std::unique_ptr<Tensor> - 指向 Tensor 的指针
std::unique_ptr<Tensor> GetOutputHandle(const std::string& name);
代码示例:
// 构造 Config 对象
paddle_infer::Config config(FLAGS_infer_model);
// 创建 Predictor
auto predictor = paddle_infer::CreatePredictor(config);
// 准备输入数据
int input_num = shape_production(INPUT_SHAPE);
std::vector<float> input_data(input_num, 1);
// 准备输入 Tensor
auto input_names = predictor->GetInputNames();
auto input_tensor = predictor->GetInputHandle(input_names[0]);
input_tensor->Reshape({1, 3, 224, 224});
input_tensor->CopyFromCpu(input_data.data());
// 执行预测
predictor->Run();
// 获取 Output Tensor
auto output_names = predictor->GetOutputNames();
auto output_tensor = predictor->GetInputHandle(output_names[0]);
运行和生成¶
API 定义如下:
// 执行模型预测,需要在设置输入数据后调用
// 参数:None
// 返回:None
bool Run();
// 根据该Predictor,克隆一个新的Predictor,两个Predictor之间共享权重
// 参数:None
// 返回:std::unique_ptr<Predictor> - 新的 Predictor
std::unique_ptr<Predictor> Clone();
// 释放中间Tensor
// 参数:None
// 返回:None
void ClearIntermediateTensor();
// 释放内存池中的所有临时 Tensor
// 参数:None
// 返回:uint64_t - 释放的内存字节数
uint64_t TryShrinkMemory();
代码示例:
// 创建 Predictor
auto predictor = paddle_infer::CreatePredictor(config);
// 准备输入数据
int input_num = shape_production(INPUT_SHAPE);
std::vector<float> input_data(input_num, 1);
// 准备输入 Tensor
auto input_names = predictor->GetInputNames();
auto input_tensor = predictor->GetInputHandle(input_names[0]);
input_tensor->Reshape({1, 3, 224, 224});
input_tensor->CopyFromCpu(input_data.data());
// 执行预测
predictor->Run();
// 获取 Output Tensor
auto output_names = predictor->GetOutputNames();
auto output_t = predictor->GetOutputHandle(output_names[0]);
std::vector<int> output_shape = output_t->shape();
int out_num = std::accumulate(output_shape.begin(), output_shape.end(),
1, std::multiplies<int>());
// 获取 Output 数据
std::vector<float> out_data;
out_data.resize(out_num);
output_t->CopyToCpu(out_data.data());
// 释放中间Tensor
predictor->ClearIntermediateTensor();
// 释放内存池中的所有临时 Tensor
predictor->TryShrinkMemory();
PredictorPool 类¶
PredictorPool 对 Predictor 进行了简单的封装,通过传入config和thread的数目来完成初始化,在每个线程中,根据自己的线程id直接从池中取出对应的 Predictor 来完成预测过程。
构造函数和API定义如下:
// PredictorPool构造函数
// 参数:config - Config 对象
// size - Predictor 对象数量
PredictorPool(const Config& config, size_t size = 1);
// 根据线程 ID 取出该线程对应的 Predictor
// 参数:idx - 线程 ID
// 返回:Predictor* - 线程 ID 对应的 Predictor 指针
Predictor* Retrive(size_t idx);
代码示例
// 构造 Config 对象
paddle_infer::Config config(FLAGS_infer_model);
// 启用 GPU 预测
config.EnableUseGpu(100, 0);
// 根据 Config 对象创建 PredictorPool
paddle_infer::PredictorPool pred_pool(config, 4);
// 获取 ID 为 2 的 Predictor 对象
auto pred = pred_pool.Retrive(2);
Tensor 类¶
Tensor 是 Paddle Inference 的数据组织形式,用于对底层数据进行封装并提供接口对数据进行操作,包括设置 Shape、数据、LoD 信息等。
注意: 应使用 Predictor 的 GetInputHandle 和 GetOuputHandle 接口获取输入输出 Tensor。
Tensor 类的API定义如下:
// 设置 Tensor 的维度信息
// 参数:shape - 维度信息
// 返回:None
void Reshape(const std::vector<int>& shape);
// 从 CPU 获取数据,设置到 Tensor 内部
// 参数:data - CPU 数据指针
// 返回:None
template <typename T>
void CopyFromCpu(const T* data);
// 从 Tensor 中获取数据到 CPU
// 参数:data - CPU 数据指针
// 返回:None
template <typename T>
void CopyToCpu(T* data);
// 获取 Tensor 底层数据指针,用于设置 Tensor 输入数据
// 在调用这个 API 之前需要先对输入 Tensor 进行 Reshape
// 参数:place - 获取 Tensor 的 PlaceType
// 返回:数据指针
template <typename T>
T* mutable_data(PlaceType place);
// 获取 Tensor 底层数据的常量指针,用于读取 Tensor 输出数据
// 参数:place - 获取 Tensor 的 PlaceType
// size - 获取 Tensor 的 size
// 返回:数据指针
template <typename T>
T* data(PlaceType* place, int* size) const;
// 设置 Tensor 的 LoD 信息
// 参数:x - Tensor 的 LoD 信息
// 返回:None
void SetLoD(const std::vector<std::vector<size_t>>& x);
// 获取 Tensor 的 LoD 信息
// 参数:None
// 返回:std::vector<std::vector<size_t>> - Tensor 的 LoD 信息
std::vector<std::vector<size_t>> lod() const;
// 获取 Tensor 的 DataType
// 参数:None
// 返回:DataType - Tensor 的 DataType
DataType type() const;
// 获取 Tensor 的维度信息
// 参数:None
// 返回:std::vector<int> - Tensor 的维度信息
std::vector<int> shape() const;
// 获取 Tensor 的 Name
// 参数:None
// 返回:std::string& - Tensor 的 Name
const std::string& name() const;
代码示例:
// 构造 Config 对象
paddle_infer::Config config(FLAGS_infer_model);
// 创建 Predictor
auto predictor = paddle_infer::CreatePredictor(config);
// 准备输入数据
int input_num = shape_production(INPUT_SHAPE);
std::vector<float> input_data(input_num, 1);
// 获取输入 Tensor
auto input_names = predictor->GetInputNames();
auto input_tensor = predictor->GetInputHandle(input_names[0]);
// 设置输入 Tensor 的维度信息
input_tensor->Reshape(INPUT_SHAPE);
// 获取输入 Tensor 的 Name
auto name = input_tensor->name();
// 方式1: 通过 mutable_data 设置输入数据
std::copy_n(input_data.begin(), input_data.size(),
input_tensor->mutable_data<float>(PaddlePlace::kCPU));
// 方式2: 通过 CopyFromCpu 设置输入数据
input_tensor->CopyFromCpu(input_data.data());
// 执行预测
predictor->Run();
// 获取 Output Tensor
auto output_names = predictor->GetOutputNames();
auto output_tensor = predictor->GetInputHandle(output_names[0]);
// 获取 Output Tensor 的维度信息
std::vector<int> output_shape = output_tensor->shape();
// 方式1: 通过 data 获取 Output Tensor 的数据
paddle_infer::PlaceType place;
int size = 0;
auto* out_data = output_tensor->data<float>(&place, &size);
// 方式2: 通过 CopyToCpu 获取 Output Tensor 的数据
std::vector<float> output_data;
output_data.resize(output_size);
output_tensor->CopyToCpu(output_data.data());
枚举类型¶
DataType¶
DataType为模型中Tensor的数据精度,默认值为 FLOAT32。枚举变量与 API 定义如下:
// DataType 枚举类型定义
enum DataType {
FLOAT32,
INT64,
INT32,
UINT8,
};
// 获取各个 DataType 对应的字节数
// 参数:dtype - DataType 枚举
// 输出:int - 字节数
int GetNumBytesOfDataType(DataType dtype)
代码示例:
// 创建 FLOAT32 类型 DataType
auto data_type = paddle_infer::DataType::FLOAT32;
// 输出 data_type 的字节数 - 4
std::cout << paddle_infer::GetNumBytesOfDataType(data_type) << std::endl;
PrecisionType¶
PrecisionType设置模型的运行精度,默认值为 kFloat32(float32)。枚举变量定义如下:
// PrecisionType 枚举类型定义
enum class PrecisionType {
kFloat32 = 0, ///< fp32
kInt8, ///< int8
kHalf, ///< fp16
};
代码示例:
// 创建 Config 对象
paddle_infer::Config config(FLAGS_infer_model + "/mobilenet");
// 启用 GPU 进行预测
config.EnableUseGpu(100, 0);
// 启用 TensorRT 进行预测加速 - FP16
config.EnableTensorRtEngine(1 << 20, 1, 3,
paddle_infer::PrecisionType::kHalf, false, false);
PlaceType¶
PlaceType为目标设备硬件类型,用户可以根据应用场景选择硬件平台类型。枚举变量定义如下:
// PlaceType 枚举类型定义
enum class PlaceType { kUNK = -1, kCPU, kGPU };
代码示例:
// 创建 Config 对象
paddle_infer::Config config;
// 启用 GPU 预测
config.EnableUseGpu(100, 0);
config.SetModel(model_dir);
// 创建 Predictor
auto predictor = paddle_infer::CreatePredictor(config);
// 准备输入数据
int input_num = shape_production(INPUT_SHAPE);
std::vector<float> input_data(input_num, 1);
// 准备输入 Tensor
auto input_names = predictor->GetInputNames();
auto input_tensor = predictor->GetInputHandle(input_names[0]);
input_tensor->Reshape({1, 3, 224, 224});
input_tensor->CopyFromCpu(input_data.data());
// 执行预测
predictor->Run();
// 获取 Output Tensor
auto output_names = predictor->GetOutputNames();
auto output_tensor = predictor->GetInputHandle(output_names[0]);
// 获取 Output Tensor 的 PlaceType 和 数据指针
paddle_infer::PlaceType place;
int size = 0;
auto* out_data = output_tensor->data<float>(&place, &size);
// 输出 Place 结果 - true
std::cout << (place == paddle_infer::PlaceType::kGPU) << std::endl;
std::cout << size / sizeof(float) << std::endl;
Python API 文档¶
create_predictor 方法¶
API定义如下:
# 根据 Config 构建预测执行器 Predictor
# 参数: config - 用于构建 Predictor 的配置信息
# 返回: Predictor - 预测执行器
paddle.inference.create_predictor(config: Config)
代码示例:
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config("./mobilenet_v1")
# 根据 config 创建 predictor
predictor = paddle_infer.create_predictor(config)
get_version 方法¶
API定义如下:
# 获取 Paddle 版本信息
# 参数: NONE
# 返回: str - Paddle 版本信息
paddle.inference.get_version()
代码示例:
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 获取 Paddle 版本信息
paddle_infer.get_version()
# 获得输出如下:
# version: 2.0.0-rc0
# commit: 97227e6
# branch: HEAD
Config 类¶
Config 类定义¶
Config 类为用于配置构建 Predictor 对象的配置信息,如模型路径、是否开启gpu等等。
构造函数定义如下:
# Config 类定义,输入为 None
class paddle.inference.Config()
# Config 类定义,输入为其他 Config 对象
class paddle.inference.Config(config: Config)
# Config 类定义,输入为非 Combine 模型的文件夹路径
class paddle.inference.Config(model_dir: str)
# Config 类定义,输入分别为 Combine 模型的模型文件路径和参数文件路径
class paddle.inference.Config(prog_file: str, params_file: str)
代码示例 (1):加载预测模型 - 非Combined模型
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config()
# 加载非Combined模型
config.set_model("./mobilenet_v1")
# 根据 config 创建 predictor
predictor = paddle_infer.create_predictor(config)
代码示例 (2):加载预测模型 - 非Combined模型
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config("./mobilenet_v1")
# 根据 config 创建 predictor
predictor = paddle_infer.create_predictor(config)
代码示例 (3):加载预测模型 - Combined模型
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config("./mobilenet_v2/__model__", "./mobilenet_v2/__params__")
# 根据 config 创建 predictor
predictor = paddle_infer.create_predictor(config)
设置预测模型¶
从文件中加载预测模型 - 非Combined模型¶
API定义如下:
# 设置模型文件路径,当需要从磁盘加载非 Combined 模型时使用
# 参数:model_dir - 模型文件夹路径 - str 类型
# 返回:None
paddle.inference.Config.set_model(model_dir: str)
# 获取非combine模型的文件夹路径
# 参数:None
# 返回:str - 模型文件夹路径
paddle.inference.Config.model_dir()
代码示例:
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config()
# 设置非combine模型的文件夹路径
config.set_model("./mobilenet_v1")
# 获取非combine模型的文件夹路径
print(config.model_dir())
# 根据 config 创建 predictor
predictor = paddle_infer.create_predictor(config)
从文件中加载预测模型 - Combined 模型¶
API定义如下:
# 设置模型文件路径,当需要从磁盘加载 Combined 模型时使用
# 参数:prog_file_path - 模型文件路径
# params_file_path - 参数文件路径
# 返回:None
paddle.inference.Config.set_model(prog_file_path: str, params_file_path: str)
# 设置模型文件路径,当需要从磁盘加载 Combined 模型时使用。
# 参数:x - 模型文件路径
# 返回:None
paddle.inference.Config.set_prog_file(x: str)
# 设置参数文件路径,当需要从磁盘加载 Combined 模型时使用
# 参数:x - 参数文件路径
# 返回:None
paddle.inference.Config.set_params_file(x: str)
# 获取 Combined 模型的模型文件路径
# 参数:None
# 返回:str - 模型文件路径
paddle.inference.Config.prog_file()
# 获取 Combined 模型的参数文件路径
# 参数:None
# 返回:str - 参数文件路径
paddle.inference.Config.params_file()
代码示例:
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config()
# 通过 API 设置模型文件夹路径
config.set_prog_file("./mobilenet_v2/__model__")
config.set_params_file("./mobilenet_v2/__params__")
# 通过 API 获取 config 中的模型文件和参数文件路径
print(config.prog_file())
print(config.params_file())
# 根据 config 创建 predictor
predictor = paddle_infer.create_predictor(config)
从内存中加载预测模型¶
API定义如下:
# 从内存加载模型
# 参数:prog_buffer - 内存中模型结构数据
# prog_buffer_size - 内存中模型结构数据的大小
# params_buffer - 内存中模型参数数据
# params_buffer_size - 内存中模型参数数据的大小
# 返回:None
paddle.inference.Config.set_model_buffer(prog_buffer: str, prog_buffer_size: int,
params_buffer: str, params_buffer_size: int)
# 判断是否从内存中加载模型
# 参数:None
# 返回:bool - 是否从内存中加载模型
paddle.inference.Config.model_from_memory()
代码示例:
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config()
# 加载模型文件到内存
with open('./mobilenet_v2/__model__', 'rb') as prog_file:
prog_data=prog_file.read()
with open('./mobilenet_v2/__params__', 'rb') as params_file:
params_data=params_file.read()
# 从内存中加载模型
config.set_model_buffer(prog_data, len(prog_data), params_data, len(params_data))
# 通过 API 获取 config 中 model_from_memory 的值 - True
print(config.model_from_memory())
# 根据 config 创建 predictor
predictor = paddle_infer.create_predictor(config)
使用 CPU 进行预测¶
注意:
在 CPU 型号允许的情况下,进行预测库下载或编译试尽量使用带 AVX 和 MKL 的版本
可以尝试使用 Intel 的 MKLDNN 进行 CPU 预测加速,默认 CPU 不启用 MKLDNN
在 CPU 可用核心数足够时,可以通过设置
set_cpu_math_library_num_threads将线程数调高一些,默认线程数为 1
CPU 设置¶
API定义如下:
# 设置 CPU Blas 库计算线程数
# 参数:cpu_math_library_num_threads - blas库计算线程数
# 返回:None
paddle.inference.Config.set_cpu_math_library_num_threads(cpu_math_library_num_threads: int)
# 获取 CPU Blas 库计算线程数
# 参数:None
# 返回:int - cpu blas库计算线程数
paddle.inference.Config.cpu_math_library_num_threads()
代码示例:
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config()
# 设置 CPU Blas 库线程数为 10
config.set_cpu_math_library_num_threads(10)
# 通过 API 获取 CPU 信息 - 10
print(config.cpu_math_library_num_threads())
MKLDNN 设置¶
注意:
启用 MKLDNN 的前提为已经使用 CPU 进行预测,否则启用 MKLDNN 无法生效
启用 MKLDNN BF16 要求 CPU 型号可以支持 AVX512,否则无法启用 MKLDNN BF16
set_mkldnn_cache_capacity请参考 MKLDNN cache设计文档
API定义如下:
# 启用 MKLDNN 进行预测加速
# 参数:None
# 返回:None
paddle.inference.Config.enable_mkldnn()
# 判断是否启用 MKLDNN
# 参数:None
# 返回:bool - 是否启用 MKLDNN
paddle.inference.Config.mkldnn_enabled()
# 设置 MKLDNN 针对不同输入 shape 的 cache 容量大小
# 参数:int - cache 容量大小
# 返回:None
paddle.inference.Config.set_mkldnn_cache_capacity(capacity: int=0)
# 指定使用 MKLDNN 加速的 OP 集合
# 参数:使用 MKLDNN 加速的 OP 集合
# 返回:None
paddle.inference.Config.set_mkldnn_op(op_list: Set[str])
# 启用 MKLDNN BFLOAT16
# 参数:None
# 返回:None
paddle.inference.Config.enable_mkldnn_bfloat16()
# 指定使用 MKLDNN BFLOAT16 加速的 OP 集合
# 参数:使用 MKLDNN BFLOAT16 加速的 OP 集合
# 返回:None
paddle.inference.Config.set_bfloat16_op(op_list: Set[str])
代码示例 (1):使用 MKLDNN 进行预测
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config("./mobilenet_v1")
# 启用 MKLDNN 进行预测
config.enable_mkldnn()
# 通过 API 获取 MKLDNN 启用结果 - true
print(config.mkldnn_enabled())
# 设置 MKLDNN 的 cache 容量大小
config.set_mkldnn_cache_capacity(1)
# 设置启用 MKLDNN 进行加速的 OP 列表
config.set_mkldnn_op({"softmax", "elementwise_add", "relu"})
代码示例 (2):使用 MKLDNN BFLOAT16 进行预测
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config("./mobilenet_v1")
# 启用 MKLDNN 进行预测
config.enable_mkldnn()
# 启用 MKLDNN BFLOAT16 进行预测
config.enable_mkldnn_bfloat16()
# 设置启用 MKLDNN BFLOAT16 的 OP 列表
config.set_bfloat16_op({"conv2d"})
使用 GPU 进行预测¶
注意:
Config 默认使用 CPU 进行预测,需要通过
EnableUseGpu来启用 GPU 预测可以尝试启用 CUDNN 和 TensorRT 进行 GPU 预测加速
GPU 设置¶
API定义如下:
# 启用 GPU 进行预测
# 参数:memory_pool_init_size_mb - 初始化分配的gpu显存,以MB为单位
# device_id - 设备id
# 返回:None
paddle.inference.Config.enable_use_gpu(memory_pool_init_size_mb: int, device_id: int)
# 禁用 GPU 进行预测
# 参数:None
# 返回:None
paddle.inference.Config.disable_gpu()
# 判断是否启用 GPU
# 参数:None
# 返回:bool - 是否启用 GPU
paddle.inference.Config.use_gpu()
# 获取 GPU 的device id
# 参数:None
# 返回:int - GPU 的device id
paddle.inference.Config.gpu_device_id()
# 获取 GPU 的初始显存大小
# 参数:None
# 返回:int - GPU 的初始的显存大小
paddle.inference.Config.memory_pool_init_size_mb()
# 初始化显存占总显存的百分比
# 参数:None
# 返回:float - 初始的显存占总显存的百分比
paddle.inference.Config.fraction_of_gpu_memory_for_pool()
GPU设置代码示例:
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config("./mobilenet_v1")
# 启用 GPU 进行预测 - 初始化 GPU 显存 100M, Deivce_ID 为 0
config.enable_use_gpu(100, 0)
# 通过 API 获取 GPU 信息
print("Use GPU is: {}".format(config.use_gpu())) # True
print("Init mem size is: {}".format(config.memory_pool_init_size_mb())) # 100
print("Init mem frac is: {}".format(config.fraction_of_gpu_memory_for_pool())) # 0.003
print("GPU device id is: {}".format(config.gpu_device_id())) # 0
# 禁用 GPU 进行预测
config.disable_gpu()
# 通过 API 获取 GPU 信息
print("Use GPU is: {}".format(config.use_gpu())) # False
TensorRT 设置¶
注意:
启用 TensorRT 的前提为已经启用 GPU,否则启用 TensorRT 无法生效
对存在LoD信息的模型,如Bert, Ernie等NLP模型,必须使用动态 Shape
启用 TensorRT OSS 可以支持更多 plugin,详细参考 TensorRT OSS
更多 TensorRT 详细信息,请参考 使用Paddle-TensorRT库预测。
API定义如下:
# 启用 TensorRT 进行预测加速
# 参数:workspace_size - 指定 TensorRT 使用的工作空间大小
# max_batch_size - 设置最大的 batch 大小,运行时 batch 大小不得超过此限定值
# min_subgraph_size - Paddle-TRT 是以子图的形式运行,为了避免性能损失,当子图内部节点个数
# 大于 min_subgraph_size 的时候,才会使用 Paddle-TRT 运行
# precision - 指定使用 TRT 的精度,支持 FP32(kFloat32),FP16(kHalf),Int8(kInt8)
# use_static - 若指定为 true,在初次运行程序的时候会将 TRT 的优化信息进行序列化到磁盘上,
# 下次运行时直接加载优化的序列化信息而不需要重新生成
# use_calib_mode - 若要运行 Paddle-TRT INT8 离线量化校准,需要将此选项设置为 true
# 返回:None
paddle.inference.Config.enable_tensorrt_engine(workspace_size: int = 1 << 20,
max_batch_size: int,
min_subgraph_size: int,
precision_mode: PrecisionType,
use_static: bool,
use_calib_mode: bool)
# 判断是否启用 TensorRT
# 参数:None
# 返回:bool - 是否启用 TensorRT
paddle.inference.Config.tensorrt_engine_enabled()
# 设置 TensorRT 的动态 Shape
# 参数:min_input_shape - TensorRT 子图支持动态 shape 的最小 shape
# max_input_shape - TensorRT 子图支持动态 shape 的最大 shape
# optim_input_shape - TensorRT 子图支持动态 shape 的最优 shape
# disable_trt_plugin_fp16 - 设置 TensorRT 的 plugin 不在 fp16 精度下运行
# 返回:None
paddle.inference.Config.set_trt_dynamic_shape_info(min_input_shape: Dict[str, List[int]]={},
max_input_shape: Dict[str, List[int]]={},
optim_input_shape: Dict[str, List[int]]={},
disable_trt_plugin_fp16: bool=False)
# 启用 TensorRT OSS 进行预测加速
# 参数:None
# 返回:None
paddle.inference.Config.enable_tensorrt_oss()
# 判断是否启用 TensorRT OSS
# 参数:None
# 返回:bool - 是否启用 TensorRT OSS
paddle.inference.Config.tensorrt_oss_enabled()
代码示例 (1):使用 TensorRT FP32 / FP16 / INT8 进行预测
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config("./mobilenet_v1")
# 启用 GPU 进行预测 - 初始化 GPU 显存 100M, Deivce_ID 为 0
config.enable_use_gpu(100, 0)
# 启用 TensorRT 进行预测加速 - FP32
config.enable_tensorrt_engine(workspace_size = 1 << 20,
max_batch_size = 1,
min_subgraph_size = 3,
precision_mode=paddle_infer.PrecisionType.Float32,
use_static = False, use_calib_mode = False)
# 通过 API 获取 TensorRT 启用结果 - true
print("Enable TensorRT is: {}".format(config.tensorrt_engine_enabled()))
# 启用 TensorRT 进行预测加速 - FP16
config.enable_tensorrt_engine(workspace_size = 1 << 20,
max_batch_size = 1,
min_subgraph_size = 3,
precision_mode=paddle_infer.PrecisionType.Half,
use_static = False, use_calib_mode = False)
# 通过 API 获取 TensorRT 启用结果 - true
print("Enable TensorRT is: {}".format(config.tensorrt_engine_enabled()))
# 启用 TensorRT 进行预测加速 - Int8
config.enable_tensorrt_engine(workspace_size = 1 << 20,
max_batch_size = 1,
min_subgraph_size = 3,
precision_mode=paddle_infer.PrecisionType.Int8,
use_static = False, use_calib_mode = False)
# 通过 API 获取 TensorRT 启用结果 - true
print("Enable TensorRT is: {}".format(config.tensorrt_engine_enabled()))
代码示例 (2):使用 TensorRT 动态 Shape 进行预测
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config("./mobilenet_v1")
# 启用 GPU 进行预测 - 初始化 GPU 显存 100M, Deivce_ID 为 0
config.enable_use_gpu(100, 0)
# 启用 TensorRT 进行预测加速 - Int8
config.enable_tensorrt_engine(workspace_size = 1 << 30,
max_batch_size = 1,
min_subgraph_size = 1,
precision_mode=paddle_infer.PrecisionType.Int8,
use_static = False, use_calib_mode = True)
# 设置 TensorRT 的动态 Shape
config.set_trt_dynamic_shape_info(min_input_shape={"image": [1, 1, 3, 3]},
max_input_shape={"image": [1, 1, 10, 10]},
optim_input_shape={"image": [1, 1, 3, 3]})
代码示例 (3):使用 TensorRT OSS 进行预测
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config("./mobilenet_v1")
# 启用 GPU 进行预测 - 初始化 GPU 显存 100M, Deivce_ID 为 0
config.enable_use_gpu(100, 0)
# 启用 TensorRT 进行预测加速
config.enable_tensorrt_engine()
# 启用 TensorRT OSS 进行预测加速
config.enable_tensorrt_oss()
# 通过 API 获取 TensorRT OSS 启用结果 - true
print("Enable TensorRT OSS is: {}".format(config.tensorrt_oss_enabled()))
使用 XPU 进行预测¶
API定义如下:
# 启用 XPU 进行预测
# 参数:l3_workspace_size - l3 cache 分配的显存大小
# 返回:None
paddle.inference.Config.enable_xpu(l3_workspace_size: int = 0xfffc00)
代码示例:
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config("./mobilenet_v1")
# 启用 XPU,并设置 l3 cache 大小为 100M
config.enable_xpu(100)
设置模型优化方法¶
IR 优化¶
API定义如下:
# 启用 IR 优化
# 参数:x - 是否开启 IR 优化,默认打开
# 返回:None
paddle.inference.Config.switch_ir_optim(x: bool = True)
# 判断是否开启 IR 优化
# 参数:None
# 返回:bool - 是否开启 IR 优化
paddle.inference.Config.ir_optim()
# 设置是否在图分析阶段打印 IR,启用后会在每一个 PASS 后生成 dot 文件
# 参数:x - 是否打印 IR,默认关闭
# 返回:None
paddle.inference.Config.switch_ir_debug(x: int=True)
# 返回 pass_builder,用来自定义图分析阶段选择的 IR
# 参数:None
# 返回:PassStrategy - pass_builder对象
paddle.inference.Config.pass_builder()
# 删除字符串匹配为 pass 的 pass
# 参数:pass - 需要删除的 pass 字符串
# 返回:None
paddle.inference.Config.delete_pass(pass: str)
代码示例:
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config("./mobilenet_v1")
# 开启 IR 优化
config.switch_ir_optim()
# 开启 IR 打印
config.switch_ir_debug()
# 得到 pass_builder 对象
pass_builder = config.pass_builder()
# 或者直接通过 config 去除 fc_fuse_pass
config.delete_pass("fc_fuse_pass")
# 通过 API 获取 IR 优化是否开启 - true
print("IR Optim is: {}".format(config.ir_optim()))
# 根据 config 创建 predictor
predictor = paddle_infer.create_predictor(config)
运行结果示例:
# switch_ir_optim 开启 IR 优化后,运行中会有如下 LOG 输出
--- Running analysis [ir_graph_build_pass]
--- Running analysis [ir_graph_clean_pass]
--- Running analysis [ir_analysis_pass]
--- Running IR pass [simplify_with_basic_ops_pass]
--- Running IR pass [attention_lstm_fuse_pass]
--- Running IR pass [seqconv_eltadd_relu_fuse_pass]
...
--- Running analysis [inference_op_replace_pass]
--- Running analysis [ir_graph_to_program_pass]
# switch_ir_debug 开启 IR 打印后,运行结束之后会在目录下生成如下 DOT 文件
-rw-r--r-- 1 root root 70K Nov 17 10:47 0_ir_simplify_with_basic_ops_pass.dot
-rw-r--r-- 1 root root 72K Nov 17 10:47 10_ir_fc_gru_fuse_pass.dot
-rw-r--r-- 1 root root 72K Nov 17 10:47 11_ir_graph_viz_pass.dot
...
-rw-r--r-- 1 root root 72K Nov 17 10:47 8_ir_mul_lstm_fuse_pass.dot
-rw-r--r-- 1 root root 72K Nov 17 10:47 9_ir_graph_viz_pass.dot
Lite 子图¶
# 启用 Lite 子图
# 参数:precision_mode - Lite 子图的运行精度,默认为 FP32
# zero_copy - 启用 zero_copy,lite 子图与 paddle inference 之间共享数据
# Passes_filter - 设置 lite 子图的 pass
# ops_filter - 设置不使用 lite 子图运行的 op
# 返回:None
paddle.inference.Config.enable_lite_engine(precision_mode: PrecisionType = paddle_infer.PrecisionType.Float32,
zero_copy: bool = False,
passes_filter: List[str]=[],
ops_filter: List[str]=[])
# 判断是否启用 Lite 子图
# 参数:None
# 返回:bool - 是否启用 Lite 子图
paddle.inference.Config.lite_engine_enabled()
示例代码:
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config("./mobilenet_v1")
# 启用 GPU 进行预测
config.enable_use_gpu(100, 0)
# 启用 Lite 子图
config.enable_lite_engine(paddle_infer.PrecisionType.Float32)
# 通过 API 获取 Lite 子图启用信息 - true
print("Lite Engine is: {}".format(config.lite_engine_enabled()))
启用内存优化¶
API定义如下:
# 开启内存/显存复用,具体降低内存效果取决于模型结构。
# 参数:None
# 返回:None
paddle.inference.Config.enable_memory_optim()
代码示例:
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config("./mobilenet_v1")
# 开启 CPU 显存优化
config.enable_memory_optim()
# 启用 GPU 进行预测
config.enable_use_gpu(100, 0)
# 开启 GPU 显存优化
config.enable_memory_optim()
设置缓存路径¶
注意: 如果当前使用的为 TensorRT INT8 且设置从内存中加载模型,则必须通过 SetOptimCacheDir 来设置缓存路径。
API定义如下:
# 设置缓存路径
# 参数:opt_cache_dir - 缓存路径
# 返回:None
paddle.inference.Config.set_optim_cache_dir(opt_cache_dir: str)
代码示例:
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config("./mobilenet_v1")
# 设置缓存路径
config.set_optim_cache_dir("./OptimCacheDir")
Profile 设置¶
API定义如下:
# 打开 Profile,运行结束后会打印所有 OP 的耗时占比。
# 参数:None
# 返回:None
paddle.inference.Config.enable_profile()
代码示例:
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config("./mobilenet_v1")
# 打开 Profile
config.enable_profile()
执行预测之后输出的 Profile 的结果如下:
-------------------------> Profiling Report <-------------------------
Place: CPU
Time unit: ms
Sorted by total time in descending order in the same thread
------------------------- Overhead Summary -------------------------
Total time: 1085.33
Computation time Total: 1066.24 Ratio: 98.2411%
Framework overhead Total: 19.0902 Ratio: 1.75893%
------------------------- GpuMemCpy Summary -------------------------
GpuMemcpy Calls: 0 Total: 0 Ratio: 0%
------------------------- Event Summary -------------------------
Event Calls Total Min. Max. Ave. Ratio.
thread0::conv2d 210 319.734 0.815591 6.51648 1.52254 0.294595
thread0::load 137 284.596 0.114216 258.715 2.07735 0.26222
thread0::depthwise_conv2d 195 266.241 0.955945 2.47858 1.36534 0.245308
thread0::elementwise_add 210 122.969 0.133106 2.15806 0.585568 0.113301
thread0::relu 405 56.1807 0.021081 0.585079 0.138718 0.0517635
thread0::batch_norm 195 25.8073 0.044304 0.33896 0.132345 0.0237783
thread0::fc 15 7.13856 0.451674 0.714895 0.475904 0.0065773
thread0::pool2d 15 1.48296 0.09054 0.145702 0.0988637 0.00136636
thread0::softmax 15 0.941837 0.032175 0.460156 0.0627891 0.000867786
thread0::scale 15 0.240771 0.013394 0.030727 0.0160514 0.000221841
Log 设置¶
API定义如下:
# 去除 Paddle Inference 运行中的 LOG
# 参数:None
# 返回:None
paddle.inference.Config.disable_glog_info()
# 判断是否禁用 LOG
# 参数:None
# 返回:bool - 是否禁用 LOG
paddle.inference.Config.glog_info_disabled()
代码示例:
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config("./mobilenet_v1")
# 去除 Paddle Inference 运行中的 LOG
config.disable_glog_info()
# 判断是否禁用 LOG - true
print("GLOG INFO is: {}".format(config.glog_info_disabled()))
仅供内部使用¶
API定义如下:
# 转化为 NativeConfig,不推荐使用
# 参数:None
# 返回:当前 Config 对应的 NativeConfig
paddle.inference.Config.to_native_config()
# 设置是否使用Feed, Fetch OP,仅内部使用
# 当使用 ZeroCopyTensor 时,需设置为 false
# 参数:x - 是否使用Feed, Fetch OP,默认为 true
# 返回:None
paddle.inference.Config.switch_use_feed_fetch_ops(x: bool = True)
# 判断是否使用Feed, Fetch OP
# 参数:None
# 返回:bool - 是否使用Feed, Fetch OP
paddle.inference.Config.use_feed_fetch_ops_enabled()
# 设置是否需要指定输入 Tensor 的 Name,仅对内部 ZeroCopyTensor 有效
# 参数:x - 是否指定输入 Tensor 的 Name,默认为 true
# 返回:None
paddle.inference.Config.switch_specify_input_names(x: bool = True)
# 判断是否需要指定输入 Tensor 的 Name,仅对内部 ZeroCopyTensor 有效
# 参数:None
# 返回:bool - 是否需要指定输入 Tensor 的 Name
paddle.inference.Config.specify_input_name()
代码示例:
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config("./mobilenet_v1")
# 转化为 NativeConfig
native_config = config.to_native_config()
# 禁用 Feed, Fetch OP
config.switch_use_feed_fetch_ops(False)
# 返回是否使用 Feed, Fetch OP - false
print("switch_use_feed_fetch_ops is: {}".format(config.use_feed_fetch_ops_enabled()))
# 设置需要指定输入 Tensor 的 Name
config.switch_specify_input_names(True)
# 返回是否需要指定输入 Tensor 的 Name - true
print("specify_input_name is: {}".format(config.specify_input_name()))
Predictor 类¶
Paddle Inference的预测器,由 create_predictor 根据 Config 进行创建。用户可以根据Predictor提供的接口设置输入数据、执行模型预测、获取输出等。
类及方法定义如下:
# Predictor 类定义
class paddle.inference.Predictor
# 获取所有输入 Tensor 的名称
# 参数:None
# 返回:List[str] - 所有输入 Tensor 的名称
paddle.inference.Predictor.get_input_names()
# 根据名称获取输入 Tensor 的句柄
# 参数:name - Tensor 的名称
# 返回:Tensor - 输入 Tensor
paddle.inference.Predictor.get_input_handle(name: str)
# 获取所有输出 Tensor 的名称
# 参数:None
# 返回:List[str] - 所有输出 Tensor 的名称
paddle.inference.Predictor.get_output_names()
# 根据名称获取输出 Tensor 的句柄
# 参数:name - Tensor 的名称
# 返回:Tensor - 输出 Tensor
paddle.inference.Predictor.get_output_handle(name: str)
# 执行模型预测,需要在设置输入数据后调用
# 参数:None
# 返回:None
paddle.inference.Predictor.run()
# 根据该 Predictor,克隆一个新的 Predictor,两个 Predictor 之间共享权重
# 参数:None
# 返回:Predictor - 新的 Predictor
paddle.inference.Predictor.clone()
# 释放中间 Tensor
# 参数:None
# 返回:None
paddle.inference.Predictor.clear_intermediate_tensor()
# 释放内存池中的所有临时 Tensor
# 参数:None
# 返回:int - 释放的内存字节数
paddle.inference.Predictor.try_shrink_memory()
代码示例
import numpy
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config("./mobilenet_v1")
# 根据 config 创建 predictor
predictor = paddle_infer.create_predictor(config)
# 获取输入 Tensor
input_names = predictor.get_input_names()
input_tensor = predictor.get_input_handle(input_names[0])
# 从 CPU 获取数据,设置到 Tensor 内部
fake_input = numpy.random.randn(1, 3, 224, 224).astype("float32")
input_tensor.copy_from_cpu(fake_input)
# 执行预测
predictor.run()
# 获取输出 Tensor
output_names = predictor.get_output_names()
output_tensor = predictor.get_output_handle(output_names[0])
# 释放中间Tensor
predictor.clear_intermediate_tensor()
# 释放内存池中的所有临时 Tensor
predictor.try_shrink_memory()
PredictorPool 类¶
PredictorPool 对 Predictor 进行了简单的封装,通过传入config和thread的数目来完成初始化,在每个线程中,根据自己的线程id直接从池中取出对应的 Predictor 来完成预测过程。
类及方法定义如下:
# PredictorPool 类定义
# 参数:config - Config 类型
# size - Predictor 对象数量
class paddle.inference.PredictorPool(config: Config, size: int)
# 根据线程 ID 取出该线程对应的 Predictor
# 参数:idx - 线程 ID
# 返回:Predictor - 线程 ID 对应的 Predictor
paddle.inference.PredictorPool.retrive(idx: int)
代码示例
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 Config
config = paddle_infer.Config("./mobilenet_v1")
# 创建 PredictorPool
pred_pool = paddle_infer.PredictorPool(config, 4)
# 获取 ID 为 2 的 Predictor 对象
predictor = pred_pool.retrive(2)
Tensor 类¶
Tensor是Paddle Inference的数据组织形式,用于对底层数据进行封装并提供接口对数据进行操作,包括设置Shape、数据、LoD信息等。
注意: 应使用 Predictor 的 get_input_handle 和 get_output_handle 接口获取输入输出 Tensor。
类及方法定义如下:
# Tensor 类定义
class paddle.inference.Tensor
# 设置 Tensor 的维度信息
# 参数:shape - 维度信息
# 返回:None
paddle.inference.Tensor.reshape(shape: numpy.ndarray|List[int])
# 从 CPU 获取数据,设置到 Tensor 内部
# 参数:data - CPU 数据 - 支持float, int32, int64
# 返回:None
paddle.inference.Tensor.copy_from_cpu(data: numpy.ndarray)
# 从 Tensor 中获取数据到 CPU
# 参数:None
# 返回:numpy.ndarray - CPU 数据
paddle.inference.Tensor.copy_to_cpu()
# 获取 Tensor 的维度信息
# 参数:None
# 返回:List[int] - Tensor 的维度信息
paddle.inference.Tensor.shape()
# 设置 Tensor 的 LoD 信息
# 参数:x - Tensor 的 LoD 信息
# 返回:None
paddle.inference.Tensor.set_lod(x: numpy.ndarray|List[List[int]])
# 获取 Tensor 的 LoD 信息
# 参数:None
# 返回:List[List[int]] - Tensor 的 LoD 信息
paddle.inference.Tensor.lod()
# 获取 Tensor 的数据类型
# 参数:None
# 返回:DataType - Tensor 的数据类型
paddle.inference.Tensor.type()
代码示例:
import numpy
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config("./mobilenet_v1")
# 根据 config 创建 predictor
predictor = paddle_infer.create_predictor(config)
# 准备输入数据
fake_input = numpy.random.randn(1, 3, 224, 224).astype("float32")
# 获取输入 Tensor
input_names = predictor.get_input_names()
input_tensor = predictor.get_input_handle(input_names[0])
# 设置 Tensor 的维度信息
input_tensor.reshape([1, 3, 224, 224])
# 从 CPU 获取数据,设置到 Tensor 内部
input_tensor.copy_from_cpu(fake_input)
# 执行预测
predictor.run()
# 获取输出 Tensor
output_names = predictor.get_output_names()
output_tensor = predictor.get_output_handle(output_names[0])
# 从 Tensor 中获取数据到 CPU
output_data = output_tensor.copy_to_cpu()
# 获取 Tensor 的维度信息
output_shape = output_tensor.shape()
# 获取 Tensor 的数据类型
output_type = output_tensor.type()
枚举类型¶
DataType¶
DataType定义了Tensor的数据类型,由传入Tensor的numpy数组类型确定。
# DataType 枚举定义
class paddle.inference.DataType:
# 获取各个 DataType 对应的字节数
# 参数:dtype - DataType 枚举
# 输出:dtype 对应的字节数
paddle.inference.get_num_bytes_of_data_type(dtype: DataType)
DataType 中包括以下成员:
INT64: 64位整型INT32: 32位整型FLOAT32: 32位浮点型
代码示例:
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 FLOAT32 类型 DataType
data_type = paddle_infer.DataType.FLOAT32
# 输出 data_type 的字节数 - 4
paddle_infer.get_num_bytes_of_data_type(data_type)
PrecisionType¶
PrecisionType设置模型的运行精度,默认值为 kFloat32(float32)。枚举变量定义如下:
# PrecisionType 枚举定义
class paddle.inference.PrecisionType
PrecisionType 中包括以下成员:
Float32: FP32 模式运行Half: FP16 模式运行Int8: INT8 模式运行
代码示例:
# 引用 paddle inference 预测库
import paddle.inference as paddle_infer
# 创建 config
config = paddle_infer.Config("./mobilenet_v1")
# 启用 GPU, 初始化100M显存,使用gpu id为0
config.enable_use_gpu(100, 0)
# 开启 TensorRT 预测,精度为 FP32,开启 INT8 离线量化校准
config.enable_tensorrt_engine(precision_mode=paddle_infer.PrecisionType.Float32,
use_calib_mode=True)
C API 文档¶
AnalysisConfig 方法¶
创建 AnalysisConfig¶
AnalysisConfig 对象相关方法用于创建预测相关配置,构建 Predictor 对象的配置信息,如模型路径、是否开启gpu等等。
相关方法定义如下:
// 创建 AnalysisConfig 对象
// 参数:None
// 返回:PD_AnalysisConfig* - AnalysisConfig 对象指针
PD_AnalysisConfig* PD_NewAnalysisConfig();
// 删除 AnalysisConfig 对象
// 参数:config - AnalysisConfig 对象指针
// 返回:None
void PD_DeleteAnalysisConfig(PD_AnalysisConfig* config);
// 设置 AnalysisConfig 为无效状态,保证每一个 AnalysisConfig 仅用来初始化一次 Predictor
// 参数:config - AnalysisConfig 对象指针
// 返回:None
void PD_SetInValid(PD_AnalysisConfig* config);
// 判断当前 AnalysisConfig 是否有效
// 参数:config - AnalysisConfig 对象指针
// 返回:bool - 当前 AnalysisConfig 是否有效
bool PD_IsValid(const PD_AnalysisConfig* config);
代码示例:
// 创建 AnalysisConfig 对象
PD_AnalysisConfig* config = PD_NewAnalysisConfig();
// 判断当前 Config 是否有效 - True
printf("Config validation is: %s\n", PD_IsValid(config) ? "True" : "False");
// 设置 Config 为无效状态
PD_SetInValid(config);
// 判断当前 Config 是否有效 - false
printf("Config validation is: %s\n", PD_IsValid(config) ? "True" : "False");
// 删除 AnalysisConfig 对象
PD_DeleteAnalysisConfig(config);
设置预测模型¶
从文件中加载预测模型 - 非Combined模型¶
API定义如下:
// 设置模型文件路径
// 参数:config - AnalysisConfig 对象指针
// model_dir - 模型文件夹路径
// params_path - NULL, 当输入模型为非 Combined 模型时,该参数为空指针
// 返回:None
void PD_SetModel(PD_AnalysisConfig* config, const char* model_dir, const char* params_path);
// 获取非combine模型的文件夹路径
// 参数:config - AnalysisConfig 对象指针
// 返回:const chart * - 模型文件夹路径
const char* PD_ModelDir(const PD_AnalysisConfig* config);
代码示例:
// 创建 AnalysisConfig 对象
PD_AnalysisConfig* config = PD_NewAnalysisConfig();
// 设置预测模型路径,这里为非 Combined 模型
const char* model_dir = "./mobilenet_v1";
PD_SetModel(config, model_dir, NULL);
// 根据 Config 创建 Predictor
PD_Predictor* predictor = PD_NewPredictor(config);
// 输出模型路径
printf("Non-combined model dir is: %s\n", PD_ModelDir(config));
从文件中加载预测模型 - Combined 模型¶
API定义如下:
// 设置模型文件路径
// 参数:config - AnalysisConfig 对象指针
// model_dir - Combined 模型文件所在路径
// params_path - Combined 模型参数文件所在路径
// 返回:None
void PD_SetModel(PD_AnalysisConfig* config, const char* model_dir, const char* params_path);
// 设置模型文件路径,当需要从磁盘加载 Combined 模型时使用。
// 参数:config - AnalysisConfig 对象指针
// x - 模型文件路径
// 返回:None
void PD_SetProgFile(PD_AnalysisConfig* config, const char* x)
// 设置参数文件路径,当需要从磁盘加载 Combined 模型时使用
// 参数:config - AnalysisConfig 对象指针
// x - 参数文件路径
// 返回:None
void PD_SetParamsFile(PD_AnalysisConfig* config, const char* x)
// 获取 Combined 模型的模型文件路径
// 参数:config - AnalysisConfig 对象指针
// 返回:const char* - 模型文件路径
const char* PD_ProgFile(const PD_AnalysisConfig* config)
// 获取 Combined 模型的参数文件路径
// 参数:config - AnalysisConfig 对象指针
// 返回:const char* - 参数文件路径
const char* PD_ParamsFile(const PD_AnalysisConfig* config)
代码示例 (1):
// 创建 AnalysisConfig 对象
PD_AnalysisConfig* config = PD_NewAnalysisConfig();
// 设置预测模型路径,这里为非 Combined 模型
const char* model_path = "./model/model";
const char* params_path = "./model/params";
PD_SetModel(config, model_path, params_path);
// 根据 Config 创建 Predictor
PD_Predictor* predictor = PD_NewPredictor(config);
// 输出模型路径
printf("Non-combined model path is: %s\n", PD_ProgFile(config));
printf("Non-combined param path is: %s\n", PD_ParamsFile(config));
代码示例 (2):
// 创建 AnalysisConfig 对象
PD_AnalysisConfig* config = PD_NewAnalysisConfig();
// 设置预测模型路径,这里为非 Combined 模型
const char* model_path = "./model/model";
const char* params_path = "./model/params";
PD_SetProgFile(config, model_path);
PD_SetParamsFile(config, params_path);
// 根据 Config 创建 Predictor
PD_Predictor* predictor = PD_NewPredictor(config);
// 输出模型路径
printf("Non-combined model path is: %s\n", PD_ProgFile(config));
printf("Non-combined param path is: %s\n", PD_ParamsFile(config));
从内存中加载预测模型¶
API定义如下:
// 从内存加载模型
// 参数:config - AnalysisConfig 对象指针
// prog_buffer - 内存中模型结构数据
// prog_buffer_size - 内存中模型结构数据的大小
// params_buffer - 内存中模型参数数据
// params_buffer_size - 内存中模型参数数据的大小
// 返回:None
void PD_SetModelBuffer(PD_AnalysisConfig* config,
const char* prog_buffer, size_t prog_buffer_size,
const char* params_buffer, size_t params_buffer_size);
// 判断是否从内存中加载模型
// 参数:config - AnalysisConfig 对象指针
// 返回:bool - 是否从内存中加载模型
bool PD_ModelFromMemory(const PD_AnalysisConfig* config);
代码示例:
// 定义文件读取函数
void read_file(const char * filename, char ** filedata, size_t * filesize) {
FILE *file = fopen(filename, "rb");
if (file == NULL) {
printf("Failed to open file: %s\n", filename);
return;
}
fseek(file, 0, SEEK_END);
int64_t size = ftell(file);
if (size == 0) {
printf("File %s should not be empty, size is: %ld\n", filename, size);
return;
}
rewind(file);
*filedata = calloc(1, size+1);
if (!(*filedata)) {
printf("Failed to alloc memory.\n");
return;
}
*filesize = fread(*filedata, 1, size, file);
if ((*filesize) != size) {
printf("Read binary file bytes do not match with fseek!\n");
return;
}
fclose(file);
}
int main() {
// 创建 AnalysisConfig 对象
PD_AnalysisConfig* config = PD_NewAnalysisConfig();
// 设置预测模型路径,这里为非 Combined 模型
const char* model_path = "./model/model";
const char* params_path = "./model/params";
char * model_buffer = NULL;
char * param_buffer = NULL;
size_t model_size, param_size;
read_file(model_path, &model_buffer, &model_size);
read_file(params_path, ¶m_buffer, ¶m_size);
if(model_buffer == NULL) {
printf("Failed to load model buffer.\n");
return 1;
}
if(param_buffer == NULL) {
printf("Failed to load param buffer.\n");
return 1;
}
// 加载模型文件到内存,并获取文件大小
PD_SetModelBuffer(config, model_buffer, model_size, param_buffer, param_size);
// 输出是否从内存中加载模型
printf("Load model from memory is: %s\n", PD_ModelFromMemory(config) ? "true" : "false");
// 根据 Config 创建 Predictor
PD_Predictor* predictor = PD_NewPredictor(config);
PD_DeletePredictor(predictor);
PD_DeleteAnalysisConfig(config);
free(model_buffer);
free(param_buffer);
}
使用 CPU 进行预测¶
注意:
在 CPU 型号允许的情况下,进行预测库下载或编译试尽量使用带 AVX 和 MKL 的版本
可以尝试使用 Intel 的 MKLDNN 进行 CPU 预测加速,默认 CPU 不启用 MKLDNN
在 CPU 可用核心数足够时,可以通过设置
PD_SetCpuMathLibraryNumThreads将线程数调高一些,默认线程数为 1
CPU 设置¶
API定义如下:
// 设置 CPU Blas 库计算线程数
// 参数:config - AnalysisConfig 对象指针
// cpu_math_library_num_threads - blas库计算线程数
// 返回:None
void PD_SetCpuMathLibraryNumThreads(PD_AnalysisConfig* config,
int cpu_math_library_num_threads)
// 获取 CPU Blas 库计算线程数
// 参数:config - AnalysisConfig 对象指针
// 返回:int - cpu blas 库计算线程数
int PD_CpuMathLibraryNumThreads(const PD_AnalysisConfig* config);
代码示例:
// 创建 AnalysisConfig 对象
PD_AnalysisConfig* config = PD_NewAnalysisConfig();
// 设置 CPU Blas 库线程数为 10
PD_SetCpuMathLibraryNumThreads(config, 10);
// 通过 API 获取 CPU 信息
printf("CPU Math Lib Thread Num is: %d\n", PD_CpuMathLibraryNumThreads(config));
MKLDNN 设置¶
注意:
启用 MKLDNN 的前提为已经使用 CPU 进行预测,否则启用 MKLDNN 无法生效
启用 MKLDNN BF16 要求 CPU 型号可以支持 AVX512,否则无法启用 MKLDNN BF16
PD_SetMkldnnCacheCapacity请参考 MKLDNN cache设计文档
API定义如下:
// 启用 MKLDNN 进行预测加速
// 参数:config - AnalysisConfig 对象指针
// 返回:None
void PD_EnableMKLDNN(PD_AnalysisConfig* config);
// 判断是否启用 MKLDNN
// 参数:config - AnalysisConfig 对象指针
// 返回:bool - 是否启用 MKLDNN
bool PD_MkldnnEnabled(const PD_AnalysisConfig* config);
// 设置 MKLDNN 针对不同输入 shape 的 cache 容量大小
// 参数:config - AnalysisConfig 对象指针
// capacity - cache 容量大小
// 返回:None
void PD_SetMkldnnCacheCapacity(PD_AnalysisConfig* config, int capacity);
// 启用 MKLDNN BFLOAT16
// 参数:config - AnalysisConfig 对象指针
// 返回:None
void PD_EnableMkldnnBfloat16(PD_AnalysisConfig* config);
// 判断是否启用 MKLDNN BFLOAT16
// 参数:config - AnalysisConfig 对象指针
// 返回:bool - 是否启用 MKLDNN BFLOAT16
bool PD_MkldnnBfloat16Enabled(const PD_AnalysisConfig* config);
代码示例:
// 创建 AnalysisConfig 对象
PD_AnalysisConfig* config = PD_NewAnalysisConfig();
// 启用 MKLDNN 进行预测
PD_EnableMKLDNN(config);
// 通过 API 获取 MKLDNN 启用结果 - true
printf("Enable MKLDNN is: %s\n", PD_MkldnnEnabled(config) ? "True" : "False");
// 启用 MKLDNN BFLOAT16 进行预测
PD_EnableMkldnnBfloat16(config);
// 通过 API 获取 MKLDNN BFLOAT16 启用结果
// 如果当前CPU支持AVX512,则返回 true, 否则返回 false
printf("Enable MKLDNN BF16 is: %s\n", PD_MkldnnBfloat16Enabled(config) ? "True" : "False");
// 设置 MKLDNN 的 cache 容量大小
PD_SetMkldnnCacheCapacity(config, 1);
使用 GPU 进行预测¶
注意:
AnalysisConfig 默认使用 CPU 进行预测,需要通过
EnableUseGpu来启用 GPU 预测可以尝试启用 CUDNN 和 TensorRT 进行 GPU 预测加速
GPU 设置¶
API定义如下:
// 启用 GPU 进行预测
// 参数:config - AnalysisConfig 对象指针
// memory_pool_init_size_mb - 初始化分配的gpu显存,以MB为单位
// device_id - 设备id
// 返回:None
void PD_EnableUseGpu(PD_AnalysisConfig* config, int memory_pool_init_size_mb, int device_id);
// 禁用 GPU 进行预测
// 参数:config - AnalysisConfig 对象指针
// 返回:None
void PD_DisableGpu(PD_AnalysisConfig* config);
// 判断是否启用 GPU
// 参数:config - AnalysisConfig 对象指针
// 返回:bool - 是否启用 GPU
bool PD_UseGpu(const PD_AnalysisConfig* config);
// 获取 GPU 的device id
// 参数:config - AnalysisConfig 对象指针
// 返回:int - GPU 的device id
int PD_GpuDeviceId(const PD_AnalysisConfig* config);
// 获取 GPU 的初始显存大小
// 参数:config - AnalysisConfig 对象指针
// 返回:int - GPU 的初始的显存大小
int PD_MemoryPoolInitSizeMb(const PD_AnalysisConfig* config);
// 初始化显存占总显存的百分比
// 参数:config - AnalysisConfig 对象指针
// 返回:float - 初始的显存占总显存的百分比
float PD_FractionOfGpuMemoryForPool(const PD_AnalysisConfig* config);
GPU设置代码示例:
// 创建 AnalysisConfig 对象
PD_AnalysisConfig* config = PD_NewAnalysisConfig();
// 启用 GPU 进行预测 - 初始化 GPU 显存 100M, Deivce_ID 为 0
PD_EnableUseGpu(config, 100, 0);
// 通过 API 获取 GPU 信息
printf("Use GPU is: %s\n", PD_UseGpu(config) ? "True" : "False"); // True
printf("GPU deivce id is: %d\n", PD_GpuDeviceId(config));
printf("GPU memory size is: %d\n", PD_MemoryPoolInitSizeMb(config));
printf("GPU memory frac is: %f\n", PD_FractionOfGpuMemoryForPool(config));
// 禁用 GPU 进行预测
PD_DisableGpu(config);
// 通过 API 获取 GPU 信息
printf("Use GPU is: %s\n", PD_UseGpu(config) ? "True" : "False"); // False
CUDNN 设置¶
注意: 启用 CUDNN 的前提为已经启用 GPU,否则启用 CUDNN 无法生效。
API定义如下:
// 启用 CUDNN 进行预测加速
// 参数:config - AnalysisConfig 对象指针
// 返回:None
void PD_EnableCUDNN(PD_AnalysisConfig* config);
// 判断是否启用 CUDNN
// 参数:config - AnalysisConfig 对象指针
// 返回:bool - 是否启用 CUDNN
bool PD_CudnnEnabled(const PD_AnalysisConfig* config);
代码示例:
// 创建 AnalysisConfig 对象
PD_AnalysisConfig* config = PD_NewAnalysisConfig();
// 启用 GPU 进行预测 - 初始化 GPU 显存 100M, Deivce_ID 为 0
PD_EnableUseGpu(config, 100, 0);
// 启用 CUDNN 进行预测加速
PD_EnableCUDNN(config);
// 通过 API 获取 CUDNN 启用结果 - True
printf("Enable CUDNN is: %s\n", PD_CudnnEnabled(config) ? "True" : "False");
// 禁用 GPU 进行预测
PD_DisableGpu(config);
// 启用 CUDNN 进行预测加速 - 因为 GPU 被禁用,因此 CUDNN 启用不生效
PD_EnableCUDNN(config);
// 通过 API 获取 CUDNN 启用结果 - False
printf("Enable CUDNN is: %s\n", PD_CudnnEnabled(config) ? "True" : "False");
TensorRT 设置¶
注意:
启用 TensorRT 的前提为已经启用 GPU,否则启用 TensorRT 无法生效
对存在LoD信息的模型,如Bert, Ernie等NLP模型,必须使用动态 Shape
启用 TensorRT OSS 可以支持更多 plugin,详细参考 TensorRT OSS
更多 TensorRT 详细信息,请参考 使用Paddle-TensorRT库预测。
API定义如下:
// 启用 TensorRT 进行预测加速
// 参数:config - AnalysisConfig 对象指针
// workspace_size - 指定 TensorRT 使用的工作空间大小
// max_batch_size - 设置最大的 batch 大小,运行时 batch 大小不得超过此限定值
// min_subgraph_size - Paddle-TRT 是以子图的形式运行,为了避免性能损失,当子图内部节点个数
// 大于 min_subgraph_size 的时候,才会使用 Paddle-TRT 运行
// precision - 指定使用 TRT 的精度,支持 FP32(kFloat32),FP16(kHalf),Int8(kInt8)
// use_static - 若指定为 true,在初次运行程序的时候会将 TRT 的优化信息进行序列化到磁盘上,
// 下次运行时直接加载优化的序列化信息而不需要重新生成
// use_calib_mode - 若要运行 Paddle-TRT INT8 离线量化校准,需要将此选项设置为 true
// 返回:None
PD_EnableTensorRtEngine(PD_AnalysisConfig* config, int workspace_size, int max_batch_size,
int min_subgraph_size, Precision precision, bool use_static,
bool use_calib_mode);
// 判断是否启用 TensorRT
// 参数:config - AnalysisConfig 对象指针
// 返回:bool - 是否启用 TensorRT
bool PD_TensorrtEngineEnabled(const PD_AnalysisConfig* config);
代码示例:使用 TensorRT FP32 / FP16 / INT8 进行预测
// 创建 AnalysisConfig 对象
PD_AnalysisConfig* config = PD_NewAnalysisConfig();
// 启用 GPU 进行预测 - 初始化 GPU 显存 100M, Deivce_ID 为 0
PD_EnableUseGpu(config, 100, 0);
// 启用 TensorRT 进行预测加速 - FP32
PD_EnableTensorRtEngine(config, 1 << 20, 1, 3, kFloat32, false, false);
// 启用 TensorRT 进行预测加速 - FP16
PD_EnableTensorRtEngine(config, 1 << 20, 1, 3, kHalf, false, false);
// 启用 TensorRT 进行预测加速 - Int8
PD_EnableTensorRtEngine(config, 1 << 20, 1, 3, kInt8, false, false);
// 通过 API 获取 TensorRT 启用结果 - true
printf("Enable TensorRT is: %s\n", PD_TensorrtEngineEnabled(config) ? "True" : "False");
设置模型优化方法¶
API定义如下:
// 启用 IR 优化
// 参数:config - AnalysisConfig 对象指针
// x - 是否开启 IR 优化,默认打开
// 返回:None
void PD_SwitchIrOptim(PD_AnalysisConfig* config, bool x);
// 判断是否开启 IR 优化
// 参数:config - AnalysisConfig 对象指针
// 返回:bool - 是否开启 IR 优化
bool PD_IrOptim(const PD_AnalysisConfig* config);
// 设置是否在图分析阶段打印 IR,启用后会在每一个 PASS 后生成 dot 文件
// 参数:config - AnalysisConfig 对象指针
// x - 是否打印 IR,默认关闭
// 返回:None
void PD_SwitchIrDebug(PD_AnalysisConfig* config, bool x);
// 返回 pass_builder,用来自定义图分析阶段选择的 IR
// 参数:config - AnalysisConfig 对象指针
// pass_name - 需要删除的 pass 名称
// 返回:None
void PD_DeletePass(PD_AnalysisConfig* config, char* pass_name);
代码示例:
// 创建 AnalysisConfig 对象
PD_AnalysisConfig* config = PD_NewAnalysisConfig();
// 设置预测模型路径,这里为非 Combined 模型
const char* model_dir = "./mobilenet_v1";
PD_SetModel(config, model_dir, NULL);
// 开启 IR 优化
PD_SwitchIrOptim(config, true);
// 开启 IR 打印
PD_SwitchIrDebug(config, true);
// 通过 API 获取 IR 优化是否开启 - true
printf("IR Optim is: %s\n", PD_IrOptim(config) ? "True" : "False");
// 通过 config 去除 fc_fuse_pass
char * pass_name = "fc_fuse_pass";
PD_DeletePass(config, pass_name);
// 根据 Config 创建 Predictor
PD_Predictor* predictor = PD_NewPredictor(config);
运行结果示例:
# PD_SwitchIrOptim 开启 IR 优化后,运行中会有如下 LOG 输出
--- Running analysis [ir_graph_build_pass]
--- Running analysis [ir_graph_clean_pass]
--- Running analysis [ir_analysis_pass]
--- Running IR pass [simplify_with_basic_ops_pass]
--- Running IR pass [attention_lstm_fuse_pass]
--- Running IR pass [seqconv_eltadd_relu_fuse_pass]
...
--- Running analysis [inference_op_replace_pass]
--- Running analysis [ir_graph_to_program_pass]
# PD_SwitchIrDebug 开启 IR 打印后,运行结束之后会在目录下生成如下 DOT 文件
-rw-r--r-- 1 root root 70K Nov 17 10:47 0_ir_simplify_with_basic_ops_pass.dot
-rw-r--r-- 1 root root 72K Nov 17 10:47 10_ir_fc_gru_fuse_pass.dot
-rw-r--r-- 1 root root 72K Nov 17 10:47 11_ir_graph_viz_pass.dot
...
-rw-r--r-- 1 root root 72K Nov 17 10:47 8_ir_mul_lstm_fuse_pass.dot
-rw-r--r-- 1 root root 72K Nov 17 10:47 9_ir_graph_viz_pass.dot
启用内存优化¶
API定义如下:
// 开启内存/显存复用,具体降低内存效果取决于模型结构
// 参数:config - AnalysisConfig 对象指针
// 返回:None
void PD_EnableMemoryOptim(PD_AnalysisConfig* config);
// 判断是否开启内存/显存复用
// 参数:config - AnalysisConfig 对象指针
// 返回:bool - 是否开启内/显存复用
bool PD_MemoryOptimEnabled(const PD_AnalysisConfig* config);
代码示例:
// 创建 AnalysisConfig 对象
PD_AnalysisConfig* config = PD_NewAnalysisConfig();
// 开启 CPU 内存优化
PD_EnableMemoryOptim(config);
// 通过 API 获取 CPU 是否已经开启显存优化 - true
printf("CPU Mem Optim is: %s\n", PD_MemoryOptimEnabled(config) ? "True" : "False");
// 启用 GPU 进行预测 - 初始化 GPU 显存 100M, Deivce_ID 为 0
PD_EnableUseGpu(config, 100, 0);
// 开启 GPU 显存优化
PD_EnableMemoryOptim(config);
// 通过 API 获取 GPU 是否已经开启显存优化 - true
printf("GPU Mem Optim is: %s\n", PD_MemoryOptimEnabled(config) ? "True" : "False");
设置缓存路径¶
注意: 如果当前使用的为 TensorRT INT8 且设置从内存中加载模型,则必须通过 SetOptimCacheDir 来设置缓存路径。
API定义如下:
// 设置缓存路径
// 参数:config - AnalysisConfig 对象指针
// opt_cache_dir - 缓存路径
// 返回:None
void PD_SetOptimCacheDir(PD_AnalysisConfig* config, const char* opt_cache_dir);
代码示例:
// 创建 AnalysisConfig 对象
PD_AnalysisConfig* config = PD_NewAnalysisConfig();
// 设置缓存路径
const char * opt_cache_dir = "./mobilenet_v1/OptimCacheDir";
PD_SetOptimCacheDir(config, opt_cache_dir);
Profile 设置¶
API定义如下:
// 打开 Profile,运行结束后会打印所有 OP 的耗时占比。
// 参数:config - AnalysisConfig 对象指针
// 返回:None
void PD_EnableProfile(PD_AnalysisConfig* config);
// 判断是否开启 Profile
// 参数:config - AnalysisConfig 对象指针
// 返回:bool - 是否开启 Profile
bool PD_ProfileEnabled(const PD_AnalysisConfig* config);
代码示例:
// 创建 AnalysisConfig 对象
PD_AnalysisConfig* config = PD_NewAnalysisConfig();
// 打开 Profile
PD_EnableProfile(config);
// 判断是否开启 Profile - true
printf("Profile is: %s\n", PD_ProfileEnabled(config) ? "True" : "False");
执行预测之后输出的 Profile 的结果如下:
-------------------------> Profiling Report <-------------------------
Place: CPU
Time unit: ms
Sorted by total time in descending order in the same thread
------------------------- Overhead Summary -------------------------
Total time: 1085.33
Computation time Total: 1066.24 Ratio: 98.2411%
Framework overhead Total: 19.0902 Ratio: 1.75893%
------------------------- GpuMemCpy Summary -------------------------
GpuMemcpy Calls: 0 Total: 0 Ratio: 0%
------------------------- Event Summary -------------------------
Event Calls Total Min. Max. Ave. Ratio.
thread0::conv2d 210 319.734 0.815591 6.51648 1.52254 0.294595
thread0::load 137 284.596 0.114216 258.715 2.07735 0.26222
thread0::depthwise_conv2d 195 266.241 0.955945 2.47858 1.36534 0.245308
thread0::elementwise_add 210 122.969 0.133106 2.15806 0.585568 0.113301
thread0::relu 405 56.1807 0.021081 0.585079 0.138718 0.0517635
thread0::batch_norm 195 25.8073 0.044304 0.33896 0.132345 0.0237783
thread0::fc 15 7.13856 0.451674 0.714895 0.475904 0.0065773
thread0::pool2d 15 1.48296 0.09054 0.145702 0.0988637 0.00136636
thread0::softmax 15 0.941837 0.032175 0.460156 0.0627891 0.000867786
thread0::scale 15 0.240771 0.013394 0.030727 0.0160514 0.000221841
Log 设置¶
API定义如下:
// 去除 Paddle Inference 运行中的 LOG
// 参数:config - AnalysisConfig 对象指针
// 返回:None
void PD_DisableGlogInfo(PD_AnalysisConfig* config);
代码示例:
// 创建 AnalysisConfig 对象
PD_AnalysisConfig* config = PD_NewAnalysisConfig();
// 去除 Paddle Inference 运行中的 LOG
PD_DisableGlogInfo(config);
Predictor 方法¶
Paddle Inference 的预测器,由 PD_NewPredictor 根据 AnalysisConfig 进行创建。用户可以根据 Predictor 提供的接口设置输入数据、执行模型预测、获取输出等。
创建 Predictor¶
API定义如下:
// 根据 Config 构建预测执行对象 Predictor
// 参数: config - 用于构建 Predictor 的配置信息
// 返回: PD_Predictor* - 预测对象指针
PD_Predictor* PD_NewPredictor(const PD_AnalysisConfig* config);
// 删除 Predictor 对象
// predictor - Predictor 对象指针
// 返回:None
void PD_DeletePredictor(PD_Predictor* predictor);
代码示例:
// 创建 AnalysisConfig 对象
PD_AnalysisConfig* config = PD_NewAnalysisConfig();
// 设置预测模型路径,这里为非 Combined 模型
const char* model_dir = "./mobilenet_v1";
PD_SetModel(config, model_dir, NULL);
// 根据 Config 创建 Predictor
PD_Predictor* predictor = PD_NewPredictor(config);
获取输入输出¶
API 定义如下:
// 获取模型输入 Tensor 的数量
// 参数:predictor - PD_Predictor 对象指针
// 返回:int - 模型输入 Tensor 的数量
int PD_GetInputNum(const PD_Predictor*);
// 获取模型输出 Tensor 的数量
// 参数:predictor - PD_Predictor 对象指针
// 返回:int - 模型输出 Tensor 的数量
int PD_GetOutputNum(const PD_Predictor*);
// 获取输入 Tensor 名称
// 参数:predictor - PD_Predictor 对象指针
// int - 输入 Tensor 的index
// 返回:const char* - 输入 Tensor 名称
const char* PD_GetInputName(const PD_Predictor*, int);
// 获取输出 Tensor 名称
// 参数:predictor - PD_Predictor 对象指针
// int - 输出 Tensor 的index
// 返回:const char* - 输出 Tensor 名称
const char* PD_GetOutputName(const PD_Predictor*, int);
代码示例:
// 创建 AnalysisConfig 对象
PD_AnalysisConfig* config = PD_NewAnalysisConfig();
// 设置预测模型路径,这里为非 Combined 模型
const char* model_dir = "./mobilenet_v1";
PD_SetModel(config, model_dir, NULL);
// 根据 Config 创建 Predictor
PD_Predictor* predictor = PD_NewPredictor(config);
// 获取输入 Tensor 的数量
int input_num = PD_GetInputNum(predictor);
printf("Input tensor number is: %d\n", input_num);
// 获取第 0 个输入 Tensor的名称
const char * input_name = PD_GetInputName(predictor, 0);
printf("Input tensor name is: %s\n", input_name);
// 获取输出 Tensor 的数量
int output_num = PD_GetOutputNum(predictor);
printf("Output tensor number is: %d\n", output_num);
// 获取第 0 个输出 Tensor的名称
const char * output_name = PD_GetOutputName(predictor, 0);
printf("Output tensor name is: %s\n", output_name);
执行预测¶
API 定义如下:
// 执行模型预测,需要在设置输入数据后调用
// 参数:config - 用于构建 Predictor 的配置信息
// inputs - 输入 Tensor 的数组指针
// in_size - 输入 Tensor 的数组中包含的输入 Tensor 的数量
// output_data - (可修改参数) 返回输出 Tensor 的数组指针
// out_size - (可修改参数) 返回输出 Tensor 的数组中包含的输出 Tensor 的数量
// batch_size - 输入的 batch_size
// 返回:bool - 执行预测是否成功
bool PD_PredictorRun(const PD_AnalysisConfig* config,
PD_Tensor* inputs, int in_size,
PD_Tensor** output_data,
int* out_size, int batch_size);
代码示例:
// 创建 AnalysisConfig 对象
PD_AnalysisConfig* config = PD_NewAnalysisConfig();
// 设置预测模型路径,这里为非 Combined 模型
const char* model_dir = "./mobilenet_v1";
PD_SetModel(config, model_dir, NULL);
// 创建输入 Tensor
PD_Tensor* input_tensor = PD_NewPaddleTensor();
// 创建输入 Buffer
PD_PaddleBuf* input_buffer = PD_NewPaddleBuf();
printf("PaddleBuf empty: %s\n", PD_PaddleBufEmpty(input_buffer) ? "True" : "False");
int batch = 1;
int channel = 3;
int height = 224;
int width = 224;
int input_shape[4] = {batch, channel, height, width};
int input_size = batch * channel * height * width;
int shape_size = 4;
float* input_data = malloc(sizeof(float) * input_size);
int i = 0;
for (i = 0; i < input_size ; i++){
input_data[i] = 1.0f;
}
PD_PaddleBufReset(input_buffer, (void*)(input_data), sizeof(float) * input_size);
// 设置输入 Tensor 信息
char name[6] = {'i', 'm', 'a', 'g', 'e', '\0'};
PD_SetPaddleTensorName(input_tensor, name);
PD_SetPaddleTensorDType(input_tensor, PD_FLOAT32);
PD_SetPaddleTensorShape(input_tensor, input_shape, shape_size);
PD_SetPaddleTensorData(input_tensor, input_buffer);
// 设置输出 Tensor 和 数量
PD_Tensor* output_tensor = PD_NewPaddleTensor();
int output_size;
// 执行预测
PD_PredictorRun(config, input_tensor, 1, &output_tensor, &output_size, 1);
// 获取预测输出 Tensor 信息
printf("Output Tensor Size: %d\n", output_size);
printf("Output Tensor Name: %s\n", PD_GetPaddleTensorName(output_tensor));
printf("Output Tensor Dtype: %d\n", PD_GetPaddleTensorDType(output_tensor));
// 获取预测输出 Tensor 数据
PD_PaddleBuf* output_buffer = PD_GetPaddleTensorData(output_tensor);
float* result = (float*)(PD_PaddleBufData(output_buffer));
int result_length = PD_PaddleBufLength(output_buffer) / sizeof(float);
printf("Output Data Length: %d\n", result_length);
// 删除输入 Tensor 和 Buffer
PD_DeletePaddleTensor(input_tensor);
PD_DeletePaddleBuf(input_buffer);
// 删除 Config
PD_DeleteAnalysisConfig(config);
PaddleTensor 方法¶
PaddleTensor 是 Paddle Inference 的数据组织形式,用于对底层数据进行封装并提供接口对数据进行操作,包括设置 Shape、数据、LoD 信息等。
创建 PaddleTensor 对象¶
// 创建 PaddleTensor 对象
// 参数:None
// 返回:PD_Tensor* - PaddleTensor 对象指针
PD_Tensor* PD_NewPaddleTensor();
// 删除 PaddleTensor 对象
// 参数:tensor - PaddleTensor 对象指针
// 返回:None
void PD_DeletePaddleTensor(PD_Tensor* tensor);
代码示例:
// 创建 PaddleTensor 对象
PD_Tensor* input = PD_NewPaddleTensor();
// 删除 PaddleTensor 对象
PD_DeletePaddleTensor(input);
输入输出 PaddleTensor¶
// 设置 PaddleTensor 名称
// 参数:tensor - PaddleTensor 对象指针
// name - PaddleTensor 名称
// 返回:None
void PD_SetPaddleTensorName(PD_Tensor* tensor, char* name);
// 设置 PaddleTensor 数据类型
// 参数:tensor - PaddleTensor 对象指针
// dtype - PaddleTensor 数据类型,DataType 类型
// 返回:None
void PD_SetPaddleTensorDType(PD_Tensor* tensor, PD_DataType dtype);
// 设置 PaddleTensor 数据
// 参数:tensor - PaddleTensor 对象指针
// buf - PaddleTensor 数据,PaddleBuf 类型指针
// 返回:None
void PD_SetPaddleTensorData(PD_Tensor* tensor, PD_PaddleBuf* buf);
// 设置 PaddleTensor 的维度信息
// 参数:tensor - PaddleTensor 对象指针
// shape - 包含维度信息的int数组指针
// size - 包含维度信息的int数组长度
// 返回:None
void PD_SetPaddleTensorShape(PD_Tensor* tensor, int* shape, int size);
// 获取 PaddleTensor 名称
// 参数:tensor - PaddleTensor 对象指针
// 返回:const char * - PaddleTensor 名称
const char* PD_GetPaddleTensorName(const PD_Tensor* tensor);
// 获取 PaddleTensor 数据类型
// 参数:tensor - PaddleTensor 对象指针
// 返回:PD_DataType- PaddleTensor 数据类型
PD_DataType PD_GetPaddleTensorDType(const PD_Tensor* tensor);
// 获取 PaddleTensor 数据
// 参数:tensor - PaddleTensor 对象指针
// 返回:PD_PaddleBuf * - PaddleTensor 数据
PD_PaddleBuf* PD_GetPaddleTensorData(const PD_Tensor* tensor);
// 获取 PaddleTensor 唯独信息
// 参数:tensor - PaddleTensor 对象指针
// size - (可修改参数) 返回包含 PaddleTensor 维度信息的int数组长度
// 返回:const int* - 包含 PaddleTensor 维度信息的int数组指针Tensor
const int* PD_GetPaddleTensorShape(const PD_Tensor* tensor, int* size);
代码示例:
// 创建 AnalysisConfig 对象
PD_AnalysisConfig* config = PD_NewAnalysisConfig();
// 设置预测模型路径,这里为非 Combined 模型
const char* model_dir = "./mobilenet_v1";
PD_SetModel(config, model_dir, NULL);
// 创建输入 PaddleTensor
PD_Tensor* input_tensor = PD_NewPaddleTensor();
// 创建输入 Buffer
PD_PaddleBuf* input_buffer = PD_NewPaddleBuf();
printf("PaddleBuf empty: %s\n", PD_PaddleBufEmpty(input_buffer) ? "True" : "False");
int batch = 1;
int channel = 3;
int height = 224;
int width = 224;
int input_shape[4] = {batch, channel, height, width};
int input_size = batch * channel * height * width;
int shape_size = 4;
float* input_data = malloc(sizeof(float) * input_size);
int i = 0;
for (i = 0; i < input_size ; i++){
input_data[i] = 1.0f;
}
PD_PaddleBufReset(input_buffer, (void*)(input_data), sizeof(float) * input_size);
// 设置输入 PaddleTensor 信息
char name[6] = {'i', 'm', 'a', 'g', 'e', '\0'};
PD_SetPaddleTensorName(input_tensor, name);
PD_SetPaddleTensorDType(input_tensor, PD_FLOAT32);
PD_SetPaddleTensorShape(input_tensor, input_shape, shape_size);
PD_SetPaddleTensorData(input_tensor, input_buffer);
// 设置输出 PaddleTensor 和 数量
PD_Tensor* output_tensor = PD_NewPaddleTensor();
int output_size;
// 执行预测
PD_PredictorRun(config, input_tensor, 1, &output_tensor, &output_size, 1);
// 获取预测输出 PaddleTensor 信息
printf("Output PaddleTensor Size: %d\n", output_size);
printf("Output PaddleTensor Name: %s\n", PD_GetPaddleTensorName(output_tensor));
printf("Output PaddleTensor Dtype: %d\n", PD_GetPaddleTensorDType(output_tensor));
// 获取预测输出 PaddleTensor 数据
PD_PaddleBuf* output_buffer = PD_GetPaddleTensorData(output_tensor);
float* result = (float*)(PD_PaddleBufData(output_buffer));
int result_length = PD_PaddleBufLength(output_buffer) / sizeof(float);
printf("Output Data Length: %d\n", result_length);
// 删除输入 PaddleTensor 和 Buffer
PD_DeletePaddleTensor(input_tensor);
PD_DeletePaddleBuf(input_buffer);
// 删除 Config
PD_DeleteAnalysisConfig(config);
PaddleBuf 方法¶
PaddleBuf 用于设置 PaddleTensor 的数据信息,主要用于对输入 Tensor 中的数据进行赋值。
创建 PaddleBuf 对象¶
// 创建 PaddleBuf 对象
// 参数:None
// 返回:PD_PaddleBuf* - PaddleBuf 对象指针
PD_PaddleBuf* PD_NewPaddleBuf();
// 删除 PaddleBuf 对象
// 参数:buf - PaddleBuf 对象指针
// 返回:None
void PD_DeletePaddleBuf(PD_PaddleBuf* buf);
代码示例:
// 创建 PaddleBuf 对象
PD_PaddleBuf* input_buffer = PD_NewPaddleBuf();
// 删除 PaddleBuf 对象
PD_DeletePaddleBuf(input_buffer);
设置 PaddleBuf 对象¶
// 设置 PaddleBuf 的大小
// 参数:buf - PaddleBuf 对象指针
// length - 需要设置的大小
// 返回:None
void PD_PaddleBufResize(PD_PaddleBuf* buf, size_t length);
// 重置 PaddleBuf 包含的数据和大小
// 参数:buf - PaddleBuf 对象指针
// data - 需要设置的数据
// length - 需要设置的大小
// 返回:None
void PD_PaddleBufReset(PD_PaddleBuf* buf, void* data, size_t length);
// 判断 PaddleBuf 是否为空
// 参数:buf - PaddleBuf 对象指针
// 返回:bool - PaddleBuf 是否为空
bool PD_PaddleBufEmpty(PD_PaddleBuf* buf);
// 获取 PaddleBuf 中的数据
// 参数:buf - PaddleBuf 对象指针
// 返回:void* - PaddleBuf 中的数据指针
void* PD_PaddleBufData(PD_PaddleBuf* buf);
// 获取 PaddleBuf 中的数据大小
// 参数:buf - PaddleBuf 对象指针
// 返回:size_t - PaddleBuf 中的数据大小
size_t PD_PaddleBufLength(PD_PaddleBuf* buf);
代码示例:
// 创建 PaddleBuf
PD_PaddleBuf* input_buffer = PD_NewPaddleBuf();
// 判断 PaddleBuf 是否为空 - True
printf("PaddleBuf empty: %s\n", PD_PaddleBufEmpty(input_buffer) ? "True" : "False");
int input_size = 10;
float* input_data = malloc(sizeof(float) * input_size);
int i = 0;
for (i = 0; i < input_size ; i++){
input_data[i] = 1.0f;
}
// 重置 PaddleBuf 包含的数据和大小
PD_PaddleBufReset(input_buffer, (void*)(input_data), sizeof(float) * input_size);
// 获取 PaddleBuf 的大小 - 4 * 10
printf("PaddleBuf size is: %ld\n", PD_PaddleBufLength(input_buffer));
枚举类型¶
DataType¶
DataType为模型中Tensor的数据精度,默认值为 FLOAT32。枚举变量与 API 定义如下:
// DataType 枚举类型定义
enum PD_DataType { PD_FLOAT32, PD_INT32, PD_INT64, PD_UINT8, PD_UNKDTYPE };
代码示例:
// 创建 FLOAT32 类型 DataType
PD_DataType data_type = PD_FLOAT32;
// 创建输入 Tensor
PD_Tensor* input_tensor = PD_NewPaddleTensor();
// 设置输入 Tensor 的数据类型
PD_SetPaddleTensorDType(input_tensor, PD_FLOAT32);
// 获取 Tensor 的数据类型
printf("Tensor Dtype: %d\n", PD_GetPaddleTensorDType(input_tensor));
Precision¶
Precision 设置模型的运行精度,默认值为 kFloat32(float32)。枚举变量定义如下:
// PrecisionType 枚举类型定义
enum Precision { kFloat32 = 0, kInt8, kHalf };
代码示例:
// 创建 AnalysisConfig 对象
PD_AnalysisConfig* config = PD_NewAnalysisConfig();
// 启用 GPU 进行预测 - 初始化 GPU 显存 100M, Deivce_ID 为 0
PD_EnableUseGpu(config, 100, 0);
// 启用 TensorRT 进行预测加速 - FP32
PD_EnableTensorRtEngine(config, 1 << 20, 1, 3, kFloat32, false, false);
// 启用 TensorRT 进行预测加速 - FP16
PD_EnableTensorRtEngine(config, 1 << 20, 1, 3, kHalf, false, false);
// 启用 TensorRT 进行预测加速 - Int8
PD_EnableTensorRtEngine(config, 1 << 20, 1, 3, kInt8, false, false);
GO API 文档¶
AnalysisConfig 方法¶
创建 AnalysisConfig¶
AnalysisConfig 对象相关方法用于创建预测相关配置,构建 Predictor 对象的配置信息,如模型路径、是否开启gpu等等。
相关方法定义如下:
// 创建 AnalysisConfig 对象
// 参数:None
// 返回:*AnalysisConfig - AnalysisConfig 对象指针
func NewAnalysisConfig() *AnalysisConfig
// 设置 AnalysisConfig 为无效状态,保证每一个 AnalysisConfig 仅用来初始化一次 Predictor
// 参数:config - *AnalysisConfig 对象指针
// 返回:None
func (config *AnalysisConfig) SetInValid()
// 判断当前 AnalysisConfig 是否有效
// 参数:config - *AnalysisConfig 对象指针
// 返回:bool - 当前 AnalysisConfig 是否有效
func (config *AnalysisConfig) IsValid() bool
代码示例:
package main
// 引入 Paddle Golang Package
import "/pathto/Paddle/go/paddle"
func main() {
// 创建 AnalysisConfig 对象
config := paddle.NewAnalysisConfig()
// 判断当前 Config 是否有效 - true
println("Config validation is: ", config.IsValid())
// 设置 Config 为无效状态
config.SetInValid();
// 判断当前 Config 是否有效 - false
println("Config validation is: ", config.IsValid())
}
设置预测模型¶
从文件中加载预测模型 - 非Combined模型¶
API定义如下:
// 设置模型文件路径
// 参数:config - *AnalysisConfig 对象指针
// model - 模型文件夹路径
// params - "", 当输入模型为非 Combined 模型时,该参数为空字符串
// 返回:None
func (config *AnalysisConfig) SetModel(model, params string)
// 获取非combine模型的文件夹路径
// 参数:config - *AnalysisConfig 对象指针
// 返回:string - 模型文件夹路径
func (config *AnalysisConfig) ModelDir() string
代码示例:
package main
// 引入 Paddle Golang Package
import "/pathto/Paddle/go/paddle"
func main() {
// 创建 AnalysisConfig 对象
config := paddle.NewAnalysisConfig()
// 设置预测模型路径,这里为非 Combined 模型
config.SetModel("data/mobilenet_v1", "")
// 输出模型路径
println("Non-combined model dir is: ", config.ModelDir())
}
从文件中加载预测模型 - Combined 模型¶
API定义如下:
// 设置模型文件路径
// 参数:config - *AnalysisConfig 对象指针
// model_dir - Combined 模型文件所在路径
// params_path - Combined 模型参数文件所在路径
// 返回:None
func (config *AnalysisConfig) SetModel(model, params string)
// 获取 Combined 模型的模型文件路径
// 参数:config - *AnalysisConfig 对象指针
// 返回:string - 模型文件路径
func (config *AnalysisConfig) ProgFile() string
// 获取 Combined 模型的参数文件路径
// 参数:config - *AnalysisConfig 对象指针
// 返回:string - 参数文件路径
func (config *AnalysisConfig) ParamsFile() string
代码示例:
package main
// 引入 Paddle Golang Package
import "/pathto/Paddle/go/paddle"
func main() {
// 创建 AnalysisConfig 对象
config := paddle.NewAnalysisConfig()
// 设置预测模型路径,这里为 Combined 模型
config.SetModel("data/model/__model__", "data/model/__params__")
// 输出模型路径
println("Combined model path is: ", config.ProgFile())
println("Combined param path is: ", config.ParamsFile())
}
使用 CPU 进行预测¶
注意:
在 CPU 型号允许的情况下,进行预测库下载或编译试尽量使用带 AVX 和 MKL 的版本
可以尝试使用 Intel 的 MKLDNN 进行 CPU 预测加速,默认 CPU 不启用 MKLDNN
在 CPU 可用核心数足够时,可以通过设置
SetCpuMathLibraryNumThreads将线程数调高一些,默认线程数为 1
CPU 设置¶
API定义如下:
// 设置 CPU Blas 库计算线程数
// 参数:config - AnalysisConfig 对象指针
// n - blas库计算线程数
// 返回:None
func (config *AnalysisConfig) SetCpuMathLibraryNumThreads(n int)
// 获取 CPU Blas 库计算线程数
// 参数:config - AnalysisConfig 对象指针
// 返回:int - cpu blas 库计算线程数
func (config *AnalysisConfig) CpuMathLibraryNumThreads() int
代码示例:
package main
// 引入 Paddle Golang Package
import "/pathto/Paddle/go/paddle"
func main() {
// 创建 AnalysisConfig 对象
config := paddle.NewAnalysisConfig()
// 设置预测模型路径,这里为非 Combined 模型
config.SetCpuMathLibraryNumThreads(10)
// 输出模型路径
println("CPU Math Lib Thread Num is: ", config.CpuMathLibraryNumThreads())
}
MKLDNN 设置¶
注意:
启用 MKLDNN 的前提为已经使用 CPU 进行预测,否则启用 MKLDNN 无法生效
启用 MKLDNN BF16 要求 CPU 型号可以支持 AVX512,否则无法启用 MKLDNN BF16
API定义如下:
// 启用 MKLDNN 进行预测加速
// 参数:config - AnalysisConfig 对象指针
// 返回:None
func (config *AnalysisConfig) EnableMkldnn()
// 判断是否启用 MKLDNN
// 参数:config - AnalysisConfig 对象指针
// 返回:bool - 是否启用 MKLDNN
func (config *AnalysisConfig) MkldnnEnabled() bool
// 启用 MKLDNN BFLOAT16
// 参数:config - AnalysisConfig 对象指针
// 返回:None
func (config *AnalysisConfig) EnableMkldnnBfloat16()
// 判断是否启用 MKLDNN BFLOAT16
// 参数:config - AnalysisConfig 对象指针
// 返回:bool - 是否启用 MKLDNN BFLOAT16
func (config *AnalysisConfig) MkldnnBfloat16Enabled() bool
代码示例:
package main
// 引入 Paddle Golang Package
import "/pathto/Paddle/go/paddle"
func main() {
// 创建 AnalysisConfig 对象
config := paddle.NewAnalysisConfig()
// 启用 MKLDNN 进行预测
config.EnableMkldnn()
// 通过 API 获取 MKLDNN 启用结果 - true
println("Enable MKLDNN is: ", config.MkldnnEnabled())
// 启用 MKLDNN BFLOAT16 进行预测
config.EnableMkldnnBfloat16()
// 通过 API 获取 MKLDNN BFLOAT16 启用结果
// 如果当前CPU支持AVX512,则返回 true, 否则返回 false
println("Enable MKLDNN BF16 is: ", config.MkldnnBfloat16Enabled())
}
使用 GPU 进行预测¶
注意:
AnalysisConfig 默认使用 CPU 进行预测,需要通过
EnableUseGpu来启用 GPU 预测可以尝试启用 CUDNN 和 TensorRT 进行 GPU 预测加速
GPU 设置¶
API定义如下:
// 启用 GPU 进行预测
// 参数:config - AnalysisConfig 对象指针
// memory_pool_init_size_mb - 初始化分配的gpu显存,以MB为单位
// device_id - 设备id
// 返回:None
func (config *AnalysisConfig) EnableUseGpu(memory_pool_init_size_mb int, device_id int)
// 禁用 GPU 进行预测
// 参数:config - AnalysisConfig 对象指针
// 返回:None
func (config *AnalysisConfig) DisableGpu()
// 判断是否启用 GPU
// 参数:config - AnalysisConfig 对象指针
// 返回:bool - 是否启用 GPU
func (config *AnalysisConfig) UseGpu() bool
// 获取 GPU 的device id
// 参数:config - AnalysisConfig 对象指针
// 返回:int - GPU 的device id
func (config *AnalysisConfig) GpuDeviceId() int
// 获取 GPU 的初始显存大小
// 参数:config - AnalysisConfig 对象指针
// 返回:int - GPU 的初始的显存大小
func (config *AnalysisConfig) MemoryPoolInitSizeMb() int
// 初始化显存占总显存的百分比
// 参数:config - AnalysisConfig 对象指针
// 返回:float - 初始的显存占总显存的百分比
func (config *AnalysisConfig) FractionOfGpuMemoryForPool() float32
GPU设置代码示例:
package main
// 引入 Paddle Golang Package
import "/pathto/Paddle/go/paddle"
func main() {
// 创建 AnalysisConfig 对象
config := paddle.NewAnalysisConfig()
// 启用 GPU 进行预测 - 初始化 GPU 显存 100M, Deivce_ID 为 0
config.EnableUseGpu(100, 0)
// 通过 API 获取 GPU 信息
println("Use GPU is: ", config.UseGpu()) // True
println("GPU deivce id is: ", config.GpuDeviceId())
println("GPU memory size is: ", config.MemoryPoolInitSizeMb())
println("GPU memory frac is: ", config.FractionOfGpuMemoryForPool())
// 禁用 GPU 进行预测
config.DisableGpu()
// 通过 API 获取 GPU 信息 - False
println("Use GPU is: ", config.UseGpu())
}
CUDNN 设置¶
注意: 启用 CUDNN 的前提为已经启用 GPU,否则启用 CUDNN 无法生效。
API定义如下:
// 启用 CUDNN 进行预测加速
// 参数:config - AnalysisConfig 对象指针
// 返回:None
func (config *AnalysisConfig) EnableCudnn()
// 判断是否启用 CUDNN
// 参数:config - AnalysisConfig 对象指针
// 返回:bool - 是否启用 CUDNN
func (config *AnalysisConfig) CudnnEnabled() bool
代码示例:
package main
// 引入 Paddle Golang Package
import "/pathto/Paddle/go/paddle"
func main() {
// 创建 AnalysisConfig 对象
config := paddle.NewAnalysisConfig()
// 启用 GPU 进行预测 - 初始化 GPU 显存 100M, Deivce_ID 为 0
config.EnableUseGpu(100, 0)
// 启用 CUDNN 进行预测加速
config.EnableCudnn()
// 通过 API 获取 CUDNN 启用结果 - True
println("Enable CUDNN is: ", config.CudnnEnabled())
// 禁用 GPU 进行预测
config.DisableGpu()
// 启用 CUDNN 进行预测加速 - 因为 GPU 被禁用,因此 CUDNN 启用不生效
config.EnableCudnn()
// 通过 API 获取 CUDNN 启用结果 - False
println("Enable CUDNN is: ", config.CudnnEnabled())
}
TensorRT 设置¶
注意: 启用 TensorRT 的前提为已经启用 GPU,否则启用 TensorRT 无法生效
更多 TensorRT 详细信息,请参考 使用Paddle-TensorRT库预测。
API定义如下:
// 启用 TensorRT 进行预测加速
// 参数:config - AnalysisConfig 对象指针
// workspace_size - 指定 TensorRT 使用的工作空间大小
// max_batch_size - 设置最大的 batch 大小,运行时 batch 大小不得超过此限定值
// min_subgraph_size - Paddle-TRT 是以子图的形式运行,为了避免性能损失,当子图内部节点个数
// 大于 min_subgraph_size 的时候,才会使用 Paddle-TRT 运行
// precision - 指定使用 TRT 的精度,支持 FP32(kFloat32),FP16(kHalf),Int8(kInt8)
// use_static - 若指定为 true,在初次运行程序的时候会将 TRT 的优化信息进行序列化到磁盘上,
// 下次运行时直接加载优化的序列化信息而不需要重新生成
// use_calib_mode - 若要运行 Paddle-TRT INT8 离线量化校准,需要将此选项设置为 true
// 返回:None
func (config *AnalysisConfig) EnableTensorRtEngine(workspace_size int, max_batch_size int,
min_subgraph_size int, precision Precision,
use_static bool, use_calib_mode bool)
// 判断是否启用 TensorRT
// 参数:config - AnalysisConfig 对象指针
// 返回:bool - 是否启用 TensorRT
func (config *AnalysisConfig) TensorrtEngineEnabled() bool
代码示例:使用 TensorRT FP32 / FP16 / INT8 进行预测
package main
// 引入 Paddle Golang Package
import "/pathto/Paddle/go/paddle"
func main() {
// 创建 AnalysisConfig 对象
config := paddle.NewAnalysisConfig()
// 启用 GPU 进行预测 - 初始化 GPU 显存 100M, Deivce_ID 为 0
config.EnableUseGpu(100, 0)
// 启用 TensorRT 进行预测加速 - FP32
config.EnableTensorRtEngine(1 << 20, 1, 3, paddle.Precision_FLOAT32, false, false)
// 启用 TensorRT 进行预测加速 - FP16
config.EnableTensorRtEngine(1 << 20, 1, 3, paddle.Precision_HALF, false, false)
// 启用 TensorRT 进行预测加速 - Int8
config.EnableTensorRtEngine(1 << 20, 1, 3, paddle.Precision_INT8, false, false)
// 通过 API 获取 TensorRT 启用结果 - true
println("Enable TensorRT is: ", config.TensorrtEngineEnabled())
}
设置模型优化方法¶
API定义如下:
// 启用 IR 优化
// 参数:config - AnalysisConfig 对象指针
// x - 是否开启 IR 优化,默认打开
// 返回:None
func (config *AnalysisConfig) SwitchIrOptim(x bool)
// 判断是否开启 IR 优化
// 参数:config - AnalysisConfig 对象指针
// 返回:bool - 是否开启 IR 优化
func (config *AnalysisConfig) IrOptim() bool
// 设置是否在图分析阶段打印 IR,启用后会在每一个 PASS 后生成 dot 文件
// 参数:config - AnalysisConfig 对象指针
// x - 是否打印 IR,默认关闭
// 返回:None
func (config *AnalysisConfig) SwitchIrDebug(x bool)
// 返回 pass_builder,用来自定义图分析阶段选择的 IR
// 参数:config - AnalysisConfig 对象指针
// pass - 需要删除的 pass 名称
// 返回:None
func (config *AnalysisConfig) DeletePass(pass string)
代码示例:
package main
// 引入 Paddle Golang Package
import "/pathto/Paddle/go/paddle"
func main() {
// 创建 AnalysisConfig 对象
config := paddle.NewAnalysisConfig()
// 设置预测模型路径,这里为非 Combined 模型
config.SetModel("data/model/__model__", "data/model/__params__")
// 开启 IR 优化
config.SwitchIrOptim(true);
// 开启 IR 打印
config.SwitchIrDebug(true);
// 通过 API 获取 IR 优化是否开启 - true
println("IR Optim is: ", config.IrOptim())
// 通过 config 去除 fc_fuse_pass
config.DeletePass("fc_fuse_pass")
// 根据 Config 创建 Predictor
predictor := paddle.NewPredictor(config)
// 删除 Predictor
paddle.DeletePredictor(predictor)
}
运行结果示例:
# SwitchIrOptim 开启 IR 优化后,运行中会有如下 LOG 输出
--- Running analysis [ir_graph_build_pass]
--- Running analysis [ir_graph_clean_pass]
--- Running analysis [ir_analysis_pass]
--- Running IR pass [simplify_with_basic_ops_pass]
--- Running IR pass [attention_lstm_fuse_pass]
--- Running IR pass [seqconv_eltadd_relu_fuse_pass]
...
--- Running analysis [inference_op_replace_pass]
--- Running analysis [ir_graph_to_program_pass]
# SwitchIrDebug 开启 IR 打印后,运行结束之后会在目录下生成如下 DOT 文件
-rw-r--r-- 1 root root 70K Nov 17 10:47 0_ir_simplify_with_basic_ops_pass.dot
-rw-r--r-- 1 root root 72K Nov 17 10:47 10_ir_fc_gru_fuse_pass.dot
-rw-r--r-- 1 root root 72K Nov 17 10:47 11_ir_graph_viz_pass.dot
...
-rw-r--r-- 1 root root 72K Nov 17 10:47 8_ir_mul_lstm_fuse_pass.dot
-rw-r--r-- 1 root root 72K Nov 17 10:47 9_ir_graph_viz_pass.dot
启用内存优化¶
API定义如下:
// 开启内存/显存复用,具体降低内存效果取决于模型结构
// 参数:config - AnalysisConfig 对象指针
// 返回:None
func (config *AnalysisConfig) EnableMemoryOptim()
// 判断是否开启内存/显存复用
// 参数:config - AnalysisConfig 对象指针
// 返回:bool - 是否开启内/显存复用
func (config *AnalysisConfig) MemoryOptimEnabled() bool
代码示例:
package main
// 引入 Paddle Golang Package
import "/pathto/Paddle/go/paddle"
func main() {
// 创建 AnalysisConfig 对象
config := paddle.NewAnalysisConfig()
// 开启 CPU 内存优化
config.EnableMemoryOptim();
// 通过 API 获取 CPU 是否已经开启显存优化 - true
println("CPU Mem Optim is: ", config.MemoryOptimEnabled())
// 启用 GPU 进行预测
config.EnableUseGpu(100, 0)
// 开启 GPU 显存优化
config.EnableMemoryOptim();
// 通过 API 获取 GPU 是否已经开启显存优化 - true
println("GPU Mem Optim is: ", config.MemoryOptimEnabled())
}
Profile 设置¶
API定义如下:
// 打开 Profile,运行结束后会打印所有 OP 的耗时占比。
// 参数:config - AnalysisConfig 对象指针
// 返回:None
func (config *AnalysisConfig) EnableProfile()
// 判断是否开启 Profile
// 参数:config - AnalysisConfig 对象指针
// 返回:bool - 是否开启 Profile
func (config *AnalysisConfig) ProfileEnabled() bool
代码示例:
package main
// 引入 Paddle Golang Package
import "/pathto/Paddle/go/paddle"
func main() {
// 创建 AnalysisConfig 对象
config := paddle.NewAnalysisConfig()
// 打开 Profile
config.EnableProfile();
// 判断是否开启 Profile - true
println("Profile is: ", config.ProfileEnabled())
}
执行预测之后输出的 Profile 的结果如下:
-------------------------> Profiling Report <-------------------------
Place: CPU
Time unit: ms
Sorted by total time in descending order in the same thread
------------------------- Overhead Summary -------------------------
Total time: 1085.33
Computation time Total: 1066.24 Ratio: 98.2411%
Framework overhead Total: 19.0902 Ratio: 1.75893%
------------------------- GpuMemCpy Summary -------------------------
GpuMemcpy Calls: 0 Total: 0 Ratio: 0%
------------------------- Event Summary -------------------------
Event Calls Total Min. Max. Ave. Ratio.
thread0::conv2d 210 319.734 0.815591 6.51648 1.52254 0.294595
thread0::load 137 284.596 0.114216 258.715 2.07735 0.26222
thread0::depthwise_conv2d 195 266.241 0.955945 2.47858 1.36534 0.245308
thread0::elementwise_add 210 122.969 0.133106 2.15806 0.585568 0.113301
thread0::relu 405 56.1807 0.021081 0.585079 0.138718 0.0517635
thread0::batch_norm 195 25.8073 0.044304 0.33896 0.132345 0.0237783
thread0::fc 15 7.13856 0.451674 0.714895 0.475904 0.0065773
thread0::pool2d 15 1.48296 0.09054 0.145702 0.0988637 0.00136636
thread0::softmax 15 0.941837 0.032175 0.460156 0.0627891 0.000867786
thread0::scale 15 0.240771 0.013394 0.030727 0.0160514 0.000221841
Log 设置¶
API定义如下:
// 去除 Paddle Inference 运行中的 LOG
// 参数:config - AnalysisConfig 对象指针
// 返回:None
func (config *AnalysisConfig) DisableGlogInfo()
代码示例:
package main
// 引入 Paddle Golang Package
import "/pathto/Paddle/go/paddle"
func main() {
// 创建 AnalysisConfig 对象
config := paddle.NewAnalysisConfig()
// 去除 Paddle Inference 运行中的 LOG
config.DisableGlogInfo();
}
Predictor 方法¶
Paddle Inference 的预测器,由 NewPredictor 根据 AnalysisConfig 进行创建。用户可以根据 Predictor 提供的接口设置输入数据、执行模型预测、获取输出等。
创建 Predictor¶
API定义如下:
// 根据 Config 构建预测执行对象 Predictor
// 参数: config - 用于构建 Predictor 的配置信息
// 返回: *Predictor - 预测对象指针
func NewPredictor(config *AnalysisConfig) *Predictor
// 删除 Predictor 对象
// predictor - Predictor 对象指针
// 返回:None
func DeletePredictor(predictor *Predictor)
代码示例:
package main
// 引入 Paddle Golang Package
import "/pathto/Paddle/go/paddle"
func main() {
// 创建 AnalysisConfig 对象
config := paddle.NewAnalysisConfig()
// 设置预测模型路径,这里为非 Combined 模型
config.SetModel("data/mobilenet_v1", "")
// 根据 Config 构建预测执行对象 Predictor
predictor := paddle.NewPredictor(config)
// 删除 Predictor 对象
paddle.DeletePredictor(predictor)
}
输入输出与执行预测¶
API 定义如下:
// 获取模型输入 Tensor 的数量
// 参数:predictor - PD_Predictor 对象指针
// 返回:int - 模型输入 Tensor 的数量
func (predictor *Predictor) GetInputNum() int
// 获取模型输出 Tensor 的数量
// 参数:predictor - PD_Predictor 对象指针
// 返回:int - 模型输出 Tensor 的数量
func (predictor *Predictor) GetOutputNum() int
// 获取输入 Tensor 名称
// 参数:predictor - PD_Predictor 对象指针
// int - 输入 Tensor 的index
// 返回:string - 输入 Tensor 名称
func (predictor *Predictor) GetInputName(n int) string
// 获取输出 Tensor 名称
// 参数:predictor - PD_Predictor 对象指针
// int - 输出 Tensor 的index
// 返回:string - 输出 Tensor 名称
func (predictor *Predictor) GetOutputName(n int) string
// 获取输入 Tensor 指针
// 参数:predictor - PD_Predictor 对象指针
// 返回:*ZeroCopyTensor - 输入 Tensor 指针
func (predictor *Predictor) GetInputTensors() [](*ZeroCopyTensor)
// 获取输出 Tensor 指针
// 参数:predictor - PD_Predictor 对象指针
// 返回:*ZeroCopyTensor - 输出 Tensor 指针
func (predictor *Predictor) GetOutputTensors() [](*ZeroCopyTensor)
// 获取输入 Tensor 名称数组
// 参数:predictor - PD_Predictor 对象指针
// 返回:[]string - 输入 Tensor 名称数组
func (predictor *Predictor) GetInputNames() []string
// 获取输出 Tensor 名称数组
// 参数:predictor - PD_Predictor 对象指针
// 返回:[]string - 输出 Tensor 名称数组
func (predictor *Predictor) GetOutputNames() []string
// 设置输入 Tensor
// 参数:predictor - PD_Predictor 对象指针
// *ZeroCopyTensor - 输入 Tensor 指针
// 返回:None
func (predictor *Predictor) SetZeroCopyInput(tensor *ZeroCopyTensor)
// 获取输出 Tensor
// 参数:predictor - PD_Predictor 对象指针
// *ZeroCopyTensor - 输出 Tensor 指针
// 返回:None
func (predictor *Predictor) GetZeroCopyOutput(tensor *ZeroCopyTensor)
// 执行预测
// 参数:predictor - PD_Predictor 对象指针
// 返回:None
func (predictor *Predictor) ZeroCopyRun()
代码示例:
package main
// 引入 Paddle Golang Package
import "/pathto/Paddle/go/paddle"
import "reflect"
func main() {
// 创建 AnalysisConfig 对象
config := paddle.NewAnalysisConfig()
config.SwitchUseFeedFetchOps(false)
// 设置预测模型路径,这里为非 Combined 模型
config.SetModel("data/mobilenet_v1", "")
// config.SetModel("data/model/__model__", "data/model/__params__")
// 根据 Config 构建预测执行对象 Predictor
predictor := paddle.NewPredictor(config)
// 获取输入输出 Tensor 信息
println("input num: ", predictor.GetInputNum())
println("input name: ", predictor.GetInputNames()[0])
println("output num: ", predictor.GetOutputNum())
println("output name: ", predictor.GetInputNames()[0])
// 获取输入输出 Tensor 指针
input := predictor.GetInputTensors()[0]
output := predictor.GetOutputTensors()[0]
input_data := make([]float32, 1 * 3 * 224 * 224)
for i := 0; i < 1 * 3 * 224 * 224; i++ {
input_data[i] = 1.0
}
input.SetValue(input_data)
input.Reshape([]int32{1, 3, 224, 224})
// 设置输入 Tensor
predictor.SetZeroCopyInput(input)
// 执行预测
predictor.ZeroCopyRun()
// 获取输出 Tensor
predictor.GetZeroCopyOutput(output)
// 获取输出 Tensor 信息
output_val := output.Value()
value := reflect.ValueOf(output_val)
shape, dtype := paddle.ShapeAndTypeOf(value)
v := value.Interface().([][]float32)
println("Ouptut Shape is: ", shape[0], "x", shape[1])
println("Ouptut Dtype is: ", dtype)
println("Output Data is: ", v[0][0], v[0][1], v[0][2], v[0][3], v[0][4], "...")
// 删除 Predictor 对象
paddle.DeletePredictor(predictor)
}
ZeroCopyTensor 方法¶
ZeroCopyTensor 是 Paddle Inference 的数据组织形式,用于对底层数据进行封装并提供接口对数据进行操作,包括设置 Shape、数据、LoD 信息等。
注意: 应使用 Predictor 的 GetInputTensors 和 GetOutputTensors 接口获取输入输出 ZeroCopyTensor。
ZeroCopyTensor 的API定义如下:
// 获取 ZeroCopyTensor 维度信息
// 参数:tensor - ZeroCopyTensor 对象指针
// 返回:[]int32 - 包含 ZeroCopyTensor 维度信息的int数组
func (tensor *ZeroCopyTensor) Shape() []int32
// 设置 ZeroCopyTensor 维度信息
// 参数:tensor - ZeroCopyTensor 对象指针
// shape - 包含维度信息的int数组
// 返回:None
func (tensor *ZeroCopyTensor) Reshape(shape []int32)
// 获取 ZeroCopyTensor 名称
// 参数:tensor - ZeroCopyTensor 对象指针
// 返回:string - ZeroCopyTensor 名称
func (tensor *ZeroCopyTensor) Name() string
// 设置 ZeroCopyTensor 名称
// 参数:tensor - ZeroCopyTensor 对象指针
// name - ZeroCopyTensor 名称
// 返回:None
func (tensor *ZeroCopyTensor) Rename(name string)
// 获取 ZeroCopyTensor 数据类型
// 参数:tensor - ZeroCopyTensor 对象指针
// 返回:PaddleDType - ZeroCopyTensor 数据类型
func (tensor *ZeroCopyTensor) DataType() PaddleDType
// 设置 ZeroCopyTensor 数据
// 参数:tensor - ZeroCopyTensor 对象指针
// value - ZeroCopyTensor 数据
// 返回:None
func (tensor *ZeroCopyTensor) SetValue(value interface{})
// 获取 ZeroCopyTensor 数据
// 参数:tensor - ZeroCopyTensor 对象指针
// 返回:interface{} - ZeroCopyTensor 数据
func (tensor *ZeroCopyTensor) Value() interface{}
代码示例:
package main
// 引入 Paddle Golang Package
import "/pathto/Paddle/go/paddle"
import "reflect"
func main() {
// 创建 AnalysisConfig 对象
config := paddle.NewAnalysisConfig()
config.SwitchUseFeedFetchOps(false)
// 设置预测模型路径,这里为非 Combined 模型
config.SetModel("data/mobilenet_v1", "")
// config.SetModel("data/model/__model__", "data/model/__params__")
// 根据 Config 构建预测执行对象 Predictor
predictor := paddle.NewPredictor(config)
// 获取输入输出 Tensor 信息
println("input num: ", predictor.GetInputNum())
println("input name: ", predictor.GetInputNames()[0])
println("output num: ", predictor.GetOutputNum())
println("output name: ", predictor.GetInputNames()[0])
// 获取输入输出 Tensor 指针
input := predictor.GetInputTensors()[0]
output := predictor.GetOutputTensors()[0]
input_data := make([]float32, 1 * 3 * 224 * 224)
for i := 0; i < 1 * 3 * 224 * 224; i++ {
input_data[i] = 1.0
}
input.SetValue(input_data)
input.Reshape([]int32{1, 3, 224, 224})
// 设置输入 Tensor
predictor.SetZeroCopyInput(input)
// 执行预测
predictor.ZeroCopyRun()
// 获取输出 Tensor
predictor.GetZeroCopyOutput(output)
// 获取输出 Tensor 信息
output_val := output.Value()
value := reflect.ValueOf(output_val)
shape, dtype := paddle.ShapeAndTypeOf(value)
v := value.Interface().([][]float32)
println("Ouptut Shape is: ", shape[0], "x", shape[1])
println("Ouptut Dtype is: ", dtype)
println("Output Data is: ", v[0][0], v[0][1], v[0][2], v[0][3], v[0][4], "...")
// 删除 Predictor 对象
paddle.DeletePredictor(predictor)
}
枚举类型¶
DataType¶
DataType 为模型中 Tensor 的数据精度,默认值为 FLOAT32。枚举变量与 API 定义如下:
// DataType 枚举类型定义
enum DataType { FLOAT32, INT32, INT64, UINT8, UNKDTYPE };
// 获取输入 dtype 的数据大小
// 参数:dtype - PaddleDType 枚举类型
// 返回:int32 - dtype 对应的数据大小
func SizeofDataType(dtype PaddleDType) int32
代码示例:
package main
// 引入 Paddle Golang Package
import "/pathto/Paddle/go/paddle"
func main() {
println("FLOAT32 size is: ", paddle.SizeofDataType(paddle.FLOAT32)); // 4
println("INT64 size is: ", paddle.SizeofDataType(paddle.INT64)); // 8
println("INT32 size is: ", paddle.SizeofDataType(paddle.INT32)); // 4
println("UINT8 size is: ", paddle.SizeofDataType(paddle.UINT8)); // 1
}
Precision¶
Precision 设置模型的运行精度,默认值为 Precision_FLOAT32。枚举变量定义如下:
// PrecisionType 枚举类型定义
enum Precision { Precision_FLOAT32, Precision_INT8, Precision_HALF };
代码示例:
package main
// 引入 Paddle Golang Package
import "/pathto/Paddle/go/paddle"
func main() {
// 创建 AnalysisConfig 对象
config := paddle.NewAnalysisConfig()
// 启用 GPU 进行预测 - 初始化 GPU 显存 100M, Deivce_ID 为 0
config.EnableUseGpu(100, 0)
// 启用 TensorRT 进行预测加速 - FP32
config.EnableTensorRtEngine(1 << 20, 1, 3, paddle.Precision_FLOAT32, false, false)
// 启用 TensorRT 进行预测加速 - FP16
config.EnableTensorRtEngine(1 << 20, 1, 3, paddle.Precision_HALF, false, false)
// 启用 TensorRT 进行预测加速 - Int8
config.EnableTensorRtEngine(1 << 20, 1, 3, paddle.Precision_INT8, false, false)
// 通过 API 获取 TensorRT 启用结果 - true
println("Enable TensorRT is: ", config.TensorrtEngineEnabled())
}
Paddle Inference FAQ¶
1、编译报错, 且出错语句没有明显语法错误。 答:请检查使用的GCC版本,目前PaddlePaddle支持的编译器版本为GCC 4.8.2和GCC 8.2.0。
2、编译时报错No CMAKE_CUDA_COMPILER could be found。
答:编译时未找到nvcc。设置编译选项-DCMAKE_CUDA_COMPILER=nvcc所在路径,注意需要与CUDA版本保持一致。
3、运行时报错RuntimeError: parallel_for failed: cudaErrorNoKernelImageForDevice: no kernel image is available for execution on the device。
答:这种情况一般出现在编译和运行在不同架构的显卡上,且cmake时未指定运行时需要的CUDA架构。可以在cmake时加上 -DCUDA_ARCH_NAME=All(或者特定的架构如Turing、Volta、Pascal等),否则会使用默认值Auto,此时只会当前的CUDA架构编译。
4、运行时报错PaddleCheckError: Expected id < GetCUDADeviceCount(), but received id:0 >= GetCUDADeviceCount():0 。
答:一般原因是找不到驱动文件。请检查环境设置,需要在LD_LIBRARY_PATH中加入/usr/lib64(驱动程序libcuda.so所在的实际路径)。
5、运行时报错Error: Cannot load cudnn shared library. 。
答:请在LD_LIBRARY_PATH中加入cuDNN库的路径。
6、运行时报错libstdc++.so.6中GLIBCXX版本过低。 答:运行时链接了错误的glibc。可以通过以下两种方式解决: 1)在编译时,通过在CXXFLAGS中加入”-Wl,–rpath=/opt/compiler/gcc-8.2/lib,–dynamic-linker=/opt/compiler/gcc-8.2/lib/ld-linux-x86-64.so.2”,来保证编译产出的可执行程序链接到正确的libc.so.6/libstdc++.so.6库。 2)在运行时,将正确的glibc的路径加入到LD_LIBRARY_PATH中。
7、使用CPU预测,开启MKLDNN时内存异常上涨。
答:请检查是否使用了变长输入,此时可以使用接口config.set_mkldnn_cache_capacity(capacity)接口,设置不同shape的缓存数,以防止缓存太多的优化信息占用较大的内存空间。
8、运行时报错CUDNN_STATUS_NOT_INITIALIZED at ...。
答:请检查运行时链接的cuDNN版本和编译预测库使用的cuDNN版本是否一致。
9、运行时报错OMP: Error #100 Fatal system error detected。
答:OMP的问题,可参考链接 https://unix.stackexchange.com/questions/302683/omp-error-bash-on-ubuntu-on-windows
10、初始化阶段报错Program terminated with signal SIGILL, Illegal instruction
答:请检查下是否在不支持AVX的机器上使用了AVX的预测库。
11、运行时报错PaddleCheckError: an illegal memory access was encounted at xxx
答:请检查输入Tensor 是否存在指针越界。
12、Predictor是否有Profile工具。
答: config.EnableProfile()可以打印op耗时,请参考API文档-Profile设置。
13、同一个模型的推理耗时不稳定。 答:请按以下方向排查: 1)硬件资源(CPU、GPU等)是否没有他人抢占。 2)输入是否一致,某些模型推理时间跟输入有关,比如检测模型的候选框数量。 3)使用TensorRT时,初始的优化阶段比较耗时,可以通过少量数据warm up的方式解决。
14、ZeroCopyTensor和ZeroCopyRun的相关文档。 答:ZeroCopyTensor虽然在模型推理时不再有数据拷贝,但是构造时需要用户将数据拷贝至ZeroCopyTensor中,为避免歧义,该接口2.0rc1+版本已经隐藏,当前接口请参考API文档
15、在JetPack 4.4环境的Jetson开发套件上运行带卷积的模型报错terminate called after throwing an instance of 'std::logic_error' what(): basic_string::_M_construct null not valid。
答:这个是cuDNN 8.0在SM_72下的bug,在运行cudnnConvolutionBiasActivationForward的时候会出错,见https://forums.developer.nvidia.com/t/nx-jp44-cudnn-internal-logic-error/124805。
目前有以下两种解决方案:
1)通过config.pass_builder()->DeletPass()删除如下PASS:conv_elementwise_add_act_fuse_pass、conv_elementwise_add2_act_fuse_pass、conv_elementwise_add_fuse_pass, 来避免预测期间进行conv + bias + activation的融合。
2)将cuDNN 8.0降级为cuDNN 7.6。
16、运行时报错Expected static_cast<size_t>(col) < feed_list.size(), but received static_cast<size_t>(col):23 >= feed_list.size():0。
答:在2.0 rc1之前的版本,用户使用ZeroCopyTensor和ZeroCopyRun接口时,需要设置config.SwitchUseFeedFetchOps(false),后续版本已经隐藏ZeroCopyTensor的设计,无需手动设置。
17、如何开启CPU预测的多线程加速。
答:请使用config.EnableMKLDNN()和config.SetCpuMathLibraryNumThreads(),请参考API文档-CPU预测。